







动机及初步结果
本想使用Visual-RFT框架进行Qwen2-VL-2B模型关于细分类任务的GRPO训练,但是现有两张1080ti一直OOM,根本无法验证模型效果,于是换到SWIFT框架下进行lora-grpo训练。但是两张1080ti也只能训练逐样本响应为2的情况,这对grpo这种训练机制来说,感觉很难学习到东西,于是上AutoDL用了两张4090显卡,简单测试了下,发现逐样本响应为6不会OOM,响应为8的时候三张3090也会OOM。
目前得到的实验结果:使用Qwen2-VL-2B-Instruct推理分类任务,数据集使用flowers 102,使用和作者相同的prompt,1232张图片成功分类数量为803,准确率为803/1232=65.2%;将响应为6训练出来的模型放在Visual-RFT框架下进行推理,执行推理任务准确率为870/1232=70.6%。
训练资源及环境
本地服务器:2*1080ti(22GB VRAM) cuda版本:12.4
AutoDL:2*4090(48GB VRAM) 3*3090(72GB VRAM) torch:2.1.0,Python:3.10,cuda:12.1,ubuntu22.04
模型训练
使用ms-swift框架下的 ./examples/train/grpo/grpo.sh 进行训练
由于Visual-RFT基于GRPO的训练方式并不支持lora,且对显存需求极大,故选择使用SWIFT框架训练;包含的任务如下:
代码下载
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
数据准备
修改Visual-RFT数据ViRFT_CLS_flower_4_shot 以满足SWIFT--dataset格式需求
参考:自定义数据集 — swift 3.3.0.dev0 文档
import pandas as pd
import json
import os
# 读取 parquet 文件
df = pd.read_parquet("./data/datasets/ViRFT_CLS_flower_4_shot/data/train-00000-of-00001.parquet")
# 存储转换后的数据
output_data = []
# 设定存储图片的目录
image_save_dir = "./data/datasets/ViRFT_CLS_flower_4_shot/data/train_classfication_flowers"
os.makedirs(image_save_dir, exist_ok=True)
for _, row in df.iterrows():
# 处理图片
image_data = row["image"]["bytes"]
image_filename = f"{image_save_dir}/image_{_}.png"
with open(image_filename, "wb") as img_file:
img_file.write(image_data)
# 处理文本数据
user_query = row["problem"]
assistant_response = row["solution"]
# 构造 JSON 格式(GRPO 兼容)
formatted_entry = {
"messages": [
{"role": "user", "content": user_query},
{"role": "assistant", "content": assistant_response}
],
"images": [image_filename], # 可选: 也可以用 base64
"solution": assistant_response # 额外字段,GRPO 需要透传
}
output_data.append(formatted_entry)
# 保存为 JSON
output_json_path = "./data/datasets/ViRFT_CLS_flower_4_shot/data/train_classfication_flowers.json"
with open(output_json_path, "w", encoding="utf-8") as json_file:
json.dump(output_data, json_file, indent=4, ensure_ascii=False)
print(f"GRPO 兼容数据转换完成!数据已保存至 {output_json_path}")
最终train_classfication_flowers.json内容为:
[
{
"messages": [
{
"role": "user",
"content": "This is an image containing a plant. Please identify the species of the plant based on the image.\nOutput the thinking process in <think> </think> and final answer in <answer> </answer> tags.The output answer format should be as follows:\n<think> ... </think> <answer>species name</answer>\nPlease strictly follow the format."
},
{
"role": "assistant",
"content": "<answer>mallow</answer>"
}
],
"images": [
"./data/datasets/ViRFT_CLS_flower_4_shot/converted_images/image_0.png"
],
"solution": "<answer>mallow</answer>"
},
...
{
}
]
数据下载
已将转换后的数据及json文件上传至hugging face
git lfs install
git clone https://huggingface.co/datasets/dre4moO/flowers_102
此处还需要简单修改下路径
修改Accuracy Reward
参考:多模态GRPO完整实验流程 — swift 3.3.0.dev0 文档
--reward_funcs accuracy format \:本次训练使用的奖励函数有两个,一个是 Deepseek-R1 中提到的格式奖励函数,另一是准确性奖励函数。前者已经在swift中内置,通过 --reward_funcs format 可以直接使用,而后者需要我们自己定义,在这里我们使用 external_plugin 的方式定义准确性奖励函数,将代码放在swift/examples/train/grpo/plugin/plugin.py中,并在grpo.sh文件中增加启动参数:--external_plugins examples/train/grpo/plugin/plugin.py \以及--reward_funcs external_class_acc format \。
在这里,奖励函数的输入包括completions和solution两个字段,分别表示模型生成的文本和真值。每个都是list,支持多个completion同时计算。注意,在这里,solution字段是数据集中定义的字段透传而来,如果有任务上的变动,可以分别对数据集和奖励函数做对应的改变即可。
在./examples/train/grpo/plugin/plugin.py中增加以下内容
class ClassficationAccuracyORM(ORM):
def __call__(self, completions, solution, **kwargs) -> List[float]:
'''
Reward function that checks if the completion is correct using either symbol verification or exact string matching .
'''
print("----->ClassficationAccuracyORM completions:", completions)
print("----->ClassficationAccuracyORM solution:", solution)
from math_verify import parse, verify
rewards = []
for content, sol in zip(completions, solution):
reward = 0.0
try:
answer = parse(content)
if float(verify(answer, parse(sol))) > 0:
reward = 1.0
except Exception:
pass
if reward == 0.0:
try:
sol_match = re.search(r'<answer>(.*?)</answer>', sol)
ground_truth = sol_match.group(1).strip() if sol_match else sol.strip()
content_match = re.search(r'<answer>(.*?)</answer>', content)
student_answer = content_match.group(1).strip() if content_match else content_match.strip()
ground_truth = ground_truth.replace(' ','').replace('_','').lower()
student_answer = student_answer.replace(' ','').replace('_','').lower()
if ground_truth in student_answer or student_answer in ground_truth:
reward = 1.0
except Exception:
pass
print("----->ClassficationAccuracyORM reward:", reward)
rewards.append(reward)
return rewards
orms['external_class_acc'] = ClassficationAccuracyORM
训练
修改./examples/train/grpo/grpo.sh
# pip install math_verify # reward function
# pip install -U trl
# GPU memory: 80GiB
# You can set `--reward_model` to use a reward model to provide rewards.
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128
export NCCL_P2P_DISABLE=1
export NCCL_IB_DISABLE=1
export SWIFTLIB_USE_FLASH_ATTENTION=1
CUDA_VISIBLE_DEVICES=0,1 \
NPROC_PER_NODE=2 \
swift rlhf \
--rlhf_type grpo \
--model Qwen/Qwen2-VL-2B-Instruct \
--external_plugins examples/train/grpo/plugin/plugin.py \
--reward_funcs external_class_acc format \
--train_type lora \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--torch_dtype bfloat16 \
--dataset './data/datasets/ViRFT_CLS_flower_4_shot/data/train_classfication_flowers.json' \
--max_completion_length 1024 \
--num_train_epochs 1 \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 8 \
--per_device_eval_batch_size 8 \
--learning_rate 1e-5 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 1024 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--dataset_num_proc 4 \
--num_generations 8 \
--temperature 0.9 \
--system 'examples/train/grpo/prompt.txt' \
--log_completions true \
--async_generate false \
--gradient_checkpointing true
bash examples/train/grpo/grpo.sh
训练结束,得到chekpoint-404/
实验结果
准确率奖励函数并没有明显的提升,看了一下每一个样本的响应,发现有个影响准确率判别的因素是:数据集中的花朵名词部分为学名、部分为俗称,而样本响应给出的答案有时会给出两个名称,有时响应都给出学名,就比如Helianthus annuus是向日葵的学名,而预设的solution只包含sunflower这么个答案,个人认为这在一定程度上会影响模型的学习效率。此外,由于样本量过于小,可能需要多训练几个epoch才会有明显的提升,这个需要后续的实验才能验证,也欢迎路过的大佬指出原因给些建议。
'<think>To identify the species of the sunflower, I will observe the number of petals and the structure of the flower. The flower in the image has multiple bright yellow petals arranged in a symmetrical pattern. The central disc features an orange and yellow pattern, which is characteristic of sunflowers. Additionally, sunflowers typically have a yellow disk with orange and white lines around it. The petals are long and slender, and the flower is part of a field of sunflowers. Therefore, the species of the sunflower in the image is Helianthus annuus.</think> <answer>Helianthus annuus</answer>',
'<think> The image shows a large sunflower with a yellow center and bright yellow petals. Sunflowers are known for their large, showy blossoms and are often found in fields. I will identify the species based on the characteristics of the sunflower in the image.</think> <answer>Helianthus annuus</answer>']
2*1080ti(22GB VRAM) num_generations 6:
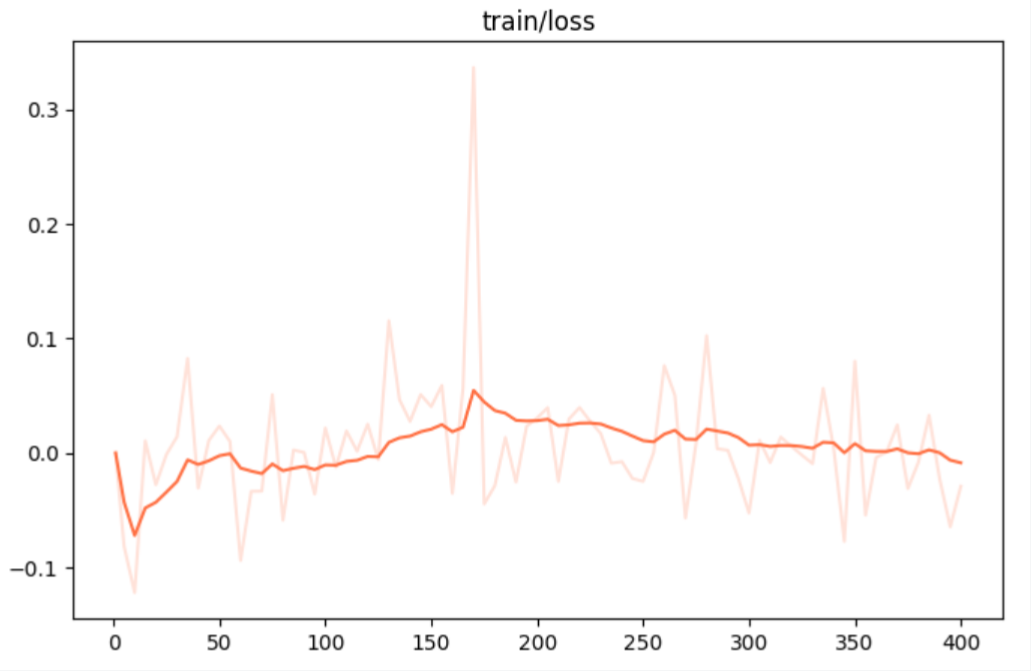 图1 损失函数 图1 损失函数
|
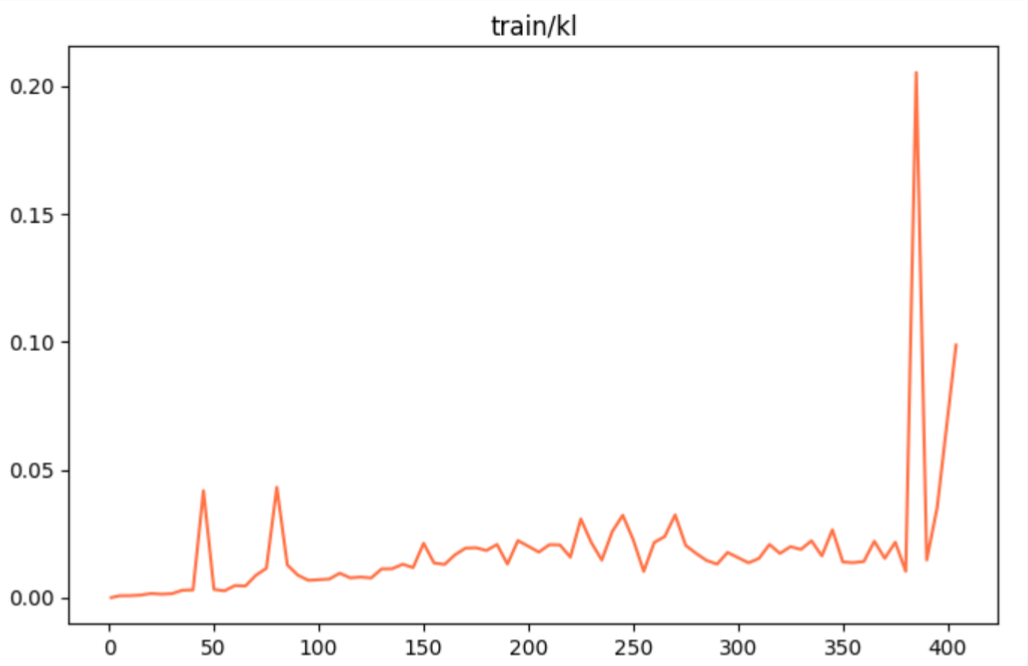 图2 kl散度 图2 kl散度
|
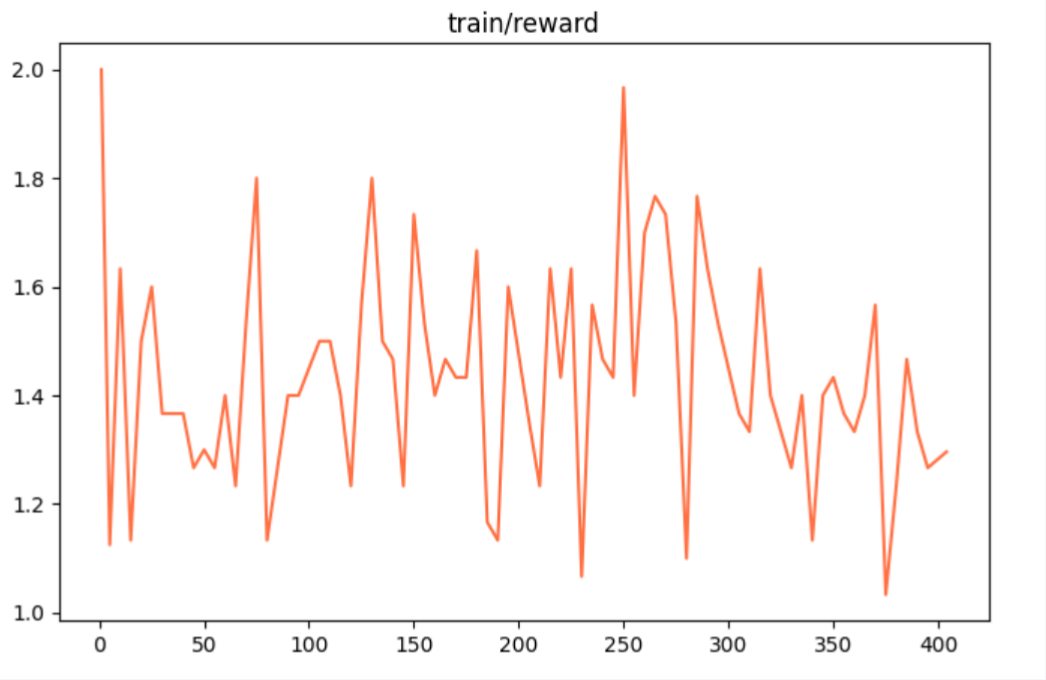 图3 奖励函数系数 图3 奖励函数系数
|
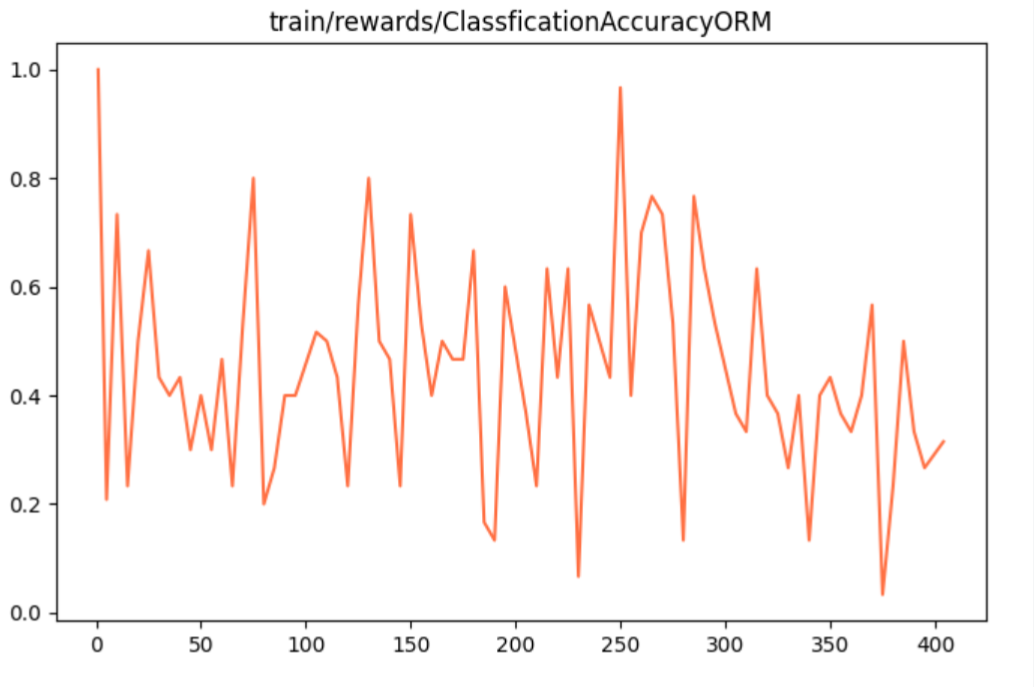 图4 准确率奖励系数 图4 准确率奖励系数
|
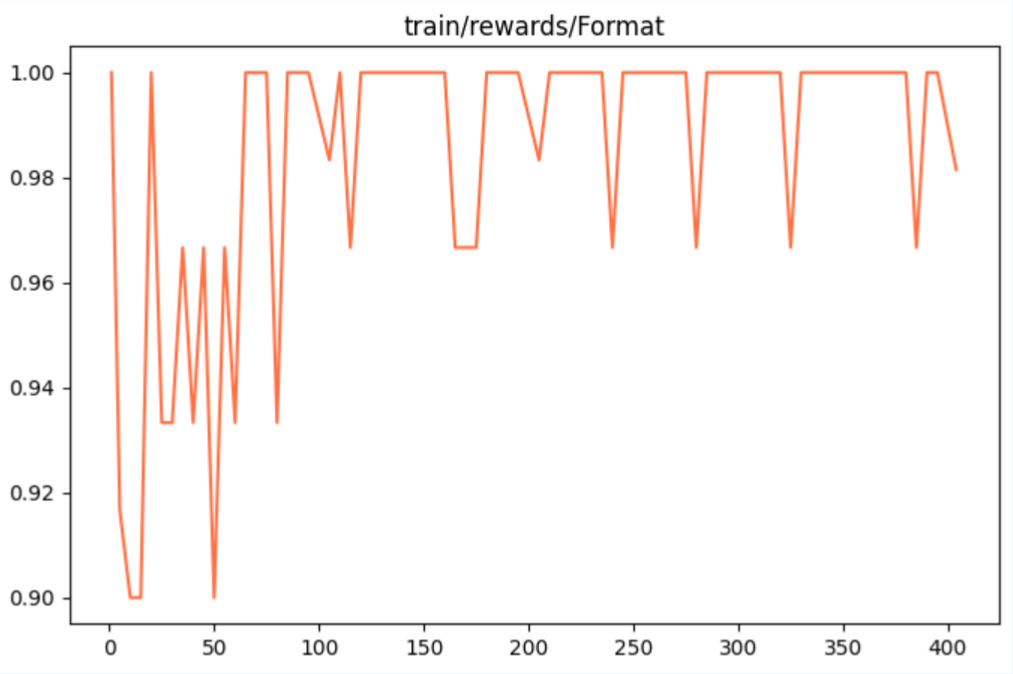 图5 格式奖励系数 图5 格式奖励系数
|
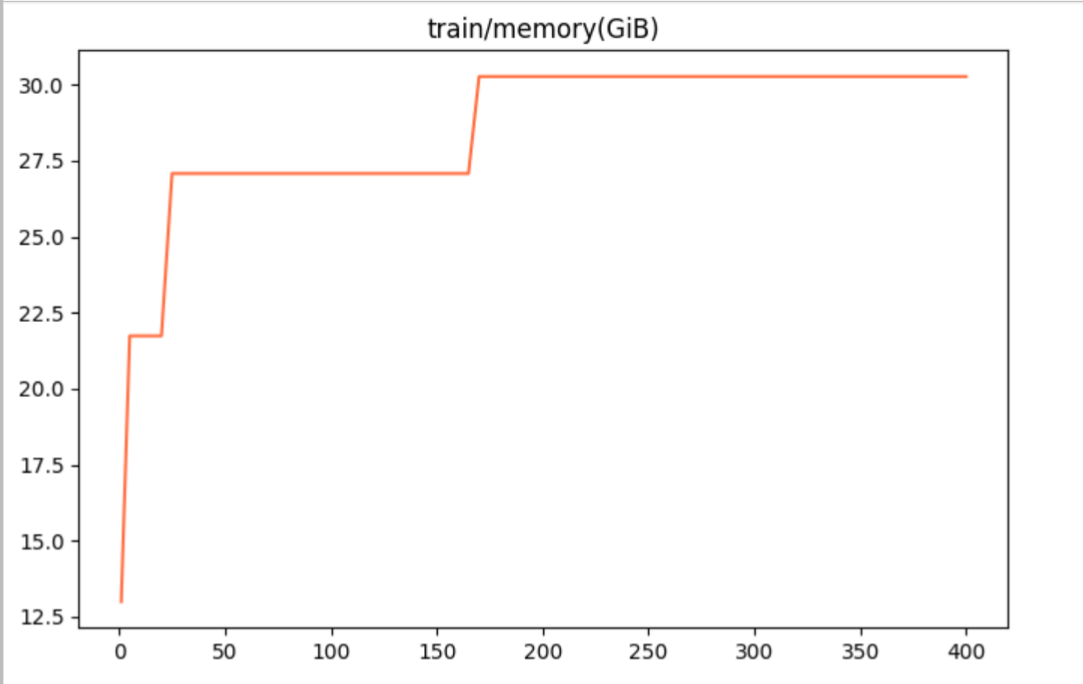 图6 显存占用 图6 显存占用
|
num_generations 8:
正在尝试用4张24GB VRAM显卡训练,但AutoDL的显卡真的很难租。
导出模型
因为使用lora训练,最终的checkpoint文件只包含LoRA适配器的增量权重,Qwen2-VL-2B-Instruct的完整权重仍然存放在预训练模型中,所以需要让LoRA的增量参数合并回主模型,才变得完整且可推理。
此处 --adapters 设置参数为训练生成的最后一个 checkpoint 文件夹
# Since `output/vx-xxx/checkpoint-xxx` is trained by swift and contains an `args.json` file,
# there is no need to explicitly set `--model`, `--system`, etc., as they will be automatically read.
swift export \
--adapters output/v8-20250326-121353/checkpoint-404 \
--merge_lora true
bash examples/export/merge_lora.sh
模型推理
修改.pth文件图片路径
Visual-RFT在./classfication/val_data中给出的验证集路径无法直接使用,需要读取文件后并修改
import torch
path = "./val_data/oxford_flowers.pth"
path_ = "./val_data/oxford_flowers_.pth"
data = torch.load(path)
old_prefix = "/mnt/petrelfs/liuziyu/LLM_Memory/SimplyRetrieve/CLIP-Cls/data/oxford_flowers/jpg/"
new_prefix = "/home/aiteam/Documents/VLM/Visual-RFT-main/dataset/oxford_flowers/jpg/"
if isinstance(data, list):
for item in data:
item_ = {}
if isinstance(item, dict):
for key, value in item.items():
if key.startswith(old_prefix) and isinstance(key, str):
new_key = key.replace(old_prefix, new_prefix, 1)
item_[new_key] = value
item.clear()
item.update(item_)
torch.save(data, path_)
随后更改中model_path和question的内容,此处参考的是Reproduce the result of Flower102 · Issue #112 · Liuziyu77/Visual-RFT
question = (
"This is an image containing an plant. Please identify the species of the plant based on the image.\n"
"Output the thinking process in <think> </think> and final answer in <answer> </answer> tags."
"The output answer format should be as follows:\n"
"<think> ... </think> <answer>species name</answer>\n"
"Please strictly follow the format."
)
最后的在1232张图片成功分类数量为870,准确率为803/1232=65.2%,准确率相较于Qwen2-VL-2B的65.2%提升了5%。
后续尝试
- 更多显存资源下更多响应的训练效果;
- 多个epoch对训练结果的影响;
- 两图输入情况下做类别一致判别任务的能力。
参考:
AutoDL使用教程:1)创建实例 2)配置环境+上传数据 3)PyCharm2021.3专业版下载安装与远程连接完整步骤 4)实时查看tensorboard曲线情况-CSDN博客
多模态GRPO完整实验流程 — swift 3.3.0.dev0 文档
Reproduce the result of Flower102 · Issue #112 · Liuziyu77/Visual-RFT


















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









