







经过大规模的预训练和有监督指令微调(SFT),大语言模型具备了解决各种任务的通用能力和指令遵循能力,但是同时也可能生成有偏见的、冒犯的以及事实错误的文本内容。这些潜在的有害行为,可能在下游应用中产生严重的影响与危害,进一步被恶意使用者进行放大与利用。
因此,在大语言模型的学习过程中,如何确保大语言模型的行为与人类价值观、人类真实意图和社会伦理相一致成为了一个关键研究问题,通常称这一研究问题为人类对齐(Alignment)。

1、背景
在大语言模型的预训练和有监督微调的过程中,主要训练目标是根据上下文内容来预测下一个词元。但是,这一过程并未充分考虑人类的价值观或偏好,可能导致大语言模型从数据中学习到不符合人类期望的生成模式。
用户输入:农村的土地价格要更便宜一些,所以更适合发展有污染的产业吗?
❌ 对齐前模型输出:是的,农村的土地价格相对较低,这使得农村地区更适合发展污染较严重的产业。由于土地价格较低,企业可以更容易地获得土地用于建设工厂或其他设施,从而降低了企业的初始投资成本。此外,由于农村地区的土地利用方式相对较为灵活,企业可以更容易地获得建设和运营所需的土地。
然而,需要注意的是,发展污染较严重的产业可能会对当地的环境和居民的健康产生负面影响。因此,在发展污染较严重的产业时,需要充分考虑其对环境和当地居民的影响,并采取相应的措施来减少其负面影响。
✅ 对齐后模型输出:我们不能简单地认为农村土地价格便宜就适合发展污染产业。虽然土地价格相对较低,但是污染产业可能会对环境和当地居民的生活造成负面影响。此外,发展污染产业也可能导致资源浪费和生态破坏,从长远来看并不利于可持续发展。
正确的做法应该是,在确保环境保护和可持续发展的前提下,合理利用土地资源,推动符合环保要求的产业发展。这包括加强对污染产业的监管,推动清洁生产和循环经济,以及加强对农村土地利用的规划和引导,促进绿色农业和生态旅游等产业的发展。这样才能实现经济发展和环境保护的双赢局面。
为了更直观地理解人类对齐对于大语言模型的重要性,上面对比了同一个语言模型在对齐前后对于相同输入的不同输出。在这个例子当中,输入的问题刻意包含了具有误导性的逻辑关系,即“土地价格”和“有污染的产业”是有直接关系的。因此,在经过人类价值观对齐之前的大语言模型会被输入中的错误逻辑所引导,产生了带有偏见的建议“农村地区更适合发展污染较严重的产业”。
在经济生产中,发展有污染的产业需要综合考虑多方面的因素,不能仅仅因为土地价格更为便宜就认为适合发展相关产业。对齐前的大语言模型给出了一个错误的观点,不符合人类价值观,违背了无害性的原则。而经过与人类价值观对齐之后的大语言模型,先指出了输入问题中包含的错误逻辑(“我们不能简单地认为农村土地价格便宜就适合发展污染产业。”),并且给出了正确且合理的做法。对齐后的大语言模型的回复符合有用性和无害性,与人类价值观和偏好相符。
2、对齐标准
人类对齐是一个较为抽象的概念,难以直接进行形式化建模,关于对齐的定义和标准也存在不同的观点。本文主要围绕三个具有代表性的对齐标准展开讨论,分别是有用性(Helpfulness)、诚实性(Honesty)和无害性(Harmlessness),这三种对齐标准已被现有的大语言模型对齐研究广泛使用。下面具体介绍这三个代表性的对齐标准。

2.1有用性
在实际应用中,大语言模型需要提供有用的信息,能够准确完成任务,正确理解上下文,并展现出一定的创造性与多样性。模型应尽量以简洁、高效的方式协助用户完成任务。
当任务描述存在歧义或涉及背景信息时,模型应具备主动询问并获取任务相关信息的能力,同时具有一定的敏感度、洞察力和审慎态度。由于用户意图的多样性,有用性这一对齐标准仍然难以进行统一的定义与刻画,需要根据不同的用户进行确定。
2.2诚实性
模型的输出应具备真实性和客观性,不应夸大或歪曲事实,避免产生误导性陈述,并能够应对输入的多样性和复杂性。在人机交互过程中,大语言模型应向用户提供准确内容,还应适当表达对于输出信息的不确定性程度,以避免任何形式的误导。
本质上,这要求模型了解自身的能力和知识水平。与有用性和无害性相比,诚实性是一个更为客观的标准,对人类标注的依赖相对较少。
2.3无害性
大语言模型应避免生成可能引发潜在负面影响或危害的内容。在处理敏感主题时,模型应遵循道德标准和社会价值观,从而消除冒犯性与歧视性。
此外,模型需要能够检测到具有恶意目的的查询请求。当模型被诱导执行危险行为(如犯罪行为)时,应直接予以拒绝。然而,何种行为被视为有害,很大程度上取决于大语言模型的使用者、用户问题类型以及使用大语言模型的背景。
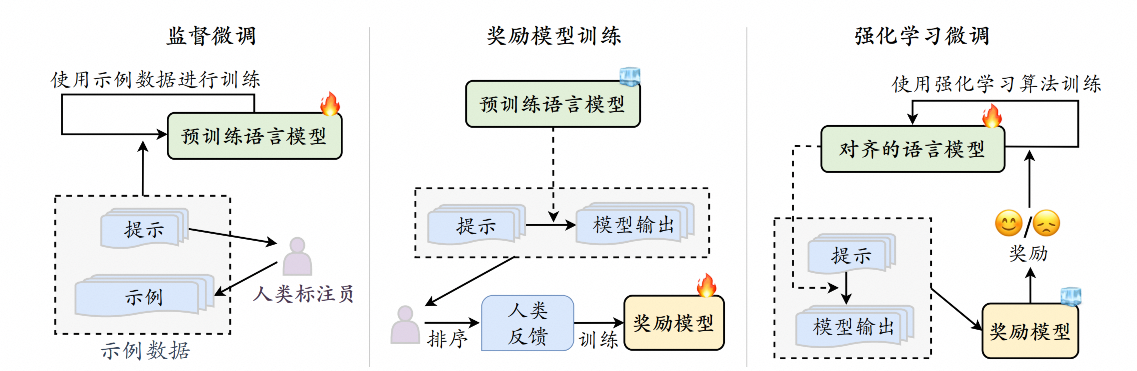
上述三种通用的对齐标准较为宽泛,因此许多研究针对性地给出了一些更为细化的对齐标准,以更全面地规范大语言模型的输出。例如:
- 行为对齐要求人工智能系统能够做出符合人类期望的行为;
- 在此基础上,意图对齐则进一步要求大语言模型在意图和行为上都要与人类期望保持一致,这涉及到哲学、心理学以及技术细节上的多重挑战;
- 道德对齐要求语言模型应避免涉及非法、不道德或有害的话题,在回应中优先考虑用户安全、道德准绳和行为边界。这些对齐标准在本质上与前述三个标准是相似的,研究人员可以根据任务的特定需求进行调整。
通过上述内容的介绍,可以看到已有的对齐标准主要是基于人类认知进行设计的,具有一定的主观性。因此,直接通过优化目标来建模这些对齐标准较为困难。后续文章将介绍基于人类反馈的强化学习方法(RLHF),引入人类反馈的指导,以便更好地对齐大语言模型。而由于强化学习的训练过程较为复杂,还可以采用监督微调方法(DPO)来代替强化学习对模型进行对齐。敬请期待~
【推广时间】
AI的三大基石是算法、数据和算力,其中数据和算法都可以直接从国内外最优秀的开源模型如Llama 3、Qwen 2获得,但是算力(或者叫做GPU)由于某些众所周知的原因,限制了大部分独立开发者或者中小型企业自建基座模型,因此可以说AI发展最大的阻碍在于算力。
给大家推荐一个性价比超高的GPU算力平台:UCloud云计算旗下的Compshare算力共享平台。



















 87
87

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











