







1. 什么是Netron?
Netron 是一个开源的神经网络、深度学习和机器学习模型可视化工具,主要用于以图形化方式展示模型的结构、参数及内部连接关系。以下是其核心特点与功能:
-
核心功能
- 模型可视化:支持加载并展示多种主流框架的模型文件(如ONNX、TensorFlow、PyTorch、Keras、Caffe等),通过节点连接图直观呈现各层(如卷积层、全连接层)的层级关系。
- 参数与形状分析:点击某一层可查看权重、偏置、激活函数等参数,以及输入/输出张量的维度(如
float32[1,3,224,224]),辅助调试数据流问题。 - 跨平台支持:提供桌面应用(Windows/macOS/Linux)和在线版本(Netron Web),支持本地文件或直接拖拽模型到浏览器中分析。
-
技术背景
- 由微软工程师 Lutz Roeder 开发,以开源形式维护,强调对多框架兼容性。
- 特别适配 ONNX 格式,可作为中间工具验证模型转换后的结构完整性(如动态维度、算子兼容性)。
-
典型使用场景
- 模型调试:通过可视化快速定位结构错误或张量维度不匹配问题。
- 跨框架协作:将不同框架的模型(如PyTorch/TensorFlow)转换为ONNX后,统一通过Netron分析。
- 教学与展示:导出PNG/SVG格式的模型结构图,用于技术文档或报告。
Netron凭借其广泛的格式支持、直观的交互界面和开源特性,成为开发者理解模型结构、验证转换结果及优化部署流程的重要工具。
2. 什么是ONNX模型?
ONNX(Open Neural Network Exchange,开放神经网络交换)是一种用于表示机器学习和深度学习模型的开放文件格式,旨在实现跨框架的模型互操作性与高效部署。以下是其核心要点:
-
定义与目标
ONNX通过统一的中间表示(IR)描述模型的计算图、参数及元数据,使得不同框架(如PyTorch、TensorFlow、MXNet等)训练的模型可以相互转换和共享。其核心目标是消除框架间的壁垒,简化从研发到生产的流程。 -
核心功能
- 跨框架兼容:支持将模型从任一框架导出为ONNX格式,并导入其他支持ONNX的工具或平台(如TensorRT、ONNX Runtime)。
- 结构与参数存储:完整保存模型的网络结构(如层定义、连接关系)和训练参数(权重、偏置),便于复现与部署。
- 部署优化:结合ONNX Runtime等推理引擎,可在云、边缘设备或移动端实现高性能推理,支持动态形状输入和硬件加速。
-
应用场景
- 模型转换:例如将PyTorch模型转为ONNX后,通过TensorRT加速GPU推理。
- 生产环境部署:ONNX Runtime优化了模型在不同硬件上的执行效率,减少框架依赖。
- 可视化分析:工具如Netron可解析ONNX模型的层级结构、张量维度及参数细节。
ONNX通过标准化模型表示,解决了不同框架间的兼容性问题,成为连接模型训练与生产部署的关键桥梁。
3. 如何将不同框架的神经网络模型转换为ONNX格式以兼容Netron分析?
以下是不同框架模型转换为ONNX格式的步骤及注意事项:
1. PyTorch模型转ONNX
步骤:
import torch
import torchvision
# 加载预训练模型
model = torchvision.models.resnet18(pretrained=True)
model.eval()
# 定义输入张量(需与实际输入形状一致)
dummy_input = torch.randn(1, 3, 224, 224)
# 导出ONNX模型
torch.onnx.export(
model,
dummy_input,
"model.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}} # 支持动态batch
)
注意事项:
- 确保模型处于
eval()模式,避免训练时的Dropout/BatchNorm影响转换。 - 使用
dynamic_axes参数可定义动态输入维度(如变长序列)。
2. TensorFlow模型转ONNX
步骤:
- 安装工具:
pip install tensorflow-onnx - 命令行转换(适用于
.pb模型):python -m tf2onnx.convert \ --graphdef model.pb \ --output model.onnx \ --inputs input_node_name \ --outputs output_node_name- 需替换
input_node_name和output_node_name为实际输入输出节点名。 - 若模型为SavedModel格式,使用
--saved-model参数。
- 需替换
3. Keras模型转ONNX
步骤:
- 先将Keras模型保存为TensorFlow SavedModel格式:
model.save("saved_model/") - 使用
tensorflow-onnx工具转换:python -m tf2onnx.convert --saved-model saved_model/ --output model.onnx
4. 其他框架(如Caffe、MXNet)
- 通用方法:通过ONNX官方提供的转换工具或中间格式(如
.prototxt)间接转换。 - 复杂模型:若含自定义层,需手动实现ONNX算子映射或简化模型结构。
验证与可视化
- Netron验证:
转换后直接用Netron打开.onnx文件,检查层结构、输入输出形状是否完整。 - 工具检查:
使用ONNX Runtime验证模型有效性:import onnxruntime as ort ort.InferenceSession("model.onnx")
注意事项
- 版本兼容性:
- TensorFlow模型转换需与训练时的版本一致,避免节点名称差异。
- PyTorch转换时,动态维度需显式声明,否则可能因静态形状导致推理错误。
- 简化结构:
YOLOv5等复杂模型需导出为ONNX格式后,Netron才能显示完整结构(直接加载.pt文件可能不完整)。
通过上述步骤,可确保模型转换为ONNX后兼容Netron分析,同时提升跨框架部署的灵活性。
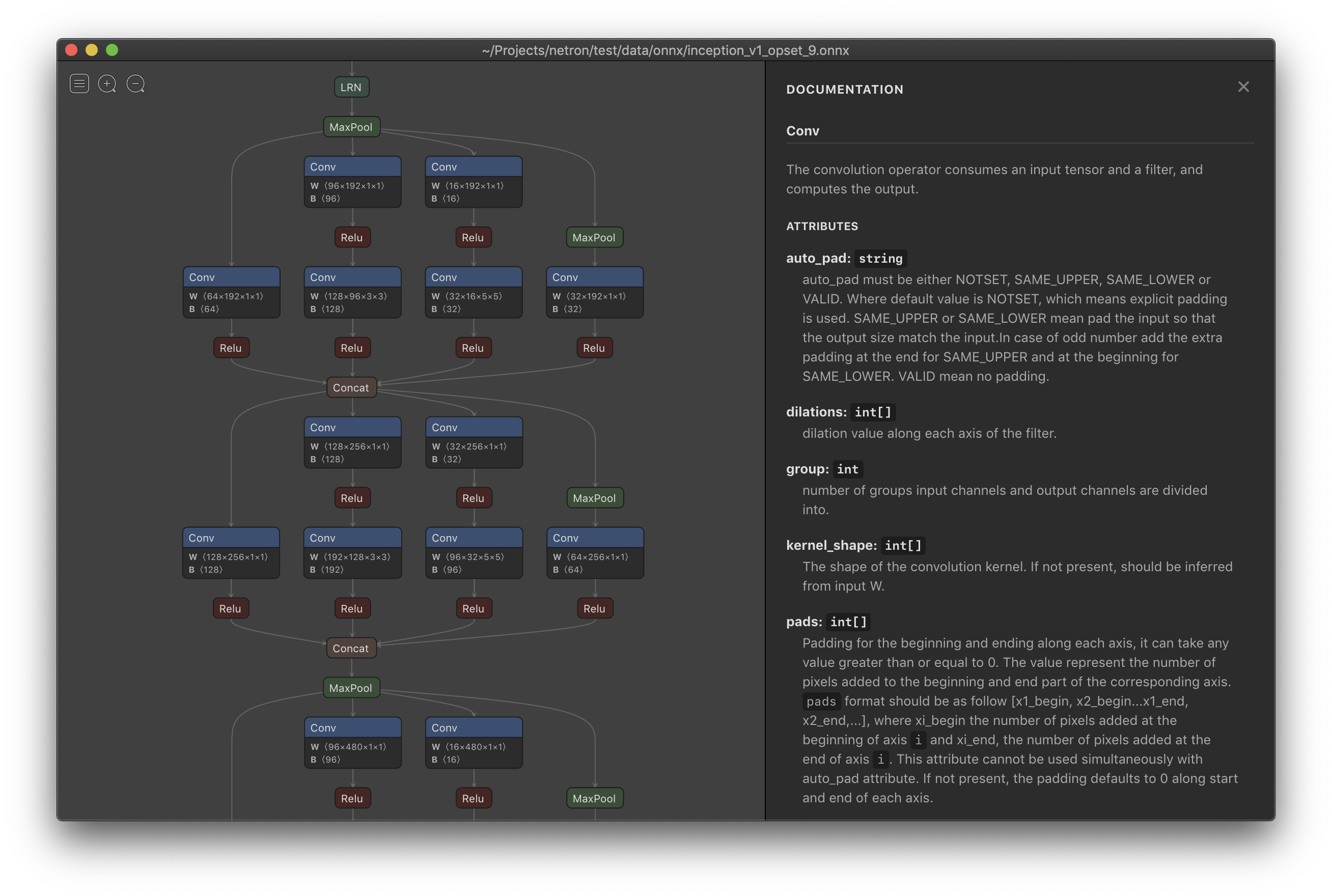
4. 如何使用Netron工具对ONNX模型进行详细的可视化分析?
以下是使用Netron对ONNX模型进行详细可视化分析的步骤及关键功能说明:
1. 加载ONNX模型
- 本地加载:
启动Netron后,点击「Open File」选择.onnx文件;或通过命令行直接启动:
支持拖拽文件到界面(适用于桌面版)。netron model.onnx - 在线工具:
访问Netron Web,直接拖拽模型文件到浏览器中。
2. 分析模型结构
- 层级关系可视化:
以节点连接图展示模型各层(如卷积层、全连接层),箭头表示数据流动方向。- 双击节点可展开子结构(如残差块)。
- 参数详情查看:
点击某一层,右侧面板显示权重(weights)、偏置(bias)、激活函数(如ReLU)等参数。 - 输入输出形状:
每层输入/输出的张量维度(如float32[1,3,224,224])清晰标注,辅助调试数据流问题。
3. 动态维度与节点搜索
- 动态轴分析:
若模型包含动态维度(如batch_size),Netron会标注为符号(如?或batch_size),需结合导出时的dynamic_axes参数验证。 - 快速定位节点:
使用快捷键(如Ctrl+F)搜索层名称(如Conv_0),或通过左侧图层面板筛选特定类型层(如所有Conv层)。
4. 导出与共享分析结果
- 导出可视化图像:
支持将模型结构导出为PNG/SVG格式,便于报告或文档中展示。 - 生成分享链接:
在线版可生成临时链接分享模型结构(注意隐私风险)。
5. 验证模型兼容性
- ONNX Runtime检查:
使用代码验证模型是否可被推理引擎加载:
若报错,需检查转换时的算子兼容性。import onnxruntime as ort sess = ort.InferenceSession("model.onnx") print(sess.get_inputs()[0].name) # 检查输入节点
6. 处理复杂模型问题
- 自定义层兼容性:
若模型含未注册的自定义算子,Netron可能显示为Unknown节点。需在转换时通过--opset指定更高版本或手动实现算子映射。 - 简化模型结构:
对YOLOv5等复杂模型,导出ONNX前可通过model.model[-1].export = True简化结构,确保Netron完整显示。
关键注意事项
- 版本一致性:
转换模型时,PyTorch/TensorFlow版本需与训练环境一致,避免因算子差异导致可视化异常。 - 动态输入验证:
若模型需动态输入(如变长文本),需在导出ONNX时通过dynamic_axes显式声明,否则Netron可能显示固定形状。
通过上述步骤,可充分利用Netron的层级分析、参数检查、交互操作等功能,深入理解ONNX模型的结构与行为,为优化或部署提供依据。


















 1434
1434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











