






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM
这篇论文主要介绍了一种新的高效键值(KV)缓存压缩方法,称为GEAR(高效键值缓存压缩食谱),用于大型语言模型(LLM)的近无损生成推理。随着序列长度的增加,缓存需求的增长使得LLM推理成为一个内存受限问题,严重限制了系统吞吐量。现有的方法主要依靠丢弃不重要的标记或者均匀量化所有条目,但这些方法往往会产生高近似误差来表示压缩的矩阵。自动回归解码过程进一步放大了每一步的误差,导致模型生成的重大偏差和性能下降。为了解决这一挑战,作者提出了GEAR,一个高效的KV缓存压缩框架,实现了高比例的近无损压缩。GEAR首先对大多数相似大小的条目进行量化到极低的精度。然后使用低秩矩阵来近似量化误差,并用稀疏矩阵来修正异常值条目的个别误差。通过巧妙地整合三种技术,GEAR能够充分利用它们的协同潜力。实验结果表明,与替代方案相比,GEAR实现了近无损的4位KV缓存压缩,吞吐量提高了2.38倍,同时将峰值内存大小减少了2.29倍。
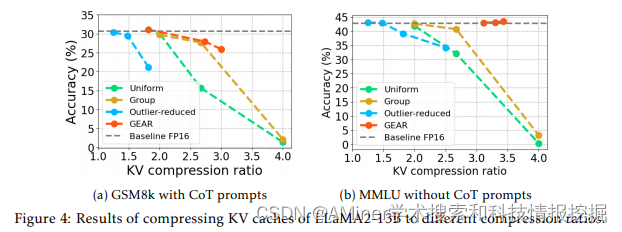
链接:https://www.aminer.cn/pub/65ee65b413fb2c6cf61ae76d/?f=cs
2.CodeUltraFeedback: An LLM-as-a-Judge Dataset for Aligning Large Language Models to Coding Preferences
这篇论文主要介绍了CodeUltraFeedback这一大规模数据集的创建,该数据集旨在评估大型语言模型(LLMs)与用户定义的编码偏好之间的对齐情况。在现有的评估基准中,通过依赖自动化指标和静态分析工具来评估用户指令和LLM输出的细微差异是困难的。这些基准未能充分评估用户指令和LLM输出的细微差异,这突显了需要大规模数据集和基准来评估LLM偏好的对齐。为了解决这个问题,作者提出了CodeUltraFeedback,这是一个包含10,000个复杂指令的偏好数据集,用于通过AI反馈调整和校准LLMs以符合编码偏好。作者使用一个包含14个不同LLM的池来生成指令的响应,然后根据这些响应与五个编码偏好的一致性使用GPT-3.5的LLM-as-a-Judge方法进行注释,从而产生数值和文本反馈。此外,作者还介绍了CODAL-Bench,一个用于评估LLM与这些编码偏好对齐情况的基准。研究结果表明,通过使用CodeUltraFeedback的AI反馈数据进行直接偏好优化(DPO)进行强化学习校准的CodeLlama-7B-Instruct模型,在CODAL-Bench上的表现优于34B LLMs,验证了CodeUltraFeedback在偏好调整方面的实用性。作者还显示,经过DPO校准的CodeLlama模型在HumanEval+上的功能性正确性比未校准的基线模型有所提高。
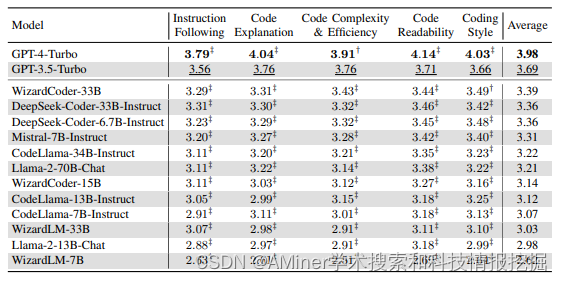
链接:https://www.aminer.cn/pub/65f3abd913fb2c6cf6612a28/?f=cs
3.RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
这篇论文主要介绍了“检索增强思维”(Retrieval Augmented Thoughts,简称RAT)的方法,该方法通过迭代修改思维链,利用信息检索显著提高了大型语言模型在长范围生成的任务中的推理和生成能力,同时大大减轻了虚构现象。具体来说,RAT方法是在生成初始的零样本思维步骤(CoT)之后,逐一修改每个思维步骤,使用与任务查询、当前和过去思维步骤相关的检索到的信息。作者将RAT应用于GPT-3.5、GPT-4和CodeLLaMA-7b,在各种长范围生成任务中的表现都有显著提高,平均相对评分提高了13.63%。
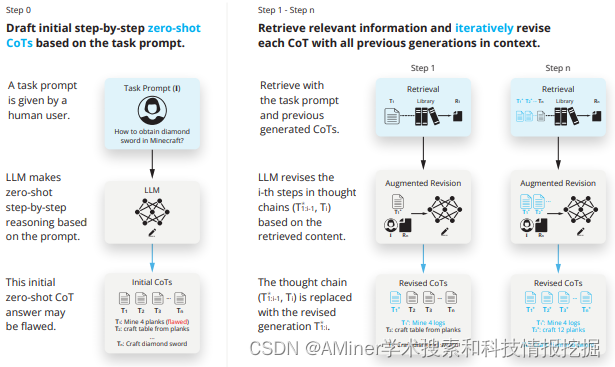
链接:https://www.aminer.cn/pub/65ee65b413fb2c6cf61ae69f/?f=cs
4.MM1: Methods, Analysis Insights from Multimodal LLM Pre-training
这篇论文讨论了如何构建表现良好的多模态大型语言模型(MLLMs)。特别是,研究了各种架构组件和数据选择的重要性。通过仔细地对图像编码器、视觉语言连接器和各种预训练数据选择进行全面的去除实验,我们确定了几项关键的设计教训。例如,我们证明,与现有的预训练结果相比,使用仔细混合的图像-标题、交替的图像-文本和纯文本数据进行大规模多模态预训练对于在多个基准测试中获得最先进(SOTA)的少样本结果至关重要。进一步,我们显示图像编码器以及图像分辨率和图像令牌计数有显著影响,而视觉语言连接器设计相对重要性较小。通过扩大提出的配方,我们构建了MM1,一个由30B参数的多模态模型组成的家族,包括密集模型和混合专家(MoE)变体,在预训练指标上处于最先进水平,并且在经过监督微调后在一系列 established 多模态基准上取得了有竞争力的性能。由于大规模预训练,MM1具有诸如增强的上下文学习和对多图像推理的促进等吸引人的特性,使得能够进行少样本链式思考提示。
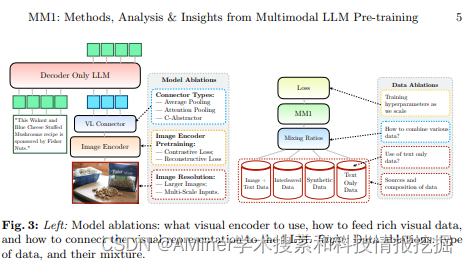
链接:https://www.aminer.cn/pub/65f3abe013fb2c6cf6613361/?f=cs
5.Logits of API-Protected LLMs Leak Proprietary Information
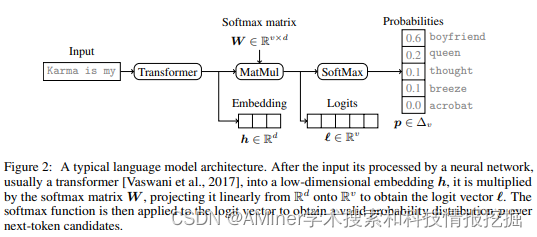
这篇论文主要介绍了一项研究,该研究指出即使在高层次API访问的保护下,大型语言模型(LLMs)的商业化也可能会泄露机密信息。研究认为,即使在模型架构上做出保守假设,通过相对较少的API查询(例如,对于OpenAI的gpt-3.5-turbo,成本不到1000美元),也有可能学习到大量的非公开信息。研究的核心观察是,大多数现代LLM受到softmax瓶颈的影响,这限制了模型输出到全输出空间的线性子空间。作者展示了这一点可以导致模型图像或模型签名,从而以低成本解锁多项功能:有效地发现LLM的隐藏大小,获取全词汇输出,检测和消除不同模型更新的歧义,甚至在给定一个完整的LLM输出时确定源LLM,甚至估计输出层参数。实证调查证明了这些方法的有效性,允许作者估计OpenAI的gpt-3.5-turbo的嵌入大小约为4,096。最后,作者讨论了LLM提供商可以如何防御这些攻击,以及如何将这些功能视为一个特性(而不是缺陷),因为这允许更大的透明度和责任感。简单来说,该论文揭示了即使在使用保护性API的情况下,大型语言模型也可能泄露其专利信息。通过这些模型的输出特性,研究者能够获取关于模型的一些重要参数信息,这可能会对模型的提供商造成潜在的风险。同时,文章也提出了相应的解决策略,并讨论了这些特性如何成为一种促进透明度和责任感的功能。
链接:https://www.aminer.cn/pub/65f3abe013fb2c6cf6613327/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









