






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.Large Language Models Produce Responses Perceived to be Empathic
大型语言模型(LLM)在许多任务上表现出了惊人的能力,包括撰写显示出共情的支持性信息。在这项研究中,研究者让这些模型对描述日常生活经验的帖子做出共情的回应,如职场情况、育儿、人际关系以及其他引发焦虑和愤怒的情况。在两个研究(N=192,202)中,研究者向人类评分者展示了由几种模型(GPT4 Turbo、Llama2和Mistral)撰写的各种回应,并让人们评价这些回应显得多么共情。研究发现,与人类撰写的回应相比,LLM生成的回应一致被认为更具共情性。语言分析还显示,这些模型以独特且可预测的“风格”写作,就其使用标点符号、表情符号和某些词语而言。这些结果突出了在共情重要的事态中使用LLM增强人类同伴支持的潜力。
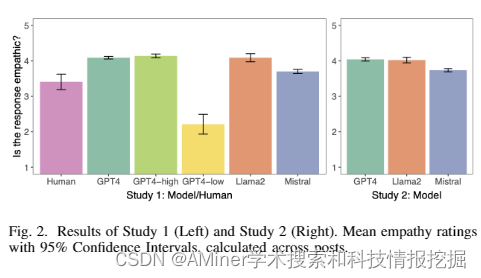
链接:https://www.aminer.cn/pub/6604cf2313fb2c6cf6b8a682/?f=cs
2.Long-form factuality in large language models
本文研究了大语言模型在生成开放话题的事实性内容时常常包含事实错误的问题。为了在开放领域内对模型的事实性进行基准测试,研究者首先使用 GPT-4 生成了 LongFact,一个包含数千个问题的问题集,覆盖了38个主题。然后,研究者提出可以使用 LLM 代理作为自动化评估器来评估长篇事实性,通过一种他们称之为 Search-Augmented Factuality Evaluator (SAFE) 的方法。SAFE 利用 LLM 将长篇回应分解为一组事实,并通过向谷歌搜索发送搜索查询,使用一个多步骤的推理过程来评估每个事实的准确性。此外,研究者还提出了扩展 F1 分数作为长篇事实性的聚合度量。为此,他们在回应中支持的事实百分比(精确度)与提供的事实百分比之间进行了平衡,后者相对于代表用户偏好回应长度的超参数(召回率)。在实验方面,研究者证明了 LLM 代理可以达到超越人类的评估性能——在一个包含 16k 个个体事实的集合上,SAFE 在72个案例中与众包的人类注释者达成一致,在76个案例中优于人类注释者,而且成本远低于人类注释者。研究者还针对四个模型家族(Gemini、GPT、Claude 和 PaLM-2)的十三种语言模型在 LongFact 上进行了基准测试,发现较大的语言模型通常能取得更好的长篇事实性。
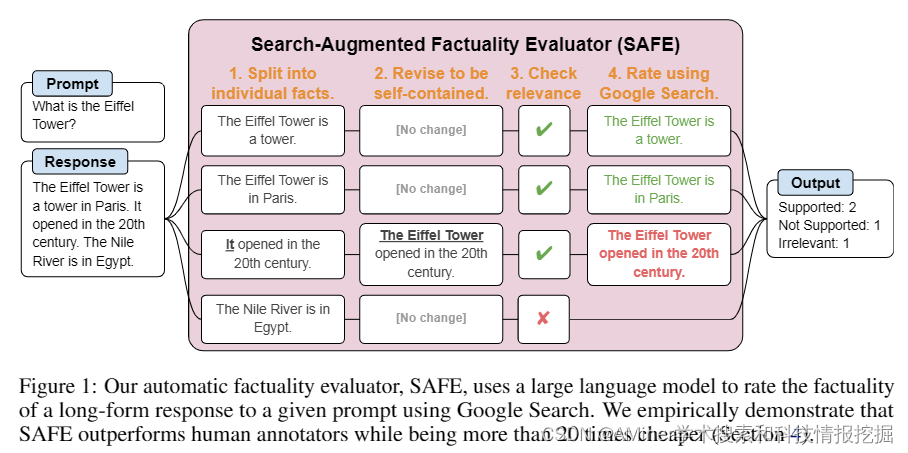
链接:https://www.aminer.cn/pub/6604cf2d13fb2c6cf6b93e0b/?f=cs
3.TwoStep: Multi-agent Task Planning using Classical Planners and Large Language Models
这篇论文介绍了一种名为TwoStep的方法,该方法结合了经典规划和大型语言模型(LLM),用于多智能体任务规划。传统规划方法如PDDL可以确保在给定初始状态的情况下,如果存在的话,会达到目标状态的动作序列。然而,PDDL定义的推理问题不能捕捉到动作执行的时态方面,例如两个域中的智能体可以同时执行一个动作,前提是它们的后置条件不会与另一个动作的前置条件发生冲突。人类专家可以将目标分解为 largely independent 的组成部分,并将每个智能体分配给这些子目标之一,以利用同时动作来加快计划步骤的执行,每个步骤仅使用单个智能体规划。相比之下,用于直接推断计划步骤的大型语言模型(LLM)不能保证执行成功,但确实利用了常识推理来组装动作序列。我们通过模拟人类直觉来结合经典规划和LLM的优势,以分解两个智能体规划目标。我们证明了基于LLM的目标分解比直接解决多智能体PDDL问题更快,同时实现的计划执行步骤比单个智能体计划少,但保留了执行成功。此外,我们还发现基于LLM的子目标近似可以达到与人类专家指定的类似的 multi-agent 执行步骤。
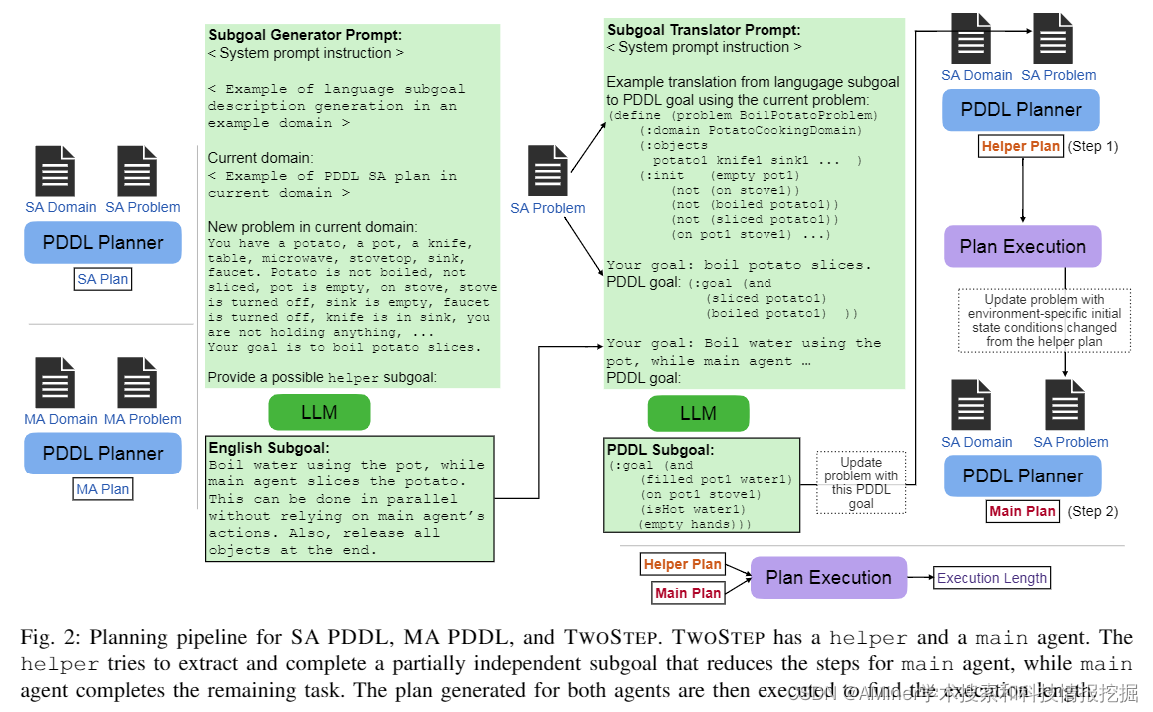
链接:https://www.aminer.cn/pub/66037e0413fb2c6cf6e7f66e/?f=cs
4.Reinforcement Learning-based Recommender Systems with Large Language Models for State Reward and Action Modeling
这篇论文探讨了基于强化学习(RL)的推荐系统,并引入了大型语言模型(LLM)来改善用户状态和动作的建模。现有的基于离线RL的序列推荐方法难以从环境中获取有效的用户反馈,因此有效建模用户状态并形成适当的推荐奖励仍然是一个挑战。为了解决这个问题,该论文利用语言理解能力,将大型语言模型适配为环境(LE),以增强基于RL的推荐系统。LE从用户-项目交互数据的一个子集中学习,从而减少了需要大量训练数据的需求,并可以通过:(i)作为状态模型产生高质量的状态来丰富用户表示,以及(ii)作为奖励模型准确捕捉对动作的细微用户偏好。此外,LE还可以生成正面的动作来补充有限的离线训练数据。该论文提出了一种LE增强(LEA)方法,通过优化监督组件和RL策略,使用增强的动作和历史用户信号,进一步提高推荐性能。实验结果表明,LEA、状态和奖励模型与最先进的RL推荐器相结合,在两个公开可用的数据集上表现良好。
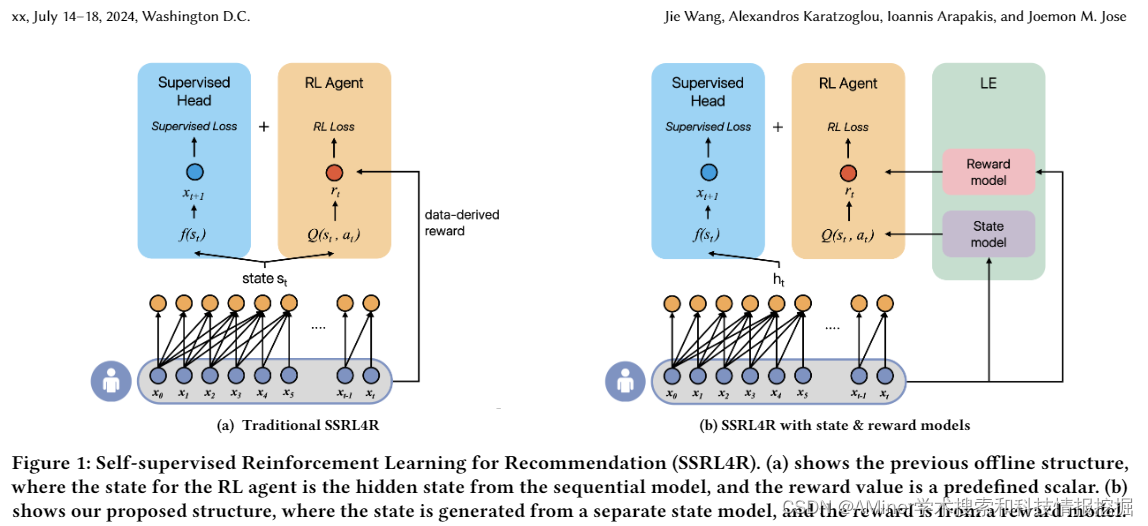
链接:https://www.aminer.cn/pub/66023bfe13fb2c6cf6aa30dd/?f=cs
5.Language Rectified Flow: Advancing Diffusion Language Generation with Probabilistic Flows
这篇论文介绍了一种名为“语言校正流动”(Language Rectified Flow)的方法,旨在通过概率流动模型改进扩散语言生成。现有的扩散语言模型能够在生成高质量样本方面表现出令人印象深刻的能力,关键在于其 iteratively denoise 的过程,即通过数千步迭代从噪声中逐渐生成清晰的文本。然而,这种方法从噪声开始并且需要大量学习步骤,这在很多自然语言处理(NLP)的实际应用中限制了其使用。本文提出的方法是对标准概率流动模型的改革。语言校正流动通过学习神经微分方程模型,在源分布和目标分布之间进行转换,从而为生成建模和领域转换提供了一种统一而有效的解决方案。从源分布出发,该方法可以快速模拟并有效减少推理时间。在三个具有挑战性的细粒度控制任务和多个高质量文本编辑任务上的实验表明,该方法始终优于其基线方法。广泛的实验和消融研究证明,该方法可以泛化,有效,并且对许多NLP任务有益。
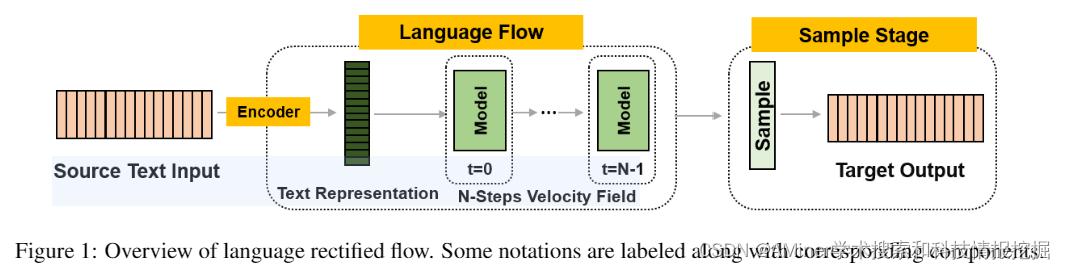
链接:https://www.aminer.cn/pub/66023b3e13fb2c6cf69cc057/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









