






大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
2022年底,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。

本周精选了5篇LLM领域的优秀论文,为了方便大家阅读,只列出了论文标题、AMiner AI综述等信息,如果感兴趣可点击查看原文,PC端数据同步(收藏即可在PC端查看),每日新论文也可登录小程序查看。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达AMiner AI页面:
https://www.aminer.cn/chat/g/explain?f=cs
1.PromptReps: Prompting Large Language Models to Generate Dense and Sparse Representations for Zero-Shot Document Retrieval
这篇论文介绍了一种新的零样本文档检索方法PromptReps。现有的利用大型语言模型(LLM)进行零样本文档排序的方法主要有两种:一种是基于提示的重新排序方法,这种方法无需进一步训练,但由于计算成本较高,只适用于重新排序少量候选文档;另一种是未监督对齐训练的密集检索方法,可以从整个语料库中检索相关文档,但需要大量成对文本数据进行对比训练。本文提出的PromptReps方法结合了两者的优点:无需训练,且可以从整个语料库中检索。该方法仅需要提示来指导LLM生成查询和文档表示,以实现有效的文档检索。具体来说,我们 prompt LLMs 用一个单词来表示给定的文本,然后使用最后一个标记的隐藏状态以及与下一个标记的预测相对应的对应概率来构建一个混合文档检索系统。该检索系统利用了由LLM生成的密集文本嵌入和稀疏词袋表示。我们在BEIR零样本文档检索数据集上的实验评估表明,这种简单的基于提示的LLM检索方法可以实现与使用大量无监督数据训练的现有最先进LLM嵌入方法相似或更高的检索效果,尤其是在使用更大型的LLM时。
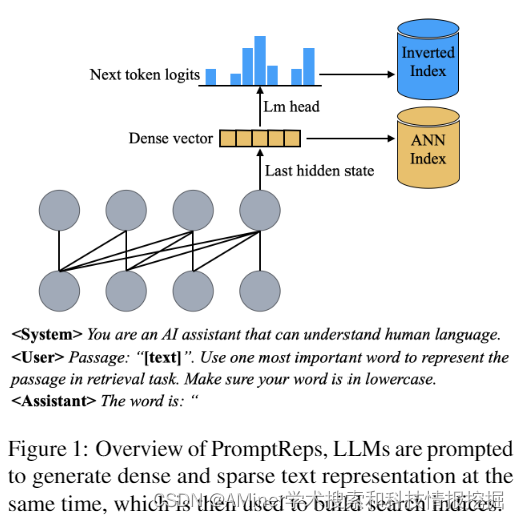
链接:https://www.aminer.cn/pub/6630514301d2a3fbfcc14472/?f=cs
2.Autonomous LLM-driven research from data to human-verifiable research papers
这篇论文探讨了完全由人工智能驱动的研究是否可行,以及是否能遵循科学的关键价值观,如透明度、可追溯性和可验证性。作者构建了一个名为data-to-paper的自动化平台,该平台通过一系列步骤引导交互式大型语言模型(LLM)完成研究过程,同时程序化地追溯信息流,允许人类的监督和互动。在自动驾驶模式下,仅提供注释数据,data-to-paper能够提出假设、设计研究计划、编写和调试分析代码、生成和解释结果,并创建完整且信息可追溯的研究论文。尽管研究的新颖性相对有限,但这个过程展示了从数据中自主生成全新定量洞察的能力。对于简单的研发目标,一个完全自动化的循环可以在大约80-90分钟内创建出摘要,在不出现重大错误的情况下复现同行评审出版物。随着复杂性的增加,人类的共同驾驶变得至关重要,以确保准确性。除了过程本身,创建的手稿也是固有的可验证的,因为信息追溯允许以编程方式链接结果、方法和数据。因此,这项工作证明了人工智能驱动加速科学研究是可能的,同时增强了透明度、可追溯性和可验证性,而不是危害它们。
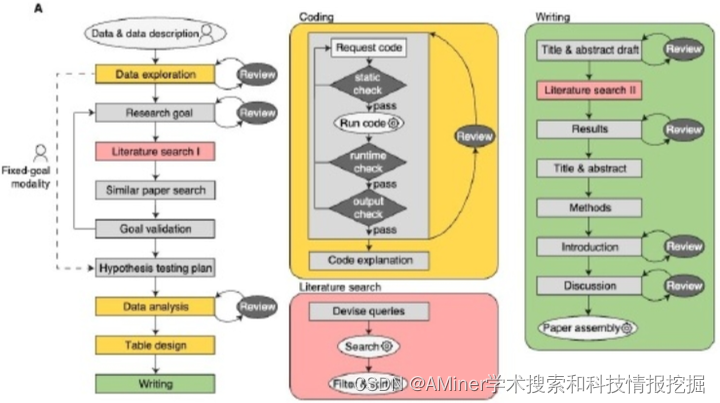
链接:https://www.aminer.cn/pub/6630513001d2a3fbfcc131d7/?f=cs
3.Benchmarking Benchmark Leakage in Large Language Models
这篇论文的摘要指出,随着预训练数据的广泛使用,基准数据集泄露现象变得越来越突出。这种现象是由于训练过程不透明和当代大型语言模型(LLM)中经常未公开包含监督数据所加剧的。这扭曲了基准的有效性,并促成了可能不公平的比较,阻碍了该领域的健康发展。为了解决这个问题,作者引入了一个检测管道,利用困惑度和N-gram准确度这两个简单且可扩展的指标,来衡量模型在基准上的预测精度,以识别潜在的数据泄露。通过分析31个在数学推理上下文的LLM,作者揭示了大量的训练甚至测试集滥用实例,导致了可能不公平的比较。这些发现促使作者提出了几项关于模型文档、基准设置和未来评估的建议。特别是,我们提出了“基准透明度卡片”,以鼓励明确记录基准使用情况,促进LLM的透明度和健康发展。我们还公开了我们的排行榜、管道实现和模型预测,以促进未来的研究。
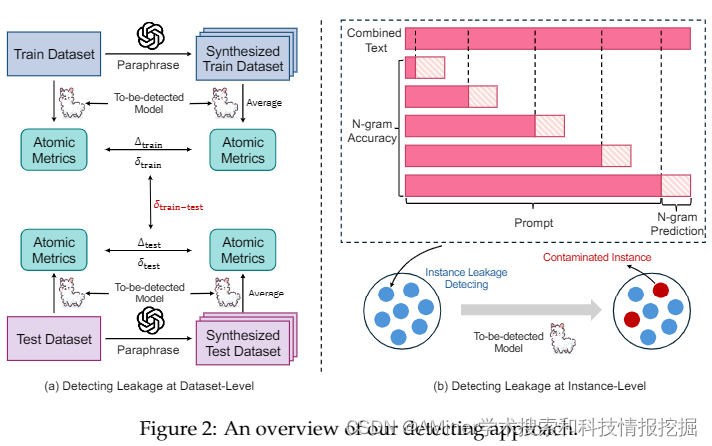
链接:https://www.aminer.cn/pub/6630514301d2a3fbfcc145be/?f=cs
4.LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
本文介绍了一种名为LoRA(低秩适应)的方法,该方法是大型语言模型(LLM)参数高效微调(PEFT)中广泛采用的技术。LoRA能够在减少可训练参数和内存使用的同时,达到与全量微调相当的性能。作者旨在评估在现实世界应用中使用LoRA微调的LLM的可行性和性能。首先,作者对10个基础模型和31个任务进行了量化低秩适应器微调,总共涉及到310个模型,评估了其质量。结果表明,4位LoRA微调模型平均比基础模型高出34分,比GPT-4高出10分。其次,研究了最有效的基准模型进行微调,并评估了任务复杂性启发式在预测微调结果方面的相关性和预测能力。最后,作者评估了LoRAX的开源多LoRA推理服务器的延迟和并发能力,该服务器使用共享基础模型权重和动态适配器加载,在一块NVIDIA A100 GPU上部署多个LoRA微调模型。LoRAX支持LoRA Land,这是一个网络应用程序,它在单个NVIDIA A100 GPU上,使用80GB内存托管了25个LoRA微调的Mistral-7B LLM。LoRA Land突显了使用多个专用LLM相对于单个通用LLM在质量和成本效益上的优势。
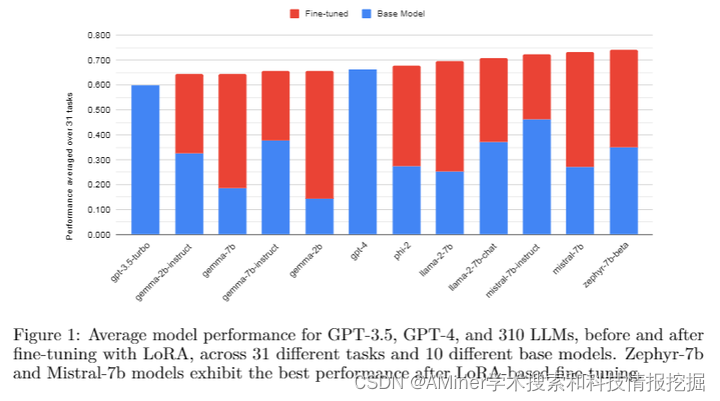
链接:https://www.aminer.cn/pub/6634456501d2a3fbfc2d282c/?f=cs
5.When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
本文探讨了大型语言模型(LLM)如何有效学习使用信息检索(IR)系统,特别是当需要额外上下文来回答给定问题时。尽管IR系统的性能表现出色,但问答的最佳策略并不总是涉及外部信息检索,而是通常需要利用LLM自身的参数化记忆。先前的研究已经在PopQA数据集中发现了这一现象,即最流行的 questions 可以通过LLM的参数化记忆有效地回答,而较少流行的则需要使用IR系统。基于此,我们提出了一个为LLM定制的训练方法,利用现有的开放领域问答数据集。在这里,LLM被训练在不知道答案时生成一个特殊标记 。我们在PopQA数据集上评估了自适应检索LLM(Adapt-LLM)的表现,结果显示,与相同LLM相比,在三种配置下都有所改进:(i)为所有问题检索信息,(ii)总是使用LLM的参数化记忆,(iii)使用流行度阈值来决定何时使用检索器。通过我们的分析,我们证明Adapt-LLM能够在确定不知道如何回答问题时生成标记,表示需要IR,而在选择仅依赖其参数化记忆时,它能达到显著高的准确度。
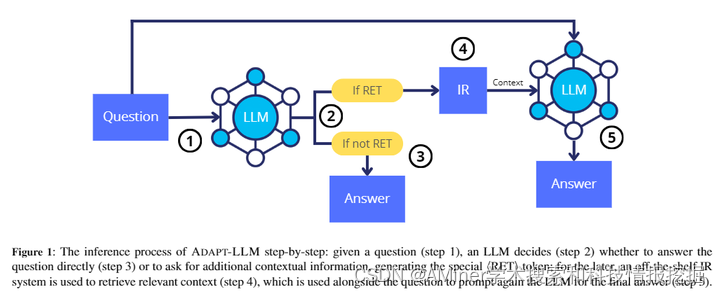
链接:https://www.aminer.cn/pub/6631a2d501d2a3fbfc8c4be9/?f=cs
AMiner AI入口:
https://www.aminer.cn/chat/g/explain?f=cs















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









