






神经网络中激活函数的作用:
a. 不使用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
b. 使用激活函数,能够给神经元引入非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以利用到更多的非线性模型中。
激活函数需要具备以下几点性质:
- 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参 数。
- 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
- 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
Caffe
Caffe是纯粹的C++/CUDA架构,支持命令行、Python和MATLAB接口;
可以在CPU和GPU直接无缝换:Caffe::set_mode(Caffe::GPU); 在Caffe中图层需要使用C++定义,而网络则使用Protobuf定义。Caffe是一个深度卷积神经网络的学习框架,使用Caffe可以比较方便地进行CNN模型的训练和测试,精于CV领域。
Caffe作为快速开发和工程应用是非常适合的。caffe官方提供了大量examples,照着examples写,caffe只要求会写prototxt就行,它的训练过程、梯度下降算法等等都实现封装好了,懂了prototxt的语法了,基本就能自己构造神经网络了。
caffe作为C++语言以及配合了CUDA开发的框架,训练效率也有保证,这也是caffe适合于工业应用的原因。代码易懂好理解,高效、实用。上手简单,使用方便,比较成熟和完善,实现基础算法方便快捷,开发新算法不是特别灵活,适合工业快速应用实现.
Caffe 需要预先安装比较多的依赖项,CUDA,snappy,leveldb,gflags,glog,szip,lmdb,OpenCV,hdf5,BLAS,boost、ProtoBuffer等;
Caffe官网:http://caffe.berkeleyvision.org/;
Caffe Github : https://github.com/BVLC/caffe;Caffe 安装教程:
http://caffe.berkeleyvision.org/installation.html,
http://blog.csdn.net/yhaolpz/article/details/71375762;
Caffe 安装分为CPU和GPU版本,GPU版本需要显卡支持以及安装CUDA
TensorFlow
pytorch
中文文档
官方文档
linux(cpu):
Python2.7
pip install torch1.3.1+cpu torchvision0.4.2+cpu -f https://download.pytorch.org/whl/torch_stable.html
Python3.X
pip3 install torch1.3.1+cpu torchvision0.4.2+cpu -f https://download.pytorch.org/whl/torch_stable.html
linux(GPU):cuda9.2版本
pip install torch1.3.1+cu92 torchvision0.4.2+cu92 -f https://download.pytorch.org/whl/torch_stable.html
官网:链接
深度学习算法的本质是通过反向传播求导数,PyTorch的Autograd模块实现了此功能, 只有Variable才具有自动求导功能,Tensor是没有该功能的,需把Tensor封装为Variable。Tensor是PyTorch中的一个重要数据结构,可认为是高维数组。
######2020.1.14
第三章
tensor内部数据结构,tensor分为头信息区(Tensor)和存储区(Storage),信息区主要保存着tenso的形状(size)、步长(stride)、数据类型(type)等信息,而真正的数据则保存在连续数组。一个tensor有着与之相对应的storage,storage是在data之上封装的接口,不同的tensor的头信息一般不同,但却可能使用相同的storage。
向量化
向量化计算是一种特殊的并行计算方式,Python本身是一门高级语言,使用很方便,但许多操作很低效,尤其是for循环,科学计算程序中应当极力避免使用Python原生的for循环,尽量使用向量化的数值计算。
#########2020.1.15
Variable
PyTorch 在autograd模块中实现了计算图的相关功能,autograd中的核心数据结构是Variable。Variable封装了tensor,并记录对tensor的操作记录用来构建计算图。Variable数据结构的三个属性:
data:保存variable所包含的tensor.
grad:保存data对应的梯度,grad也是variable,而非tensor,它与data形状一致。
grad_fn:指向一个Function,记录variable的操作历史,即它是什么操作的输出,用来构建计算图。如果某一个变量是由用户创建,则它为叶子节点,对应的grad_fn等于None.
Variable的构造函数需要传入tensor,同时有两个可选参数。
requires_grad(bool):是否需要对该variable进行求导。
volatile(bool):意为“挥发”设置为True,构建在该variable之上的图都不会求导,专为推理阶段设计。
Variable 支持大部分tensor支持的函数,但其不支持部分inplace函数,因为这些函数会修改tensor自身,而在反向传播中,variable需要缓存原来的tensor来计算梯度。如果想计算各个Variable的梯度,只需要调用根节点variable的backward方法,autograd会自动沿着计算图反向传播,计算每一个叶子节点的梯度。
variable.backward(grad_variables=None,retain_graph=None,create_graph=None)主要有如下参数。
grad_variables:形状与variable一致,对于y.backward(),grad_variables相当于链式法则-----。grad_variables也可以是tensor或序列。
retain_graph:反向传播需要缓存一些中间结果,反向传播之后,这些缓存就被清空,可以通过指定这个参数不清空缓存,用来多次反向传播。
create_graph:对反向传播过程再次构建计算图,可通过backward of backward 实现求高阶导数。
计算图
PyTorch中autograd的底层采用了计算图,计算图是一种特殊的有向无环图(DAG)用于记录算子与变量之间的关系。一般用矩形表示算子,椭圆表示变量。
只有对variable的操作才能使用autograd,如果对variable的data直接进行操作,将无法使用反向传播。除了参数初始化,一般我们不直接修改variable.data的值。
在PyTorch 中计算图的特点可总结为:
1、autograd根据用户对variable的操作构建计算图。对variable的操作抽象为Function。
2、由用户创建 的节点成为叶子节点,叶子节点的grad_fn为None。叶子节点中需要求导的variable,具有AccumulateGrad标识,因其梯度是累加的。
3、variable默认是不需要求导的,即requires_grad属性默认为False。如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad 都为True。
4、variable的volatile属性默认为False,如果某一个variable的volatile属性被设置为True,那么所有依赖它的节点volatile属性都为True。volatile属性为True的节点不会求导,volatile的优先级比requires_grad的高。
5、多次反向传播时,梯度是累加的。反向传播的中间缓存会被清空,为进行多次反向传播需指定retain_graph=True来保存这些缓存。
6、非叶子节点的梯度计算完之后即被清空,可以使用autograd.grad或hook技术获取非叶子节点梯度的值。
7、variable的grad与data形状一致,应避免直接修改variable.data,因为对data的直接操作无法利用autograd进行反向传播。
8、反向传播函数backward的参数grad_variables可以看成链式求导的中间结果,如果是标量,可以省略,默认为1.
9、PyTorch采用动态图设计,可以很方便的查看中间的输出,动态的设计计算图结构。
扩展autograd
绝大多数函数都是可以使用autograd实现反向求导,但如果需要自己写一个复杂的函数,不支持自动反向求导,需写一个Function,实现它的前向传播和反向传播代码。Function对应计算图中的矩阵,它接收参数 ,计算并返回结果。
1、自定义的Function需要继承autograd.Function,没有构造函数__init__,forward和backward函数都是静态方法。
2、forward函数的输入和输出都是tensor,backward函数的输入和输出都是variable。
3、backward函数的输出和forward函数的输入一一对应,backward函数的输入和forward函数的输出一一对应。
4、backward函数的grad_output参数即t.autograd.backward中的grad_variables.
5、如果某一输入不要求导,直接返回None,例如forward中的输入参数x_requires_grad显然无法对它求导,直接返回None即可。
6、反向传播可能需要利用前向传播的某些中间结果,在前向传播过程中,需要保存中间结果,否则前向传播结束后这些对象即被释放。
7、使用Function.apply(variable)即可调用实现的Function。
#####2020.1.16
第四章
神经网络工具箱nn
autograd 实现了自动微分系统,然而对于深度学习来说过于底层,本章将介绍nn模块,是构建于autograd之上的神经网络模块。除了nn之外,还会介绍神经网络中常用的工具,比如优化器optim、初始化init等。
4.1 nn.Module
全连接层
多层感知机
4.2 常用神经网络层
1、图像相关层
主要包括卷积层(Conv)、池化层(Pool)等,实际使用中分为一维(1D)、二维(2D)和三维(3D),池化方式又分为平均池化(AvgPool)、最大值池化(MaxPool)、自适应池化(AdaptiveAvgPool),卷积层除了常用的前向卷积外,还有逆向卷积(TransposeConv)。
除了卷积层和池化层,深度学习中还将常用到以下几个层。
Linear:全连接层。
BatchNorm:批规范化层,
第五章
Pytorch 中常用工具
在训练神经网络的过程中需要用到很多工具,其中最重要的三部分是数据、可视化和GPU加速。
1、数据处理
图像、文本、语音或二进制文件
数据加载
>__getitem__:返回一条数据或者一个样本。obj[index]等价于obj.__gettitem__(index).
>__len__:返回样本的数量。len(obj)等价于obj.__len__().
[Keras](https://github.com/keras-team/keras)
Keras由纯Python编写而成并基于Tensorflow、Theano以及CNTK后端,相当于Tensorflow、Theano、CNTK的上层接口,号称10行代码搭建神经网络,具有操作简单、上手容易、文档资料丰富、环境配置容易等优点,简化了神经网络构建代码编写的难度。目前封装有全连接网络、卷积神经网络、RNN和LSTM等算法。
利用pip或者conda安装numpy、keras、 pandas、tensorflow等库。
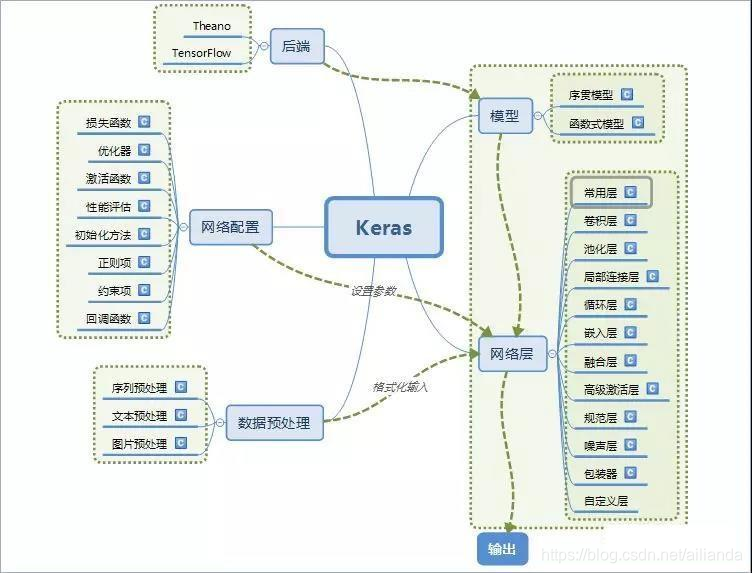
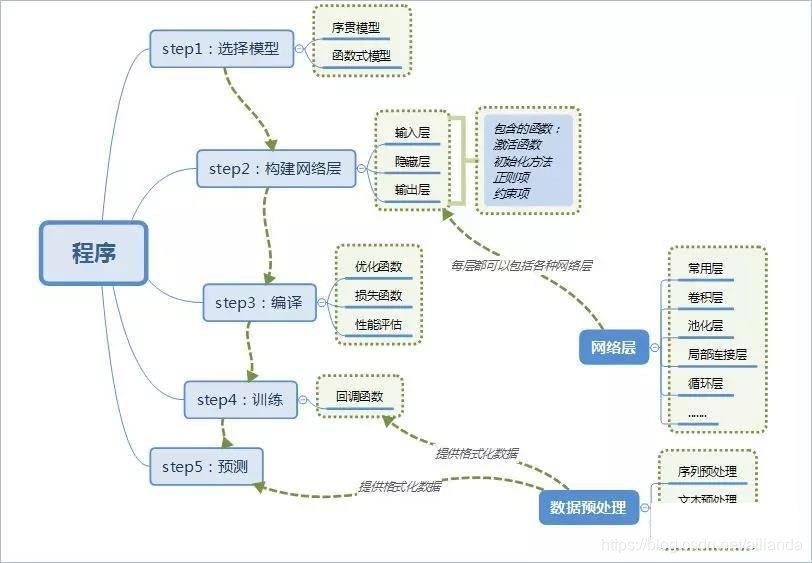
使用keras搭建神经网络步骤:
[Mxnet](https://github.com/apache/incubator-mxnet)
############################
https://www.jianshu.com/p/a507c3287e75















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









