






1.整体描述
1.前言
GAN模型中有两个分布,一个是生成器,一个是判别器,根据他们的名字就可以看出,生成器是生成和真数据相似的分布来欺骗判别器,二判别器是判断出假数据从而不让生成器得逞,原文中作者举了一个很形象的例子,生成器就如假币的贩子,判别器就如警察,假币贩子制造假币,警察识别假币找出假币贩子,是一个对抗的过程。
其实,原始的生成器和判别器很简单,就是一些全连接网络组成,可以通过反向传播进行端到端的训练,训练过程相当于一个不断学习和对抗的过程。
整个过程大概如下图所示,将随机噪音输入到生成器,这里的随机噪音例如可以服从的是高斯分布,生成器根据输入的噪声生成一张假图像,判别器将真实图像和生成的假图像作为输入进行训练,这里的判别器其实就是一个二分类模型,输出为真或假。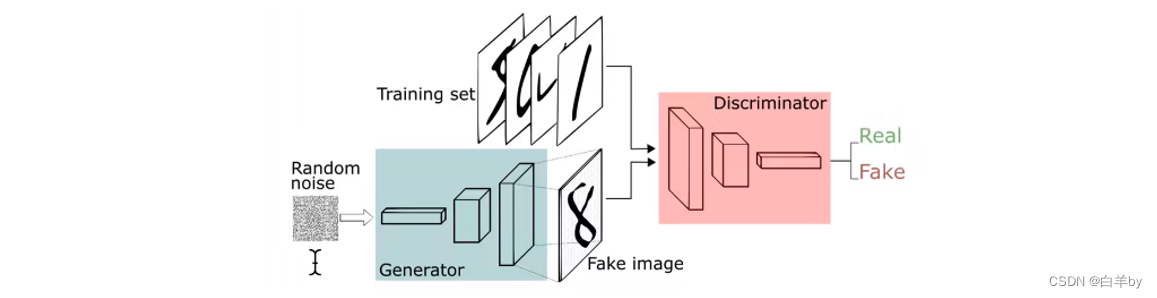
2.目标函数
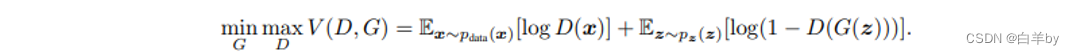
式中,z是随机噪声,是随机噪声z的分布,是生成器,输入为z,其中有一个权重参数,是判别器,输入为图像x,他的权重参数为,所以对于GAN来说他训练的是两个模型,是一个对抗的过程,所以在他的目标函数中有一个求最大max和一个求最小min的过程。
GAN的目标函数包括两部分,如图中的红框和绿框:
判别器D要最大化,
的含义是将真实图像输入到判别器D中,判别器认为是真图的概率,判别器希望真实图像的概率越大越好,这就对应了式中的maxD,绘制出
图像如下
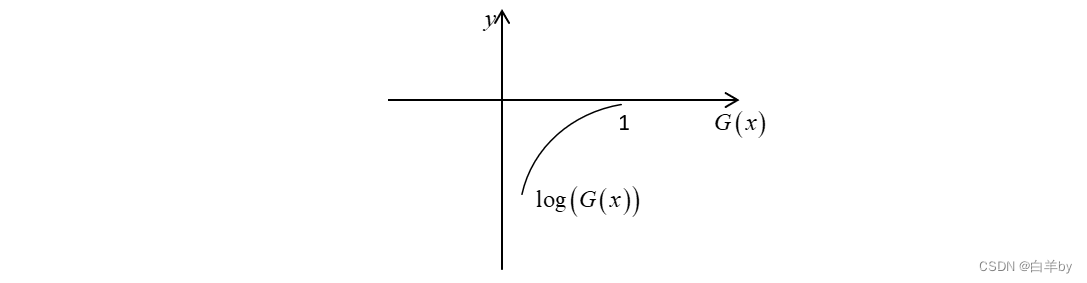
生成器要最小化函数,的含义是将噪声z输入到生成器G中得到一个假图,然后将输入到判别器D中,输出判别器认为假图是真图的概率,即。绘制出图像如下,生成器的目标是让判别器认为假图是真图的概率越大越好,即接近于1,而是一个递减的过程,即越大越小,所以生成器的目标变成了让越小越好,这就对应了式中的minG。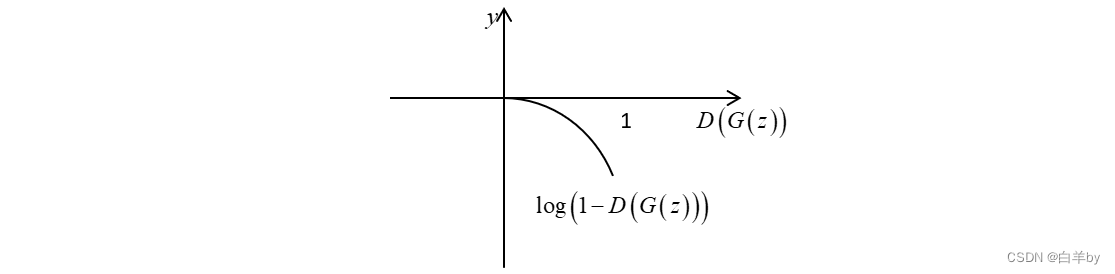
3.原理
如图,详细和展示了GAN整个训练过程
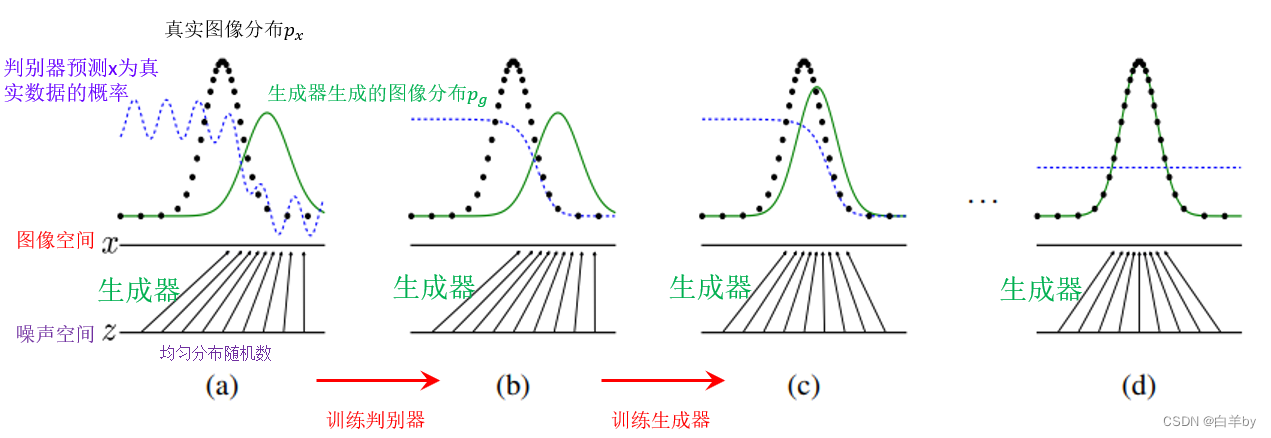
图中, Z为噪声空间,噪声空间中为均匀分布的随机数,生成器将噪声空间的随机数z映射到图像空间x,随机点映射到图像空间的分布就是绿色曲线所示的高斯分布,而图像中的黑色曲线为真实图像的数据分布,蓝色曲线为判别器预测x为真实数据的概率,蓝色曲线在真实数据的分布出偏高,在生成器生成的数据分布处偏低。
- 第一步就是训练判别器(图(b)),将曲折的蓝线训练成平滑的曲线,可以很好的分别真实数据和虚假数据。
- 然后就是训练生成器图(c),将生成器的图像分布绿线逐渐接近真实数据的分布黑线。
- 最后交替训练判别器和生成器图(d),直到生成器的图像分布绿线和真实数据的分布黑线重合,判别器无法区分两个分布,此时蓝色变成一条水平线。
4.训练
这部分就是详细说明了GAN的训练过程,包括给定生成器训练判别器,和给定判别器训练生成器,将会涉及到大量的计算公式以及推导。
训练过程对应的伪代码如图,训练过程包括两个,第一个是首先训练k次判别器,然后再训练一次生成器。

- GAN的训练在同一轮梯度反转的过程中可以细分为2步:(1)先训练D;(2)再训练G。注意,不是等所有的D训练好了才开始训练G,因为D的训练也需要上一轮梯度反转中的G的输出值作为输入。
- 当训练D的时候:上一轮G产生的图片和真实图片,直接拼接在一起作为x。然后按顺序摆放成0和1,假图对应0,真图对应1。然后就可以通过D,x输入生成一个score(从0到1之间的数),通过score和y组成的损失函数,就可以进行梯度反传了。(我在图片上举的例子是batch = 1,len(y)=2*batch,训练时通常可以取较大的batch)
- 当训练G的时候:需要把G和D当作一个整体,这里取名叫做’D_on_G’。这个整体(简称DG系统)的输出仍然是score。输入一组随机向量z,就可以在G生成一张图,通过D对生成的这张图进行打分得到score,这就是DG系统的前向过程。score=1就是DG系统需要优化的目标,score和y=1之间的差异可以组成损失函数,然后可以采用反向传播梯度。注意,这里的D的参数是不可训练的。这样就能保证G的训练是符合D的打分标准的。这就好比:如果你参加考试,你别指望能改变老师的评分标准。
训练判别器
首先采样m个随机噪声,生成m个假图像,
然后再采样m个真图像,
最后由损失函数和梯度,更新判别器的权重参数,
其中目标函数和我们之前说的是一样的,只不过是将期望换成了均值。
训练生成器
首先采样m个随机噪声,生成m个假图像,
然后由损失函数和梯度,更新生成器的权重参数,
注意再生成器的目标函数中,不会收到判别器的影响,所以只有生成器的部分。
给定生成器,训练判别器
首先给出结论,再进行证明:
对于给定的生成器G,最优的判别器为
其中为真实图像的概率,
为假图像的概率
给定判别器,训练生成器
当且仅当时,生成器的目标函数取得最小值 -log4
5.变形
1.DCGCN
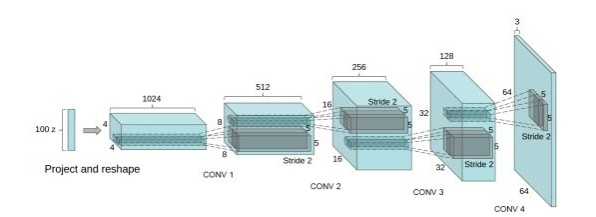
- DCGAN中的G网络示意,相等于普通CNN的逆过程
DCGAN把上述的G和D用了两个卷积神经网络(CNN)。同时对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
- 取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
- 在D和G中均使用batch normalization
- 去掉FC层,使网络变为全卷积网络
- G网络中使用ReLU作为激活函数,最后一层使用tanh
- D网络中使用LeakyReLU作为激活函数
2.WGAN和WGAN-GP
WGAN也是一篇经典,WGAN主要从损失函数的角度对GAN做了改进,损失函数改进之后的WGAN即使在全链接层上也能得到很好的表现结果,具体的来说,WGAN对GAN的改进有:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 对更新后的权重强制截断到一定范围内,比如[-0.01,0.01],以满足论文中提到的lipschitz连续性条件。
- 论文中也推荐使用SGD, RMSprop等优化器,不要基于使用动量的优化算法,比如adam。
之前的WGAN虽然理论上有极大贡献,但在实验中却发现依然存在着训练困难、收敛速度慢的问题,这个时候WGAN-GP就出来了,它的贡献是:
- 提出了一种新的lipschitz连续性限制手法—梯度惩罚,解决了训练梯度消失梯度爆炸的问题。
- 比标准WGAN拥有更快的收敛速度,并能生成更高质量的样本
- 提供稳定的GAN训练方式,几乎不需要怎么调参,成功训练多种针对图片生成和语言模型的GAN架构
3.Conditional GAN
因为原始的GAN过于自由,训练会很容易失去方向,从而导致不稳定又效果差。而Conditional GAN就是在原来的GAN模型中加入一些先验条件,使得GAN变得更加的可控制。具体的来说,我们可以在生成模型G和判别模型D中同时加入条件约束y来引导数据的生成过程。条件可以是任何补充的信息,如类标签,其它模态的数据等。然后这样的做法应用也很多,比如图像标注,利用text生成图片等等。

比之前的目标函数,Conditional GAN的目标函数其实差不多: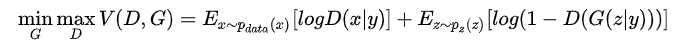
就是多了把噪声z和条件y作为输入同时送进生成器火热把数据x和条件y作为输入同时送进判别器(如上整体架构图)。这样在外加限制条件的情况下生成图片
6.训练GAN的技巧
- 批量加载和批规范化,有利于提升训练过程中博弈的稳定性。
- 使用tanh激活函数作为生成器最后一层,将图像数据规范在-1和1之间,一般不用sigmoid。
- 选用Leaky ReLU作为生成器和判别器的激活函数,有利于改善梯度的稀疏性,稀疏的梯度会妨碍GAN的训练。
- 使用卷积层时,考虑卷积核的大小能被步幅整除,否则,可能导致生成的图像中存在棋盘状伪影。棋盘效应,先调一下生成器和判别器的kernel_size和strides。确保卷积后的比重在学习前是相等的。















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









