







一.简介
从2019年十一月之后,就开始学习使用HLS实现CNN卷积神经网络,对YOLO算法进行加速了。无奈只有图像处理的基础,没有研究过AI,研究生期间一点点的HLS基础也早就忘记了,希望以后都能根据进度养成写博客的习惯,工作之余记录一下自己的学习和成长吧。
本帖已实现卷积操作的IP核,并通过了FPGA开发板的验证。
二.HLS部分
高级综合HLS基础学习,参考Xilinx官方文档ug871-vivado-high-level-synthesis-tutorial以及ug902-vivado-high-level-synthesis。
HLS实现了一层网络的卷积操作,使用16bit量化的方式,将输入特征图和权重都转换成16bit定点数进行乘加操作。关于浮点数量化的代码在之前的一篇博客里。
- TOP Function的定义如下:
void CNN_FPGA(int *Input,int *Weight,int *Output)
将输入输出接口定义为AXI Master接口类型:
#pragma HLS INTERFACE s_axilite register port=return bundle=CTRL_BUS
#pragma HLS INTERFACE s_axilite register port=Output bundle=CTRL_BUS
#pragma HLS INTERFACE m_axi depth=1024 port=Output offset=slave bundle=DATA_BUS1 num_read_outstanding=1 num_write_outstanding=1 max_read_burst_length=64 max_write_burst_length=64
#pragma HLS INTERFACE s_axilite register port=Weight bundle=CTRL_BUS
#pragma HLS INTERFACE m_axi depth=512 port=Weight offset=slave bundle=DATA_BUS2 num_read_outstanding=1 max_read_burst_length=128
#pragma HLS INTERFACE s_axilite register port=Input bundle=CTRL_BUS
#pragma HLS INTERFACE m_axi depth=1024 port=Input offset=slave bundle=DATA_BUS1 num_read_outstanding=1 num_write_outstanding=1 max_read_burst_length=64 max_write_burst_length=64
(1) 该接口协议会把指针映射为DDR中的实际地址,通过AXI Master总线进行读写,如果不加AXI_Lite(CTRL_BUS),所有数据的偏移地址均为0;添加AXI_Lite总线之后,实际的偏移地址可通过AXI_Lite对应偏移位置的寄存器进行配置。
(2) 关于return,该主函数没有需要返回的值,但是作为block-level I/O protocol,Xilinx recommends that you include the block-level I/O protocol associated with the return port in the AXI4-Lite interface.(ug902)
(3) 关于depth,本以为depth会映射为AXI和FPGA之间的FIFO或者BRAM,用以数据的存储,后来发现不是的,C/RTL co-simulation 来存储指针一次传输多个读写数据。

(4) 关于num_read_outstanding: 指定该AXI4总线集合了多少个读/写请求。可以理解为读写通道数。
#pragma HLS interface m_axi port=input offset=slave bundle=gmem0
depth=1024*1024*16/(512/8)
latency=100
num_read_outstanding=32
num_write_outstanding=32
max_read_burst_length=16
max_write_burst_length=16
To further improve bus efficiency, the options num_write_outstanding and num_read_outstanding ensure the design contains enough buffering to store up to 32 read and write accesses.
(5) block-level protocol
生成的IP接口协议为AXI4和AXI4_Lite,需要先配置对应的AXI4_Lite中的寄存器,来确定内存中数据的偏移地址,并启动IP开始工作。可在solution/impl/ip/drivees中找到该IP各配置寄存器的详细说明。例如:
// CTRL_BUS
// 0x00 : Control signals
// bit 0 - ap_start (Read/Write/COH)
// bit 1 - ap_done (Read/COR)
// bit 2 - ap_idle (Read)
// bit 3 - ap_ready (Read)
// bit 7 - auto_restart (Read/Write)
// others - reserved
// 0x04 : Global Interrupt Enable Register
// bit 0 - Global Interrupt Enable (Read/Write)
// others - reserved
// 0x08 : IP Interrupt Enable Register (Read/Write)
// bit 0 - Channel 0 (ap_done)
// bit 1 - Channel 1 (ap_ready)
// others - reserved
// 0x0c : IP Interrupt Status Register (Read/TOW)
// bit 0 - Channel 0 (ap_done)
// bit 1 - Channel 1 (ap_ready)
// others - reserved
// 0x10 : Data signal of Input_r
// bit 31~0 - Input_r[31:0] (Read/Write)
// 0x14 : reserved
// 0x18 : Data signal of Weight
// bit 31~0 - Weight[31:0] (Read/Write)
// 0x1c : reserved
// 0x20 : Data signal of Output_r
// bit 31~0 - Output_r[31:0] (Read/Write)
// 0x24 : reserved
// (SC = Self Clear, COR = Clear on Read, TOW = Toggle on Write, COH = Clear on Handshake)
#define XCNN_FPGA_CTRL_BUS_ADDR_AP_CTRL 0x00
#define XCNN_FPGA_CTRL_BUS_ADDR_GIE 0x04
#define XCNN_FPGA_CTRL_BUS_ADDR_IER 0x08
#define XCNN_FPGA_CTRL_BUS_ADDR_ISR 0x0c
#define XCNN_FPGA_CTRL_BUS_ADDR_INPUT_R_DATA 0x10
#define XCNN_FPGA_CTRL_BUS_BITS_INPUT_R_DATA 32
#define XCNN_FPGA_CTRL_BUS_ADDR_WEIGHT_DATA 0x18
#define XCNN_FPGA_CTRL_BUS_BITS_WEIGHT_DATA 32
#define XCNN_FPGA_CTRL_BUS_ADDR_OUTPUT_R_DATA 0x20
#define XCNN_FPGA_CTRL_BUS_BITS_OUTPUT_R_DATA 32
其中,XCNN_FPGA_CTRL_BUS_ADDR_AP_CTRL 为该IP的状态寄存器,可查看该IP的各种状态,并且向该寄存器中写入0x1之后,IP核开始正常工作。
- static定义数组
static定义数组或其他局部变量,即使声明时未赋值,编译器自动对其初始化。在HLS中,数组经常被定义为static变量,映射到RTL上,Reset之后,所有的数组都初始化为0。且static定义的变量保存在全局数据区,即使函数返回,它的值也可以保持不变,而不会被释放。
static short input_map_buffer[input_map_dimension][input_map_height][input_map_width];//8x32x32
#pragma HLS ARRAY_PARTITION variable=input_map_buffer complete dim=1

数组分割后只保留第一维度,2、3维度完全分割。
3. memcpy函数
HLS中memcpy函数的声明如下:
void * __cdecl memcpy(void * __restrict__ _Dst,const void * __restrict__ _Src,size_t _Size)
本次设计中的使用:
static int input_map_buffer_temp[input_map_length_int];
memcpy(input_map_buffer_temp,(int *)input,input_map_NUM*sizeof(int));
需要特别注意的是,向input_map_buffer_temp中copy的数据,千万不能超过该数组的长度。C中溢出的数据不会对数据造成影响;但是在RTL中,溢出的数据会从Bram的0地址处重新copy,导致结果错误。由于C和RTL对该指令的处理不同,会导致工程在HLS C Simulation时完美通过Test Bench,但是生成IP之后上板测试时,结果天壤之别。
三、Vivado硬件连接
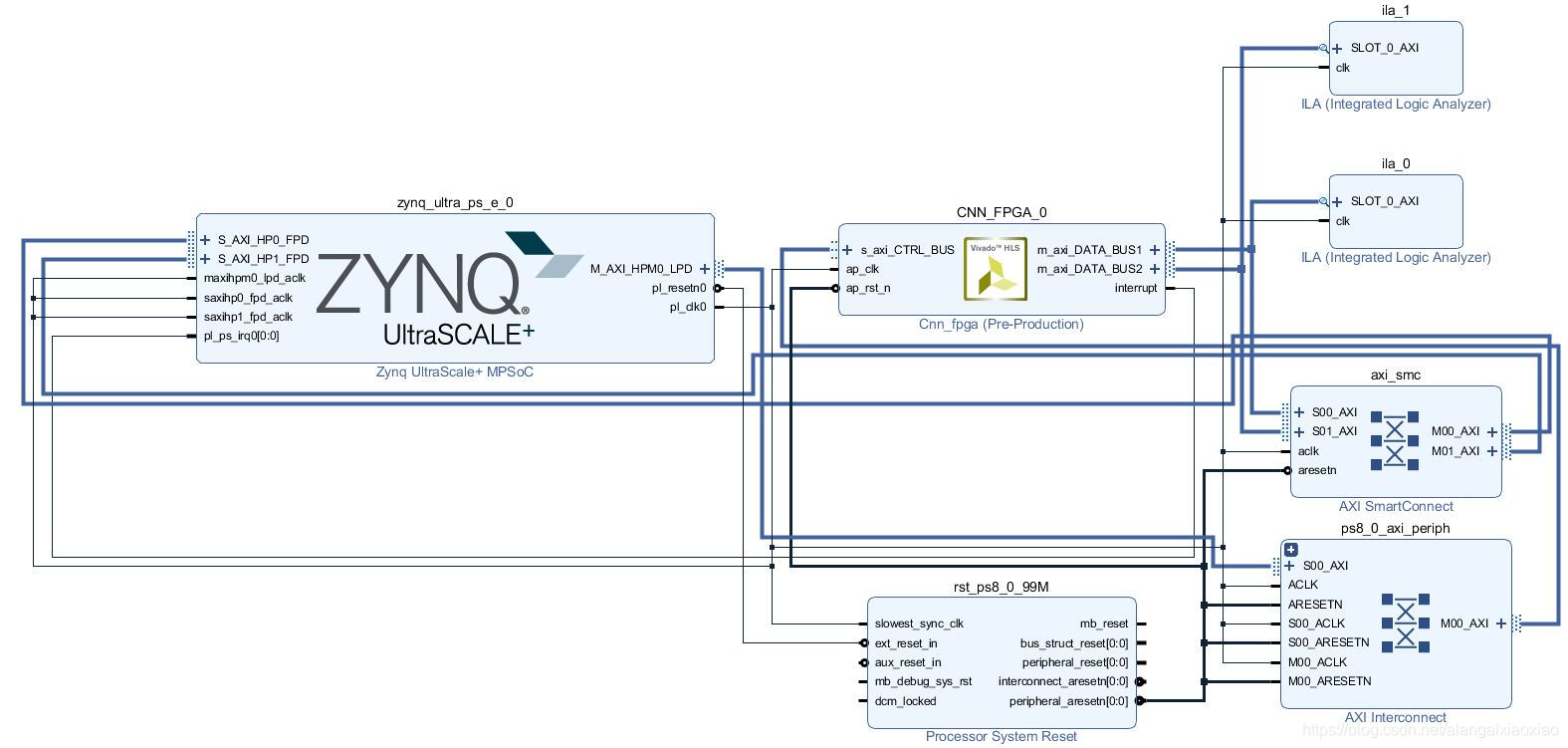
硬件地址为:
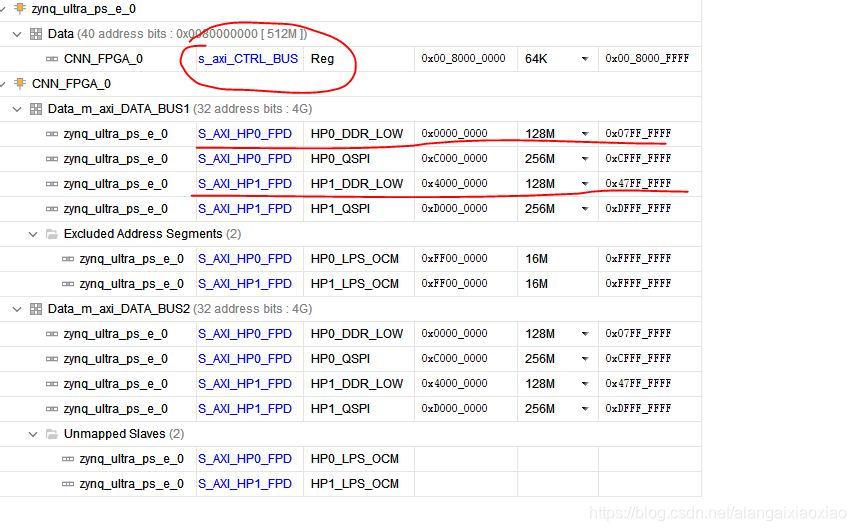
其中,AXI4_Lite初始地址对应于s_axi_CTRL_BUS;m_axi_DATA_BUS1对应S_AXI_HP0_FPD;m_axi_DATA_BUS2对应S_AXI_HP1_FPD;
四、PS部分
本工程需要在PS测生成数据源,导入到S_AXI_HP0_FPD和S_AXI_HP0_FPD对应的内存地址中去,并完成IP的配置和启动。
(1) 由于本项目裸跑,没有上系统,所有在不能方便的读取数据文件。用了个笨笨的方法:
//File:main
#include "input_map_data.h"
int main(){
...
extern const int input_map[input_map_num];
...
}
//File :input_map_data.h
const int input_map[input_map_num] = {输入测试数据};
(2) CPU Cache
每次觉得搞明白CPU和内存Cache一致性的问题了,过一段时间又啪啪打脸。本次调试花费时间最多的就是这里了。使用memcpy或者是Xil_Out的方式,向特定的地址中写入数据,然后启动IP,从ILA中查看的数据依然不对。经过怀疑过一切的调试过程之后,才猛然意识到,是不是忘记刷Cache了,再记录一次吧。下次写程序可不能忘记了
memcpy(inupt_map_baseaddr_ptr,input_map,int_map_num*sizeof(int));
Xil_DCacheFlush();
向内存中写入数据之后,刷一次Cache,将数据刷到内存中。从内存中读取数据时,如果使用过DMA等方式的数据传输,要先使该区域的Cache无效,然后重新读取。
#include "xil_cache.h"
//写点什么到发送缓冲区sendram
Xil_DCacheFlushRange((u32)sendram,sizeofbuffer);//将内容刷新至DDR
//启动发送DMA过程。。。。
//启动接收DMA过程。。。。。
Xil_DCacheInvalidateRange((u32)recvram,sizeofbuffer);//将DDR内容拉进Cache
//从recvram中读取数据吧!

















 1662
1662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









