






1. 概述
在当今数字化营销时代,适配各种展示平台的视觉内容呈现成为了一项挑战。随着扩散模型等生成式模型的革新,生成式AI技术在图像和视频领域取得了显著的进步。特别是 Stable Diffusion (SD) 模型的发展,使得能够创造出符合各种风格的高品质、逼真的视觉作品。在这个背景下,视觉延展 (Outpainting) 技术显得格外重要,它能够扩展图像或视频的边界,以匹配不同的显示比例和尺寸需求。
智能广告创意的核心任务之一就是屏蔽纷繁复杂的广告位对客户的创意素材的不同需求,尤其是创意的尺寸。当前进行尺寸适配的主要方式是对已有素材进行裁剪或者套上人工设计的边框模版,以上方式能够解决基本需求,但是裁剪方法会丢失原始素材的部分内容,甚至出现裁剪失败、文字截断、人物残缺等问题。直接套模板的方式往往会遇到破坏图片的原生性、人工设计感强烈、视觉效果降低等问题。因此,我们期望通过生成式AI技术实现创意任意目标尺寸的拓展,同时保持素材原生性,提升投放深度和效果。
随着 AIGC 技术的快速发展,我们也在该领域有持续的研究和探索,与业务相结合,孵化出了视频尺寸魔方、商品视频动效生成等基于扩散模型的AI生成编辑工具。本文将聚焦尺寸魔方,介绍我们在 AIGC 应用于广告创意任意尺寸变换上的探索和实践。商家们能够将上传的图片或视频延展至任意尺寸,从而满足不同广告场景的需求。目前尺寸魔方已经在阿里妈妈素材库、独立工具、品牌广告BP百灵等多项业务场景中完成上线,大幅提高了广告素材的原生适配性和展示投放效果,为商家带来了极大的便利。
2. 技术方案
对于电商场景的原生图片以及视频创意素材进行尺寸延展存在诸多挑战,核心是如何在根据原始素材进行任意尺寸延展的同时保持准确性,完成素材的一键裂变,为此,我们在优质数据集构建、延展模型优化、生成效果策略优化等方面做了诸多探索,整体技术框架图如下:

尺寸魔方整体技术方案主要分为以下步骤:
素材质量过滤:首先对于素材进行预处理,主要是通过人物检测、清晰度、边框检测等对于低质图片以及视频进行过滤;
素材挖掘:根据原始素材,通过算法模型挖掘出更多的显式特征(包括Canny特征、分镜头片段、主体词等),在尺寸延展生成过程中将这些特征以条件的形式注入模型,进一步提升模型性能;
图片&视频延展制作:将原始的素材经过送入编码器中,在潜在空间根据相关条件输入到 UNet 中进行迭代去噪推理,最后得到延展生成后的素材;
超分辨率:通过视觉超分模型提升生成内容的分辨率和清晰度;
后处理策略:通过贴回原图(或原视频)以及边缘区域渐进融合等策略,最大程度上和原始素材一致,保证只向外延展;同时按商家选定的目标尺寸对一次延展结果进行裁剪,得到目标尺寸的素材;
3. 方案细节介绍
3.1 数据工程
为了使模型更好的适配淘宝电商场景,我们为每个图片和视频精细标注了一系列重要属性标签,涵盖了清晰度、文字识别(OCR)、视频动效的强度、人脸和人体检测、牛皮癣识别,以及综合的美学评分等多个维度。经过多维度打分排序过滤,最终清洗得到更加优质的图片以及视频数据集,另外通过构造适用于延展任务的遮掩区域完成数据集构建,用于图片&视频延展模型的训练优化。
3.2 图片延展
得益于 Stable Diffusion 的开源生态,现在的市面上有非常多的基于 Stable Diffusion 微调得到的图片生成模型,例如专攻二次元风格的 Anything 模型、能够生成以假乱真的真人模型 Chilloutmix 等等,Civitai 作为一个AIGC模型社区,包含了众多类似的模型资源(各种各样的基座模型以及插件)。基于 Stable Diffusion 的图像inpainting模型,目前也能取得较好的局部重绘效果,而图片延展任务可以看作对图片外框即延展区域的局部重绘,因此我们选择基于 Stable Diffusion 开发图片延展算法。

3.2.1 一致性优化
在初期的尝试中,我们发现直接使用现有模型,不论是 SD Inpainting 模型还是基于 ControlNet Inpainting 的模型,在延展区域都倾向于生成无意义的内容花边或与原图区域不太相关的内容,延展区域与原图区域割裂感严重。这是因为延展区域的潜在特征通常是使用单一值或者噪声进行填充,这样模型在延展区域倾向于随机生成内容。为了使延展区域和原图内容更一致,衔接更流畅,我们采用垫图策略得到初步的延展图片,然后将其输入 VAE 得到潜在特征,用于引导扩散模型的生成,从而使延展区域与原图区域更一致,以下是一些对比图片:

3.2.2 伪文字优化
电商场景的图片上通常会带有一些 Logo、促销卖点文案之类的元素,对这类图片进行延展时,SD模型经常会“依样画葫芦”,在延展区域生成一些伪文字,针对这一问题,我们也尝试在负向提示词方面进行了探索,在一定程度上缓解了这一问题。另外考虑到对于包含促销外框类的图片,延展后促销框的位置会在图片中间,观感比较奇怪,我们也引导商家使用较干净的图片进行延展,这也降低了模型生成伪文字的概率。
3.2.3 多模型推理
人体区域的绘制一直是图片生成领域的挑战之一,在 Civitai 社区中有许多模型针对这一问题进行优化,这些模型在人体区域的绘制上的表现明显优于其他通用模型,但我们发现这类模型存在一定的偏差,对非人体区域也容易联想成人体,不适用于通用场景的延展。因此我们通过前置的人体检测模型,判断延展区域是否包含人体部位,对于需要延展人体的区域使用人体专用模型,对其他区域使用通用模型,从而兼顾通用场景和人体部位的延展需要。

3.2.4 后处理策略
在具体的业务场景中,商家的原图通常分辨率很高,在原分辨率进行图像延展存在以下几方面问题:1)计算开销大,可能出现GPU显存不足的问题;2)RT随着分辨率的提升成倍增长,影响用户体验;3)模型训练与推理阶段使用的分辨率差异过大,可能导致生成效果下降。为解决以上问题,我们在生成图片前,首先将图片resize到固定尺寸再进行生成,这保证了生成效果和RT的稳定性。我们使用超分辨率模型将生成图超分到目标尺寸再进行原图贴回,使延展区域和原图区域的清晰度和细腻程度相对一致。同时,我们对贴回区域边缘进行线性平滑融合缓解视觉上的割裂感,这些后处理策略在实际应用中都有不错的效果提升。
3.3 视频延展
考虑到电商场景与通用场景存在差异,并且社区中缺乏面向视频延展任务的模型,我们单独设计了视频延展模型,并结合多种的训练策略(SD先验、遮掩策略、多条件辅助生成等)研发了更适用于电商场景的视频延展模型。同时,为了缓解长视频延展推理过程中的误差累积,我们也提出了混合由粗到细的推理流水线。相关工作已发表在ACM MM 2023,相关模型和代码已开源,感兴趣的同学可以查阅论文和项目主页:
Title:Hierarchical Masked 3D Diffusion Model for Video Outpainting
链接:https://arxiv.org/abs/2309.02119
开源仓库:https://github.com/alimama-creative/M3DDM-Video-Outpainting
3.3.1 模型概览
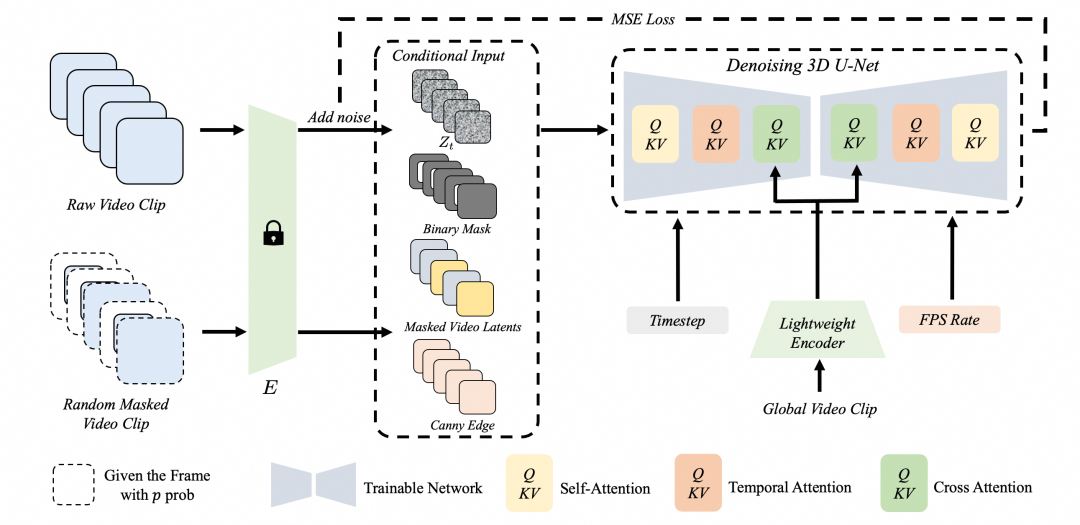
我们的视频延展模型整体上基于扩散模型架构。在训练阶段,通过在原始数据上不断施加噪声,并利用深度网络来预测并去除噪声,通过这种方式,推理阶段能够从高斯分布随机采样的噪声来逐步推理出原始的数据分布。而在视频延展场景中,我们在训练阶段要学习一个 3D U-Net 的去噪网络去拟合视频样本中的噪声。我们采用 Stable Diffusion 作为基座模型,同时为了让原始的 Stable Diffusion 模型适配视频延展任务,参考通用视频扩散模型,我们引入了时序卷积,并对自注意力层和交叉注意力层进行了调整,以保证不同视频帧间能够有效交互。
3.3.2 任意尺寸延展
考虑到电商场景存在多样的广告资源位尺寸,为了适应商家在实际投放中不同尺寸的素材延展需要,我们专门研究了如何构造面向任意尺寸的视频延展训练策略。在构建视频延展训练样本时,我们采用了多样化的遮掩策略来模拟不同的填充需求。具体而言,我们对视频帧的边缘部分进行随机遮掩,涵盖全方向、单一方向、双向(横向或纵向)、四个方向中任选一方向,以及全面遮掩等多种模式。
这样的训练模式不仅赋予模型上下文信息预测边缘内容的能力,还能够依据邻近帧生成更加连贯和稳定的视频内容。我们平衡了三种模式的使用比例,以确保模型在各种情况下都能表现出优异的性能。通过多样化的遮掩训练策略,能够使得我们的模型具备较好的任意尺寸延展能力。对于不同尺寸的具体延展效果可见下方视频:
3.3.3 多条件辅助生成
我们发现仅使用掩码以及遮掩后的视频帧等特征输入到模型,对于空间逻辑较复杂的视频的延展结果会存在 Artifact 等问题。进一步地,我们探索了通过更多的条件(全局帧提示、Canny边缘信息注入)来辅助模型进行生成,并且取得了比较好的效果。首先,为了使模型能够感知当前片段之外的全局视频信息,我们均匀地从视频中采样16帧。这些全局帧通过一个可学习的轻量级编码器来获取特征图,然后通过交叉注意力机制输入到 3D-UNet 中。除此之外,为了保证延展区域与已有区域的连贯性,我们还对输入视频提取了 Canny 边缘检测信息,该信息中包含目标的线条、轮廓等纹理信息,对尺寸延展提供一定辅助。具体地,我们在 3D-UNet 的输入层加入多帧的 Canny 信息,通过拼接的方式和其他条件进行结合,一并送入模型进行特征融合。从对比结果看,加入全局帧信息以及 Canny 信息均对视频延展效果有比较明显的提升。

3.3.4 长视频推理优化
在淘宝电商场景中,商家视频(如主图视频等)时长往往在10s以上,这样的长视频在尺寸延展过程中存在诸多挑战(比如,迭代式生成容易造成时序上的错误累积、推理耗时较长等)。为了解决长视频延展任务中的错误累积问题,即在上百次的推理拼接过程中,前段视频生成的差错可能会累积并影响到后续片段,我们提出了一种混合由粗到细的推理流水线。在这一流水线中,我们首先稀疏地生成一系列关键帧,然后基于这些关键帧填充更多中间结果,最后采用前后引导帧的形式密集的对视频未填充的部分进行填补。此方法的核心优势在于有效地缓解了时序上错误累积的问题。另外,为了使延展结果更加丝滑,在推理阶段我们也尝试了多种后处理策略。首先会将原视频经过帧级别垫图送入模型,在模型延展完成后通过视频超分和原始区域贴回等策略,保证原始内容的一致性以及生成的分辨率。

4. 业务应用
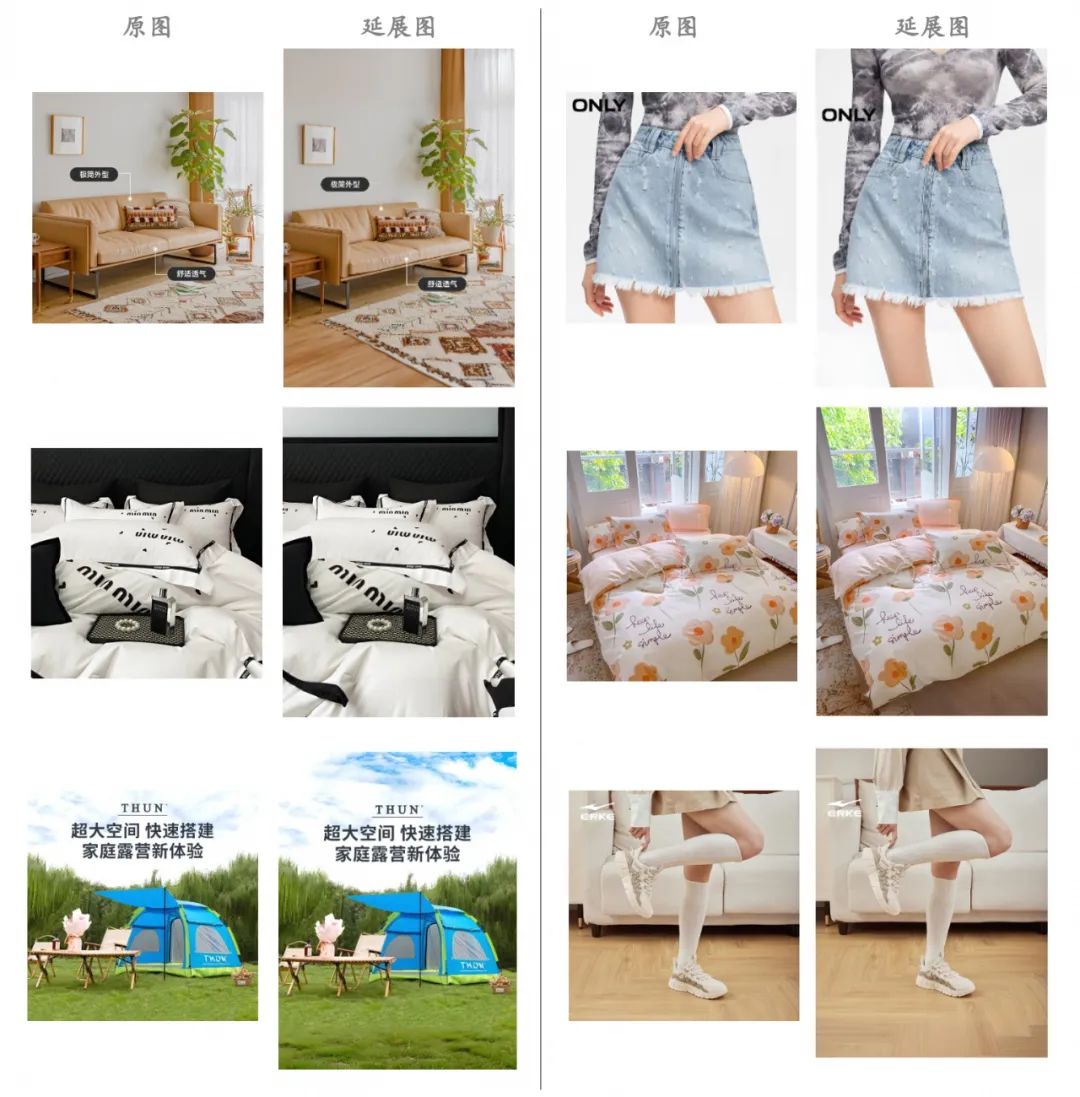
当前,尺寸魔方已经在阿里妈妈独立创作工具和广告投放平台上完成上线,商家可以上传本地(或素材库)图片或视频素材,只需要指定目标尺寸,即可在线一键完成尺寸变换。以下是一些生成的图片和视频示例:

5. 总结与展望
我们通过 AIGC 技术打破了传统素材尺寸变换的局限性,如裁剪导致的内容丢失和模板套用带来的视觉效果下降等。利用尺寸魔方,商家能够轻松地将图片或视频素材扩展至任意尺寸,以适应不同广告场景的需求,极大地提高了广告素材的原生适配性和展示效果。随着 AIGC 技术的飞速发展(Pika、Sora、Stable Diffusion 3等),未来我们将进一步提高算法模型的准确性和效率,实现更加细腻和自然的延展效果。同时,我们期望能够持续拓展尺寸魔方的应用范围,覆盖更多的电商及数字营销场景,为广大商家提供更全面的智能创意制作能力。最终目标是通过不断的技术进步,实现全方位满足用户需求,推动数字化营销与创意产业的进一步融合与创新。
▐ 关于我们
我们是阿里妈妈智能创作与AI应用团队,专注于图片、视频、文案等各种形式创意的智能制作与投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP相关背景同学加入,一起拥抱 AIGC 时代!感兴趣的同学欢迎投递简历加入我们。
✉️ 简历投递邮箱:alimama_tech@service.alibaba.com
END

也许你还想看
丨ACM MM’23 | 4篇论文解析阿里妈妈广告创意算法最新进展
丨营销文案的“瑞士军刀”:阿里妈妈智能文案多模态、多场景探索
丨CVPR 2023 | 基于无监督域自适应方法的海报布局生成
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~
















 107
107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









