




由于现实世界的视觉场景⾮常复杂,细粒度的视觉理解对于 LVLM 有效、准确地协助⼈们起着⾄关重要的作⽤。但朝着这个方向的尝试并不多(Peng et al., 2023; Chen et al., 2023a),⼤多数开源 LVLM 仍然以粗粒度的⽅式感知图像,缺乏执⾏细粒度感知(例如物体定位或⽂本阅读)的能⼒。
在本⽂中,我们探索了⼀条出路,并介绍了开源 Qwen 家族的最新成员:Qwen-VL 系列。Qwen-VL 是基于 Qwen-7B (Qwen, 2023)语⾔模型的⼀系列⾼性能、多功能的视觉语⾔基础模型。我们通过引⼊⼀种新的视觉接收器(包括语⾔对⻬的视觉编码器和位置感知适配器),为 LLM 基础模型赋予了视觉能⼒。整体模型架构和输⼊输出接⼝⾮常简洁,我们精⼼设计了三阶段训练流程,以便 在海量图⽂语料库上优化整个模型。
2 方法
2.1模型架构
模型架构由三部分组成
性Qwen-VL整体⽹络架构由三个部分组成,模型参数详情如表1所⽰:
大语言模型: Qwen-VL 采⽤⼤型语⾔模型作为其基础组件。该模型使⽤ Qwen-7B (Qwen, 2023)中的预训练权重进⾏初 始化。
视觉编码器: Qwen-VL 的视觉编码器采⽤ Vision Transformer (ViT) (Dosovitskiy 等⼈, 2021)架构,并使⽤ Openclip 的 ViT-bigG (Ilharco 等⼈, 2021)的预训练权重进⾏初始化。在训练和推理过程中,输⼊图像都会调整到特定分辨率。视觉编码器通过 将图像分割成步⻓为 14 的块来处理图像,从⽽⽣成⼀组图像特征。
位置感知视觉语言适配器:为了缓解⻓图像特征序列带来的效率问题,Qwen-VL 引⼊了⼀个⽤于压缩图像特征的视觉语⾔适配器。该适配器包含⼀个随机初始化的单层交叉注意⼒模块。该模块使⽤⼀组可训练向量(Embeddings)作为查询向量,并使⽤来自视觉编码器的图像特征作为交叉注意⼒操作的键。该机制将视觉特征序列压缩为固定⻓度 256。查询数量的计算结果⻅附录 E.2。此外,考虑到显著性,为了实现细粒度图像理解的位置信息,我们将⼆维绝对位置编码融⼊交叉注意⼒机制的查询-键值对中,以减少压缩过程中位置细节的潜在损失。⻓度为 256 的压缩图像特征序列随后被输⼊到⼤型语⾔模型中。

2.2输入和输出
图像输入:图像经过视觉编码器和适配器处理,⽣成固定⻓度的图像特征序列。为了区分图像特征输⼊和⽂本特征输⼊,在图像特征序列的开头和结尾分别附加两个特殊标记(<img>and</img>),分别表⽰图像内容的开始和结束。
边界框(Bounding Box)输⼊和输出:为了增强模型的细粒度视觉理解和基础能力,Qwen-VL 的训练涉及区域描述、问题和检测形式(region descriptions, questions, and detections)的数据。与传统的图⽂描述或问题任务不同,该任务要求模型能够准确理解并⽣成指定格式的区域描述。对于给定的边界框,⾸先进⾏归⼀化处理(范围 [0, 1000)),并将其转换为指定的字符串格式: “(Xtopleft, Ytopleft),(Xbottomleft, Ybottomright)”。 该字符串被标记为文本,⽆需额外的位置词汇。为了区分检测字符串和常规文本字符串,在边界框字符串的⾸尾添加了两个特殊标记(<box>and</box>) 。此外,为了将边界框与其对应的描述性词语或句⼦恰当地关联,还引⼊了另⼀组特殊标记(<ref>和</ref>) ,⽤于标记边界框所指代的内容。
3 训练
包含三个阶段,两个阶段的预训练,和最后阶段的指令微调
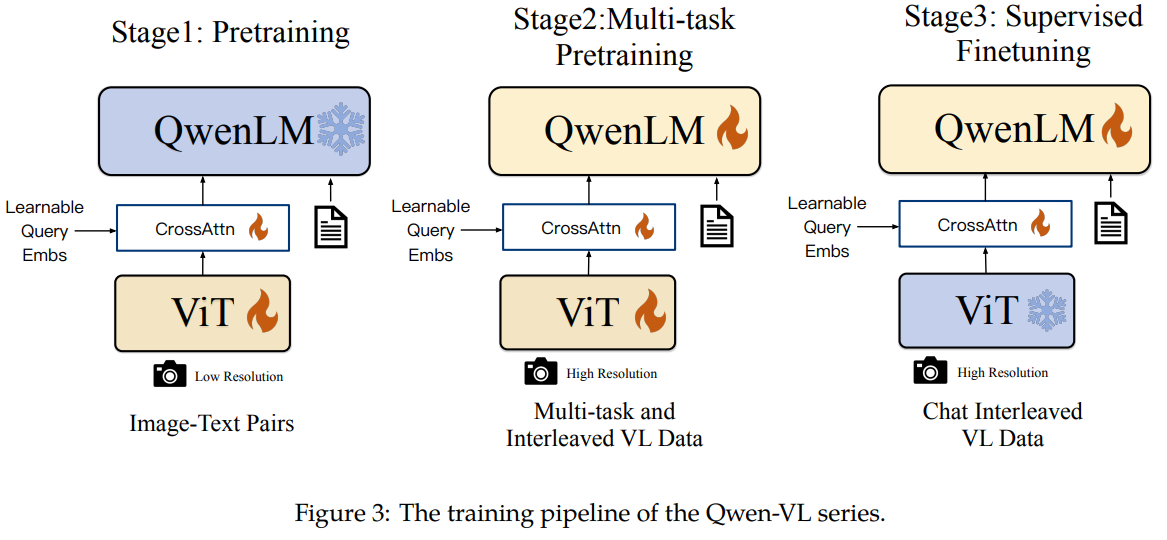
3.1预训练
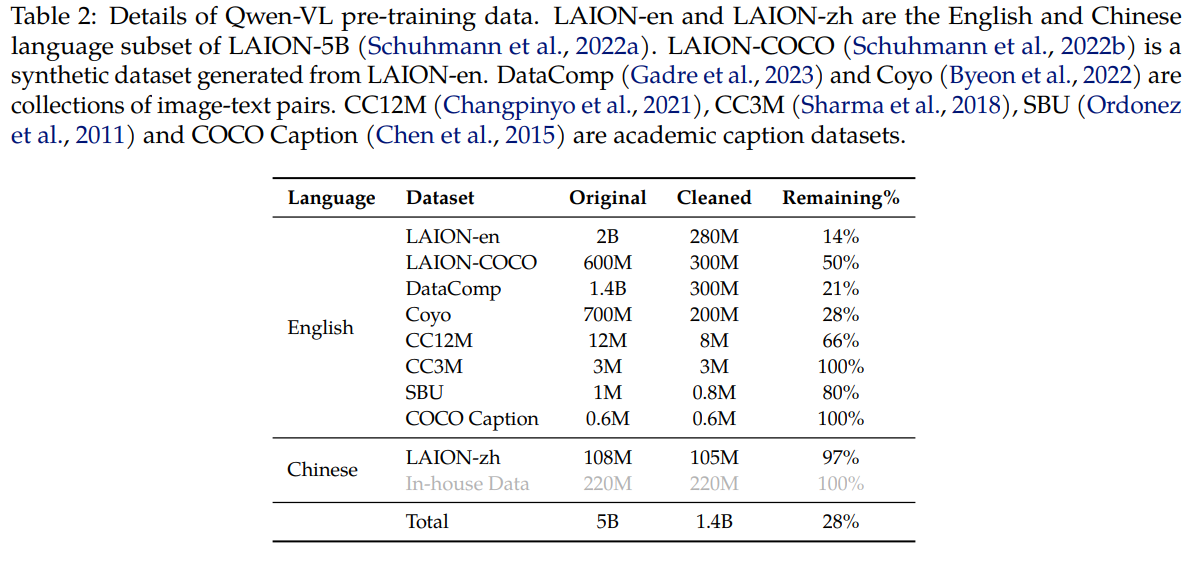
在预训练的第一阶段,我们主要利用一个大规模、弱标记(weakly labeled)、从网络爬取的图文对数据集。我们的预训练数据集由多个公开来源和一些内部数据组成。我们努力清理数据集中的某些模式。如表 2 所示,原始数据集共包含 50 亿个图文对,清理后剩余 14 亿个数据,其中 77.3% 为英文(文本)数据,22.7% 为中文(文本)数据。
我们冻结大型语言模型,在此阶段仅优化视觉编码器和视觉语言适配器。输入图像大小调整为 224 × 224。训练目标是最小化文本标记的交叉熵。最大学习率为 2e(-4),训练过程中图像-文本对的批次大小为 30720,整个第一阶段的预训练持续 50,000 步,消耗约 15 亿个图像-文本样本。更多超参数详见附录 C,本阶段的收敛曲线如图 6 所示。
3.2多任务预训练
在多任务预训练的第二阶段,我们引入了具有更大输入分辨率的高质量细粒度 VL 注释数据和交错的图像文本数据。如表 3 所示,我们同时对 Qwen-VL 进行了 7 个任务的训练。对于文本生成,我们使用内部收集的语料库来维持 LLM 的能力。captioning描述数据与表 2 相同,只是样本少得多且不包括 LAION-COCO。我们在 VQA 任务中使用了多种公开数据,包括 GQA(Hudson 和 Manning,2019 年)、VGQA(Krishna 等人,2017 年)、VQAv2(Goyal 等人,2017 年)、DVQA(Kafle 等人,2018 年)、OCRVQA(Mishra 等人,2019 年)和 DocVQA(Mathew 等人,2021 年)。我们遵循 Kosmos-2 的做法,使用 GRIT (Peng et al., 2023) 数据集进行基础任务
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











