






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:Wang.hx(源:知乎,已授权)| 编辑:CVer
https://zhuanlan.zhihu.com/p/664394525
在CVer微信公众号后台回复:Aurora,可以下载本论文pdf、代码,学起来!
很荣幸我们近期的工作Parameter-efficient Tuning of Large-scaleMultimodal Foundation Model被NeurIPS2023录用!

https://arxiv.org/abs/2305.08381
这是我们第一篇拓展至多模态领域的高效微调的工作,在该工作中我们首次采用模式逼近(mode apprximation)的方法来进行大模型的轻量化高效微调,仅需训练预训练大模型0.04%的参数。同时我们设计了两个启发性模块来增强高效微调时极低参数条件下的模态对齐。实验上,我们在六大跨模态基准测试集上进行全面评估显示,我们的方法不仅超越当前的sota, 还在一些任务上优于全量微调方法。
论文的相关代码也会开源在这个GitHub项目:
github.com/WillDreamer/Aurora
大模型的高效微调是一个非常新且日渐繁荣的task,欢迎小伙伴们一起学习交流~
一、背景
深度学习的大模型时代已经来临,越来越多的大规模预训练模型在文本、视觉和多模态领域展示出杰出的生成和推理能力。然而大模型巨大的参数量有两个明显缺点。第一,它带来巨大的计算和物理存储成本,使预训练和迁移变得非常昂贵。第二,微调限制了预训练知识在小规模数据量的下游任务中的应用效果。这两点阻碍了大模型从特定数据集扩展到更广泛场景。
为缓解预训练大模型的高昂成本,一系列参数高效微调方法相继提出。其通用范式是冻结大模型的骨干网络,并引入少量额外参数。最近,一些工作开始关注多模态领域的高效微调任务,例如UniAdapter、VL-Adapter和MAPLE。但是,它们的通用思路是将自然语言处理领域的现有架构用于多模态模型并组合使用,然后直接在单模态和多模态分支的骨干网络中插入可训练参数以获得良好表现。直接、简单的设计无法将参数高效迁移的精髓融入多模态模型。此外,还有两个主要挑战需要面对: (1)如何在极轻量级高效微调框架下进行知识迁移;(2)在极低参数环境下如何提高各模态间的对齐程度。

在这篇文章中,我们尝试解决这两种挑战,贡献可以总结为:
介绍了名为Aurora的多模态基础大模型高效微调框架,它解决了当前大规模预训练和微调策略的局限性。
提出了模式近似(mode approximation)方法来生成轻量级可学习参数,并提出了两个启发性模块来更好地增强模态融合。
通过六个跨模态任务和两个零样本任务进行实验验证,结果显示Aurora相比其他方法取得了最先进的性能,同时也只使用最少的可学习参数。
扫码加入CVer知识星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!搞科研,强烈推荐!

二、高效微调的轻量化架构的设计

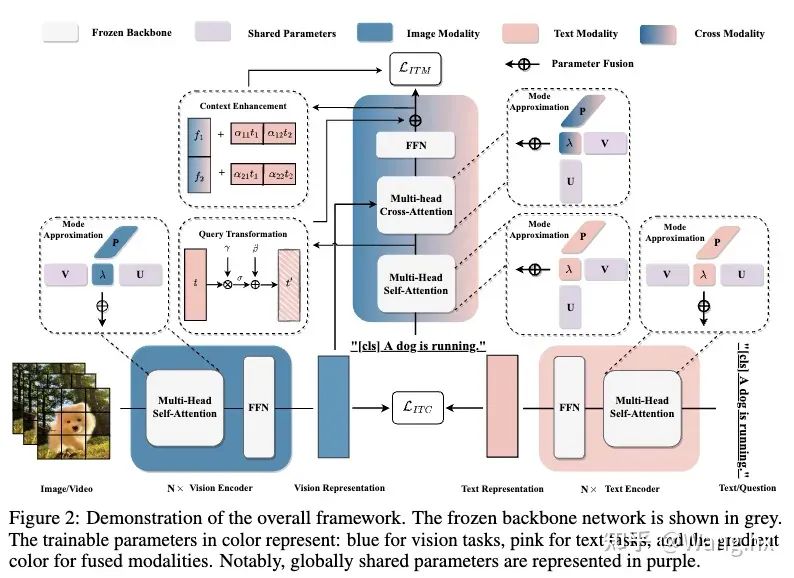
三、高效微调的模态对齐的设计
3.1 Informative Context Enhancement
该模块的目标是为了实现更好的模态对齐,在交叉注意力模块后的融合特征中提供提示文本来更好的激活。受“上下文学习”这一领域的进步启发,我们意识到为提示词提供示范模板是很重要的。最直观的方法是对图像与文本对进行对齐,以获得更多跨模态上下文信息。但是,即使与相关图像区域匹配,描述这些区域的文本可能还是有多个选择。一些文本可能准确概括图像内容,而另一些可能不行。在没有事先匹配文本信息的先验情况下,我们决定引入上下文增强模块来涵盖各个方面的可能的文本信息。

四、实验结果
4.1 实验设置
数据集与基准比较。我们在六个跨模态任务领域的benchmark上评估了Aurora,这些任务包括图片文本检索、问答(QA)、视频文本检索和视频QA。我们将Aurora与两类方法进行比较:完全微调后的SOTA方法以及Frozen重要部分的LoRA和UniAdapter方法。更多细节请参阅附录。
实现细节。我们的实现基于Salesforce开源代码库。与UniAdapter一致,我们使用BLIP-base作为所有多模态下游任务的视觉语言初始化权重。我们使用PyTorch在8台NVIDIA V100 GPU(32G)设备上实现所有实验。我们使用AdamW优化器,设置权重衰减为0.05,学习率通过网格搜索得到为1e-4。需要注意的是,在微调过程中,参数组只更新交叉注意模块的权重, backbone初始化权重不更新。
4.2 实验结果
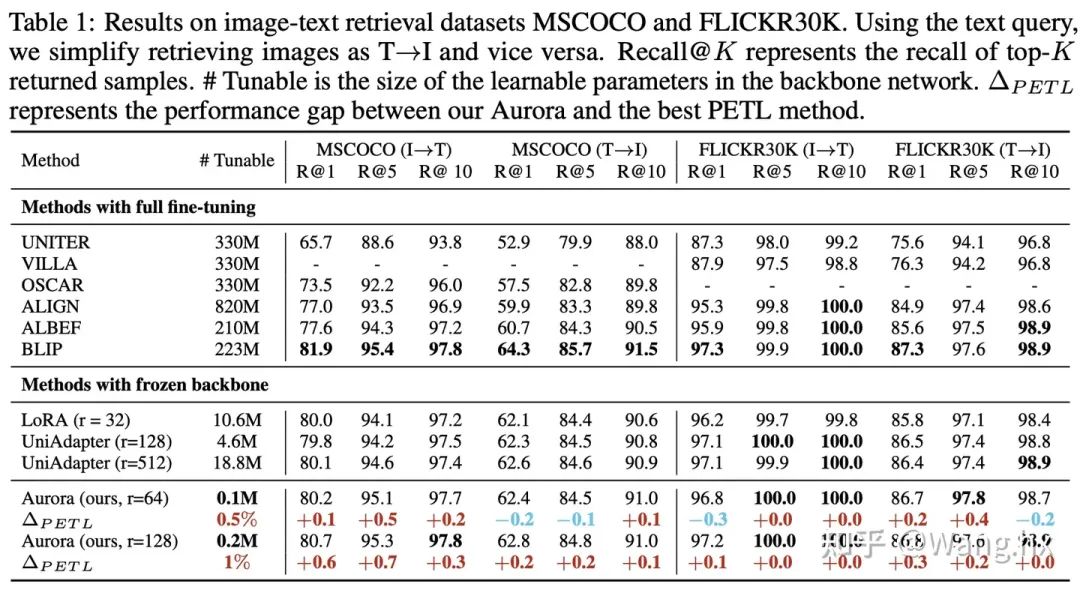
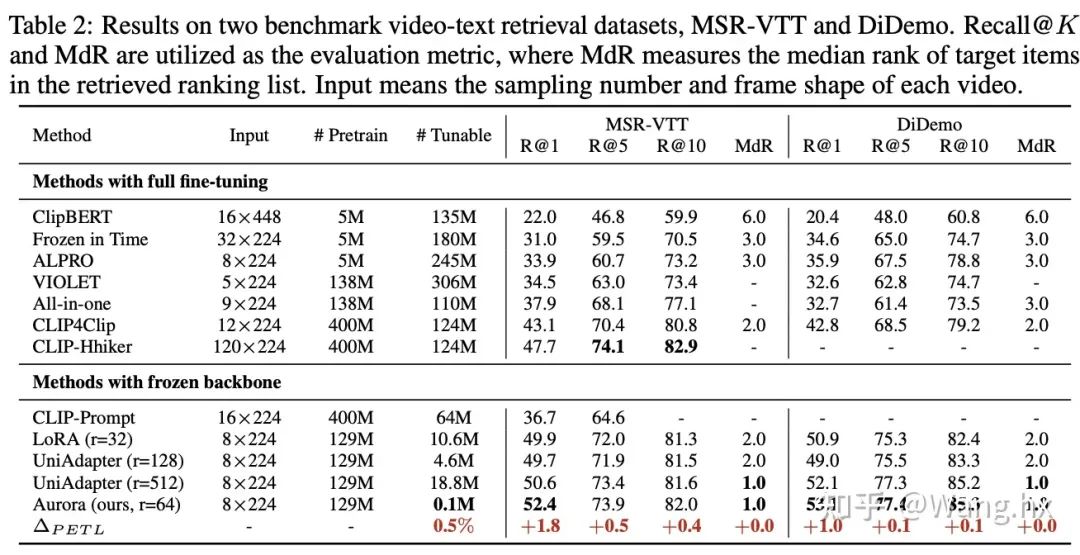
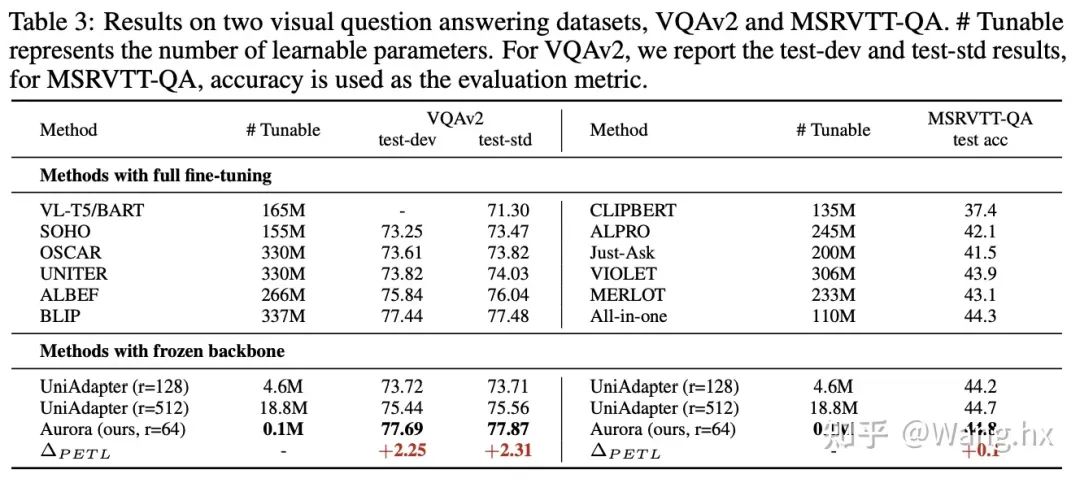
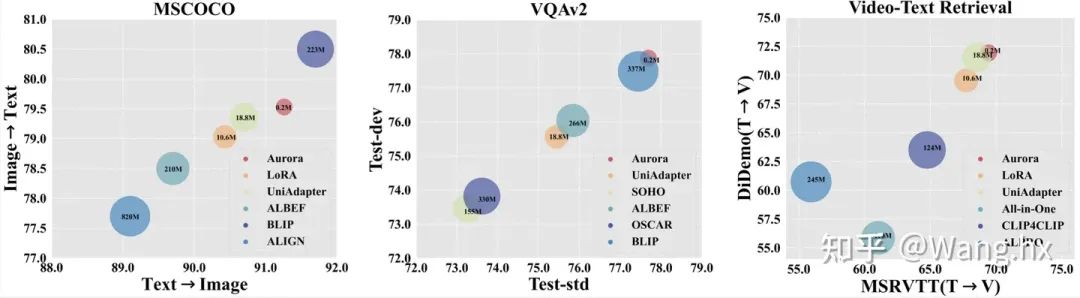
4.3 消融实验
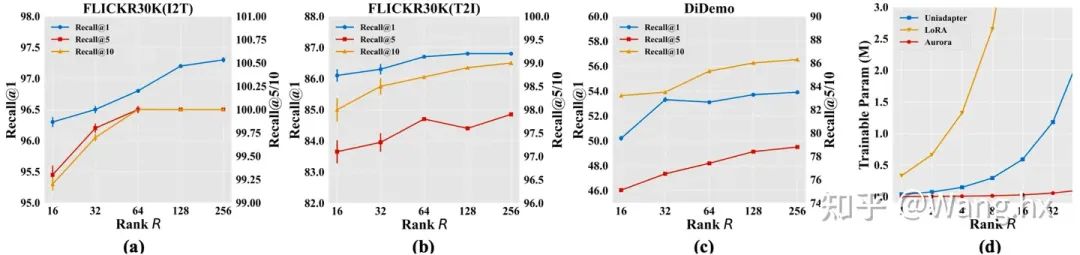
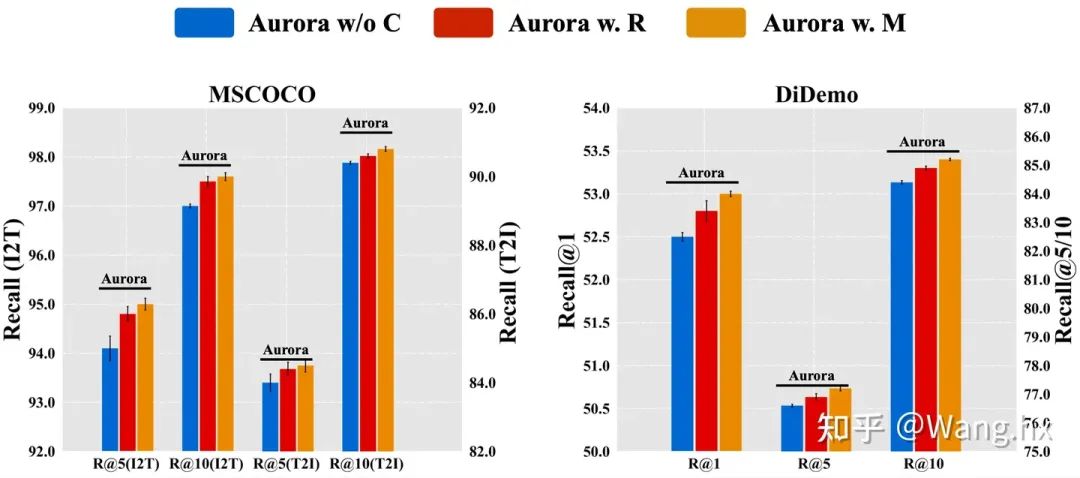
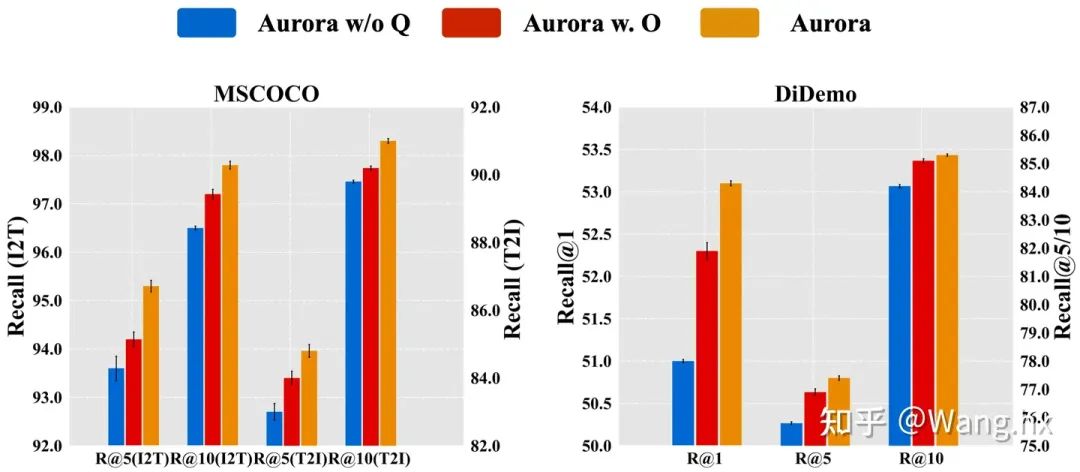

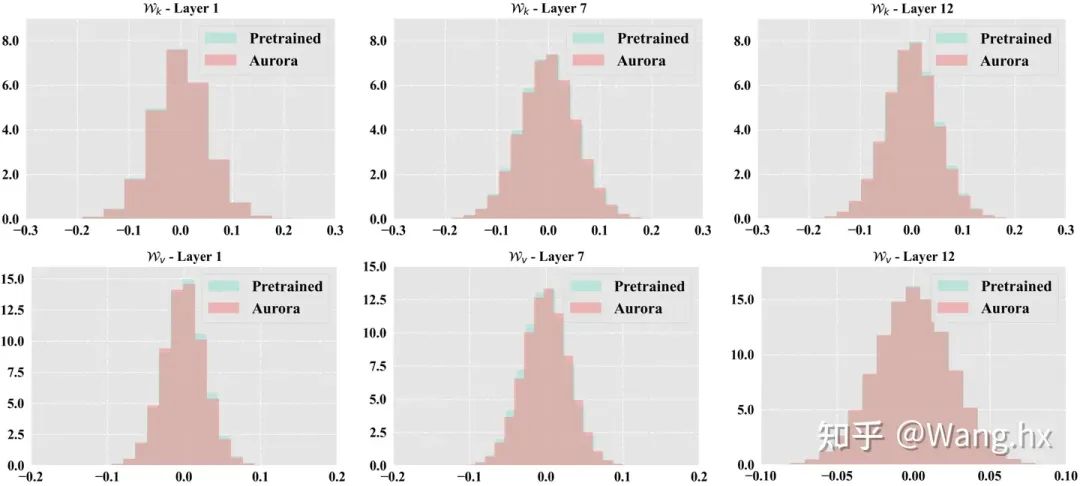
4.4 可视化分析


写在最后
月华水殿春光照,银饮金阙年华绿。
在CVer微信公众号后台回复:Aurora,可以下载本论文pdf、代码,学起来!
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集多模态和大模型交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-多模态或者大模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如多模态或者大模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
















 8820
8820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









