






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer444,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文搞科研,强烈推荐!


论文:https://arxiv.org/abs/2307.09283
代码:https://github.com/THU-MIG/RepViT
最近,轻量级视觉 Transformer(ViTs)在资源受限的移动设备上展现出了相比轻量级卷积神经网络(CNNs)更优异的性能和更低的延迟。这种改进通常归因于多头自注意力模块,使得模型能够学习全局表示。然而,轻量级 ViTs 和轻量级 CNNs 之间的架构差异尚未得到充分的研究。在这项工作中,我们重新审视了轻量级 CNNs 的高效设计,并强调了它们在移动设备上的潜力。我们通过集成轻量级 ViTs 的高效架构设计,逐步增强标准的轻量级 CNNs,具体为 MobileNetV3 [1] 。最终,我们获得了一系列新的纯轻量级 CNNs,即 RepViT。实验表明,RepViT 在各种视觉任务中优于现有的最先进的轻量级 ViTs,展现出了优秀的性能-延迟平衡。在 ImageNet 上,RepViT 首次在 iPhone 12 上延迟接近1ms的情况下达到了超过 80% 的top-1精度。我们最大的模型 RepViT-M3 只需 1.3ms 的延迟即可达到 81.4% 的 top-1 精度。下图为性能-延迟对比图:
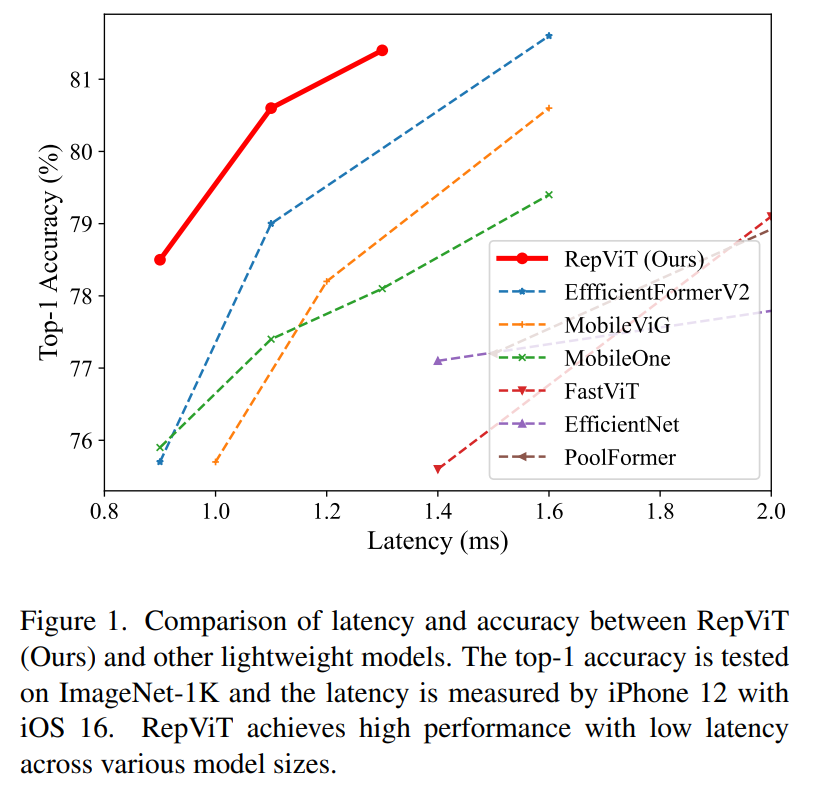
简介
轻量级模型研究一直是计算机视觉任务中的一个焦点,其目标是在降低计算成本的同时达到优秀的性能。轻量级模型与资源受限的移动设备尤其相关,使得视觉模型的边缘部署成为可能。在过去十年中,研究人员主要关注轻量级卷积神经网络(CNNs)的设计,提出了许多高效的设计原则,包括可分离卷积 [2] 、逆瓶颈结构 [3] 、通道打乱 [4] 和结构重参数化 [5] 等,产生了 MobileNets [2, 3],ShuffleNets [4] 和 RepVGG [5] 等代表性模型。
另一方面,视觉 Transformers(ViTs)成为学习视觉表征的另一种高效方案。与 CNNs 相比,ViTs 在各种计算机视觉任务中表现出了更优越的性能。然而,ViT 模型一般尺寸很大,延迟很高,不适合资源受限的移动设备。因此,研究人员开始探索 ViT 的轻量级设计。许多高效的ViTs设计原则被提出,大大提高了移动设备上 ViTs 的计算效率,产生了EfficientFormers [6] ,MobileViTs [7] 等代表性模型。这些轻量级 ViTs 在移动设备上展现出了相比 CNNs 的更强的性能和更低的延迟。
轻量级 ViTs 优于轻量级 CNNs 的原因通常归结于多头注意力模块,该模块使模型能够学习全局表征。然而,轻量级 ViTs 和轻量级 CNNs 在块结构、宏观和微观架构设计方面存在值得注意的差异,但这些差异尚未得到充分研究。这自然引出了一个问题:轻量级 ViTs 的架构选择能否提高轻量级 CNN 的性能?在这项工作中,我们结合轻量级 ViTs 的架构选择,重新审视了轻量级 CNNs 的设计。我们旨在缩小轻量级 CNNs 与轻量级 ViTs 之间的差距,并强调前者与后者相比在移动设备上的应用潜力。
方法
我们从一个标准的轻量级 CNN,即 MobileNetV3-L 开始。通过结合轻量级 ViTs 的架构选择,我们逐步从不同尺度对其进行设计。我们首先将训练条件与轻量级 ViTs 对齐,接着我们对 MobileNetV3-L 的块结构进行优化。进一步,我们在宏观尺度上进行设计,包括主干、降采样层、分类器和各阶段块数目比例。最后,我们在微观尺度上调整网络,包括卷积核大小选择和 SE [8] 层位置。下图展示了我们在每个步骤的中获得的延迟和精度结果。
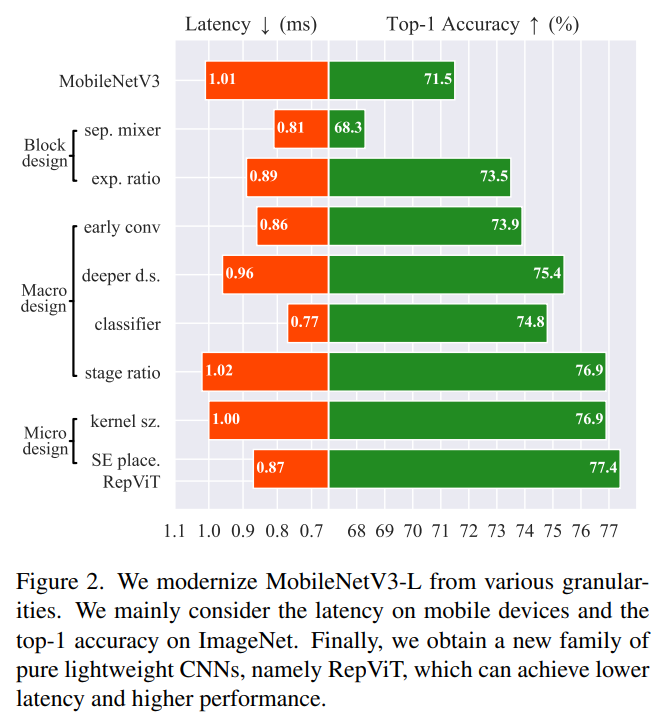
训练条件对齐
在 pytorch 官方发布的训练配方中 [9] ,MobileNetV3-L 使用 RMSPropOptimizer 进行训练600轮,准确率为 74.0%。轻量级 ViTs 通常采用 DeiT [10] 的训练方法,即使用 AdamW 优化器训练300轮,并使用 RegNetY-16GF [11] 作为教师进行蒸馏。因此,为了进行公平比较,我们首先将 MobileNetV3-L 与轻量级 ViTs 的训练条件对齐,除了暂时不使用蒸馏。MobileNetV3-L 在 1.01ms 的延迟下获得了 71.5% 的 top-1 准确率。尽管准确率下降,但为了确保公平性,我们采用这种训练方法。
块结构设计
轻量级 ViTs 的块结构具有一个重要的设计特征,即 MetaFormer [12] 结构:分离的 token mixer 和 channel mixer。因此我们对 MobileNetV3-L 的块结构进行改造,使其 token mixer 和 channel mixer 进行分离。如下图中(a)所示,原始的 MobileNetV3 块由 1*1 扩展卷积组成、然后是深度卷积和 1*1 投影层。1*1 扩展卷积层和1*1 投影层可实现通道之间的互动,深度卷积则有助于融合空间信息。前者和后者分别对应于 channel mixer 和 token mixer。如图(b)所示,我们将深度卷积上移以分离两者。同时,我们采用结构重参数化 [5] ,在训练时为深度卷积引入多分支拓扑结构,以提高性能。在推理过程中,如图(c)所示,在推理过程中,深度卷积多分枝结构可合并为单分支结构,消除多分支带来的额外计算和内存成本。我们将这样的块结构命名为 RepViT 块。基于此,MobileNetV3-L 的延迟降低到 0.81ms,top-1 准确率暂时降低到 68.3%。
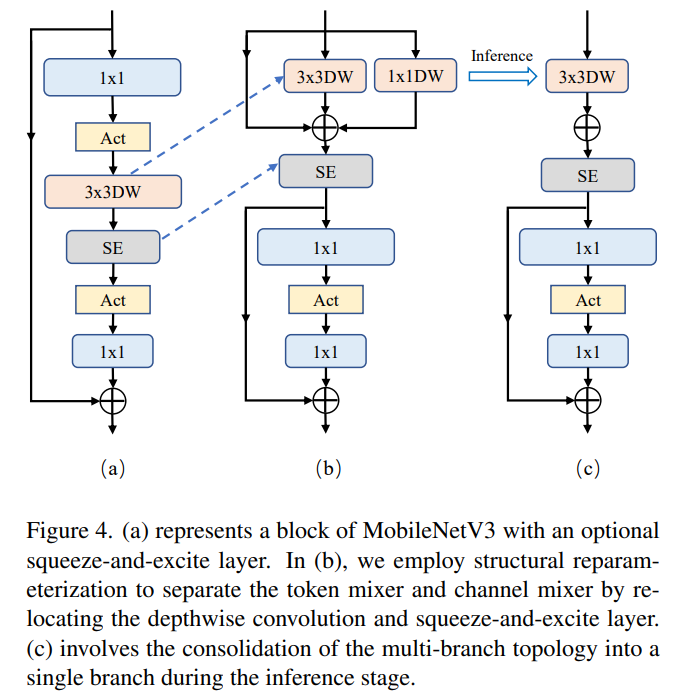
此外,轻量级 ViTs 在 channel mixer 中采用更小的扩展比例。而 MobileNetV3-L 的扩展比例很多为6,这会引入大量的计算量和通道冗余。因此,我们把扩展比例统一设置为2,这使得延迟降低到 0.65ms。我们在此基础上增加整体宽度,对四个阶段分别采用48,96,192,384的通道数。这使得延迟增加到 0.89ms,top-1准确率达到 73.5%。
宏观设计
stem 由于处理具有最高分辨率的输入特征图,因此对延迟影响很大。轻量级 ViTs 通常采用 early convolutions [13] :连续堆叠的3*3卷积,作为输入stem,相比 ViT 原始的 Patch 操作可以达到更好的精度和延迟。而MobileNetV3-L使用了一个更复杂的 stem,如下图(a)。为减少主干的延迟,MobileNetV3-L设置初始卷积通道数为16,这反过来限制了主干的表达能力。因此,我们将原始 stem 替换为 early convolutions,并把初始卷积通道数增大为24。这使得延迟降低到 0.86ms,top-1准确率达到73.9%。
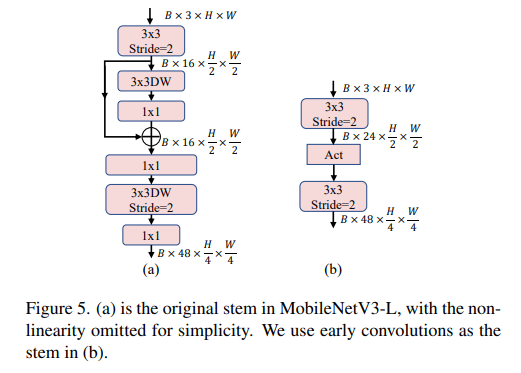
轻量级 ViTs 通常采用分离的降采样层,同时进行加深以尽量避免降采样带来的信息损失。作为对比,如下图(a),MobileNetV3-L使用同样的块结构进行降采样,将块中间的深度卷积步长改为2以降低特征图的分辨率。如图(b),在使用RepViT的块结构后,分辨率变动由上面的深度卷积完成,通道数变动由下面的1*1卷积完成。我们首先在深度卷积后增加单独的1*1卷积变更通道数,如图(c),以使降采样层与块结构解耦。在此基础上,降采样层由前面的RepViT块及后面的FFN进一步加深。这使得延迟增加到 0.96ms,top-1准确率达到 75.4%。
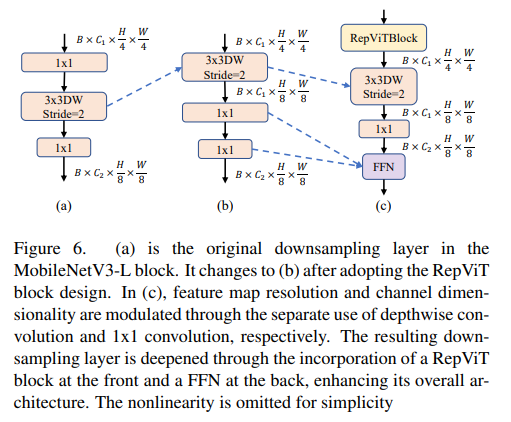
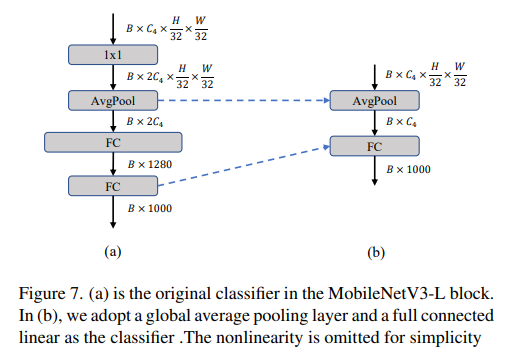
分类头负责处理模型的输出特征图,由于其通道数很大,分类头也会引入不可忽视的延迟开销。MobileNetV3-L 使用了较为复杂的分类头,如图(a)。由于 MobileNetV3-L 原始输出特征图通道数较少,因此其分类头通过使用额外的1*1卷积和全连接层将特征图映射到更高的维度上,以获得更强的拟合能力。然而,这也形成了延迟瓶颈。此外,在块结构设计中,网络的整体宽度已经加宽,所以我们将分类头更改为轻量级 ViTs 中常用的简单分类头,即池化层加全连接层,如图(b)。这使得延迟降低到 0.77ms,top-1准确率暂时降低到74.8%。
在各阶段块数目比例方面,之前的工作 [11] 发现在第三个阶段使用更多的块数目有利于网络整体的性能,这也被轻量级ViTs广泛采用。MobileNetV3-L 的各阶段块数目比例为1:2:5:2,我们在此基础上采用更优的块数目比例1:1:7:1,同时更改网络深度为2:2:14:2。这使得网络的延迟增加到1.02ms,top-1准确率增加到76.9%。
微观设计
卷积核大小通常会对CNNs的性能和延迟产生影响。之前的工作如ConvNeXt [14] ,RepLKNet [15] 探究CNN中使用大卷积核的高效方式,取得了很大的性能提升。但在移动设备上,大核卷积会带来更大的延迟开销。因此,我们将 MobileNetV3-L 中的卷积核大小全部设置为支持很好的 3*3。这使得延迟降低到 1.00ms,top-1 准确率保持不变。
多头注意力机制相比卷积的一大优势是数据驱动性质,能根据输入调整权重。SE 层通过引入通道注意力可以很好的弥补卷积网络在这方面的不足。MobileNetV3-L 中的SE层不均匀分布,且集中到后面的阶段。而 TResNet [16] 表明由于后面的阶段处理的特征图分辨率更低,SE 层依赖对特征图进行全局池化,因此加入 SE 层的收益更低。此外,考虑到加入SE层会引入额外的延迟,我们设计了交叉使用SE层的策略,来对所有阶段引入 SE。这使得延迟降低到 0.87ms,top-1准确率增加到 77.4%。
整体结构
最终,我们获得了 RepViT 网络,结构如下图。
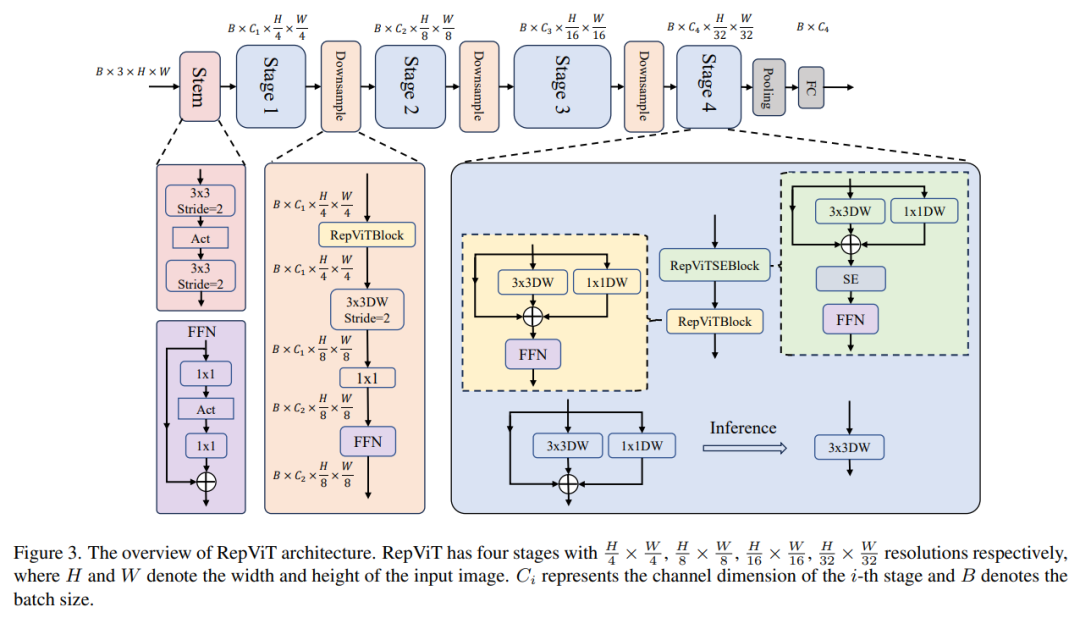
实验结果
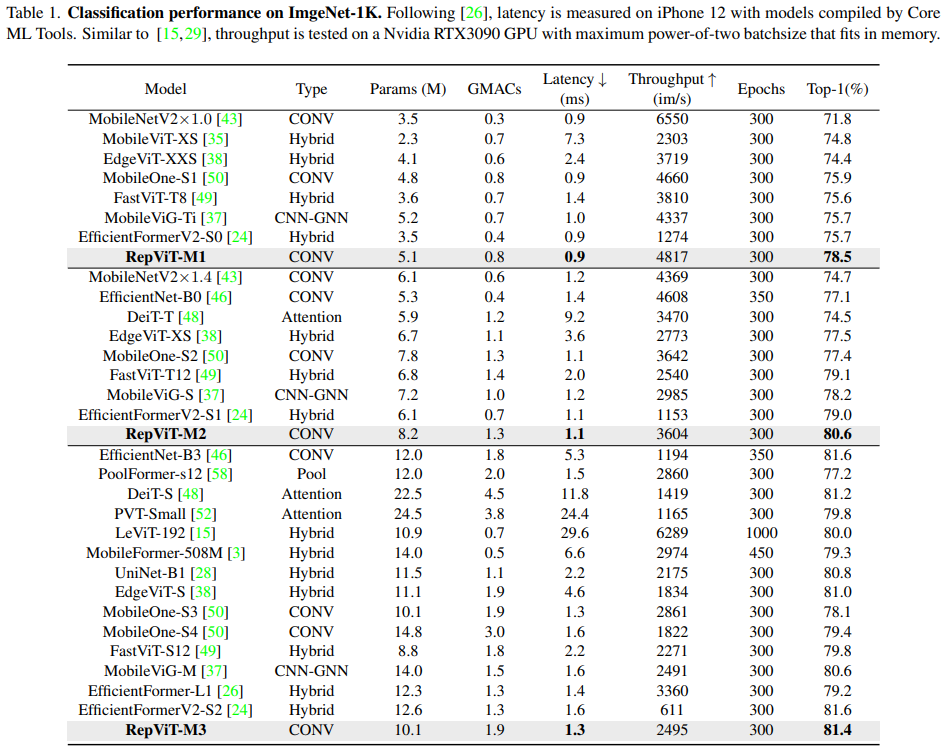
在 ImageNet 分类任务上,RepViT 的性能优于现有最先进的轻量级 ViTs 和轻量级 CNNs。在延迟相当或更低的情况下,RepViT-M1 和 RepViT-M3 的 top-1 准确率分别比 EfficientFormerV2-S0 和 EfficientFormer-L1 高 2.8% 和 2.2% 。在精度类似的情况下,RepViT-M3分别比 DeiT-S 和 EfficientNet-B3 快 9 倍和 4 倍。
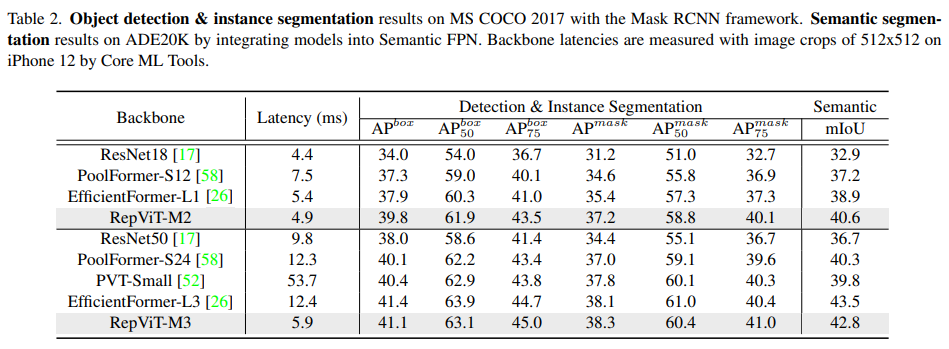
在下游任务中,RepViT 也表现出了良好的延迟-精度平衡。在 COCO 数据集的目标检测和实例分割上,RepViT-M2 以更低的延迟超出EfficientFormer-L1 1.9 box AP,1.8 mask AP。在精度类似的情况下,RepViT-M3 比 EfficientFormer-L3 快2倍。在ADE20k数据集的语义分割上,RepViT-M2和RepViT-M3在延迟跟 EfficientFormer-L1 类似的情况下,mIoU 分别超出 1.7 和 3.9 。
参考文献
[1] Searching for MobileNetV3
[2] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
[3] MobileNetV2: Inverted Residuals and Linear Bottlenecks
[4] ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
[5] RepVGG: Making VGG-style ConvNets Great Again
[6] Rethinking Vision Transformers for MobileNet Size and Speed
[7] MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
[8] Squeeze-and-Excitation Networks
[9] https://github.com/pytorch/vision/tree/main/references/classification
[10] Training data-efficient image transformers & distillation through attention
[11] Designing Network Design Spaces
[12] MetaFormer Is Actually What You Need for Vision
[13] Early Convolutions Help Transformers See Better
[14] A ConvNet for the 2020s
[15] Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
[16] TResNet: High Performance GPU-Dedicated Architecture
何恺明MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的152页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Transformer和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-Transformer和扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看













 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









