






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

转载自:Geo AI时空地理智能
GEO AI
Daily Papers

论文标题:
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
《重新利用基于扩散的图像生成器进行单目深度估计》
项目地址:
https://marigoldmonodepth.github.io/
CVPR 2024 Oral, Best Paper Award Candidate
论文创新点:
•提出了一种简单且资源高效的微调协议,可将预训练的 LDM 图像生成器转换为图像条件深度估计器;
•提出了Marigold,一种最先进的多功能单目深度估计模块,可在各种自然图像中提供出色的性能。
导 读
单目深度估计是计算机视觉中的一个基本任务,它涉及从单个图像中恢复3D深度信息。由于这个任务在几何上是不适定的,它需要场景理解。深度学习的兴起带来了突破性进展,单目深度估计器的进步与模型容量的增长相一致,从相对适度的CNNs发展到大型Transformer架构。然而,这些估计器在面对具有不熟悉内容和布局的图像时往往会遇到困难,因为它们对视觉世界的知识受到训练数据的限制,并且在零样本泛化到新领域时面临挑战。该研究探索了在最近的生成扩散模型中捕获的广泛先验知识,是否可以实现更好、更具泛化性的深度估计。

图1. Marigold,一种用于单目深度估计的扩散模型和相关的微调协议。
研究动机
该研究的动机在于解决单目深度估计中的一个核心挑战:如何从单个图像中恢复3D深度信息,尤其是在面对具有不熟悉内容和布局的图像时。尽管深度学习技术的发展已经极大地推进了单目深度估计的性能,但现有的深度估计器往往在遇到与训练数据不同的新领域或场景时表现不佳。这是因为它们对视觉世界的理解受到训练数据的限制,缺乏足够的泛化能力。
因此,研究者们寻求一种方法,利用现有的丰富视觉知识,以提高深度估计的泛化性能。该方法的动机是基于一个观察:现代图像生成模型,如稳定扩散模型,已经能够捕捉到高度复杂和多样化的视觉内容,这些内容可能为深度估计提供有用的先验信息。通过利用生成模型中的视觉知识,来解决单目深度估计中的泛化问题,从而提高对未见过场景的深度估计准确性。
研究方法
生成公式
研究者提出将单目深度估计任务定义为一个条件去噪扩散生成任务。具体地,他们开发了Marigold模型,这是一个基于潜在扩散模型的框架,用于建模条件分布D(d|x),其中d代表深度,x是给定的RGB图像。通过逐步添加和移除噪声,模型能够从噪声数据中恢复出清晰的深度信息。训练过程中,模型通过对抗性学习调整参数,以最小化去噪扩散目标函数,从而有效地从输入的RGB图像预测出对应的深度图。这种生成式框架不仅提升了深度估计的准确性,也增强了模型对新领域数据的泛化能力。
网络架构
Marigold的核心是预训练的文本到图像的潜在扩散模型(LDM),主要进行了微调以适应深度估计任务。该架构包括一个冻结的变分自编码器(VAE)用于编码图像和深度信息至潜在空间,并结合使用特定的深度编码器和解码器。在去噪过程中,模型通过修改U-Net来实现对图像的条件编码,从而提高了训练效率并保持了高分辨率图像生成的能力。通过这种精心设计的网络架构,Marigold能够高效地处理深度估计任务,同时保留了强大的图像先验知识。
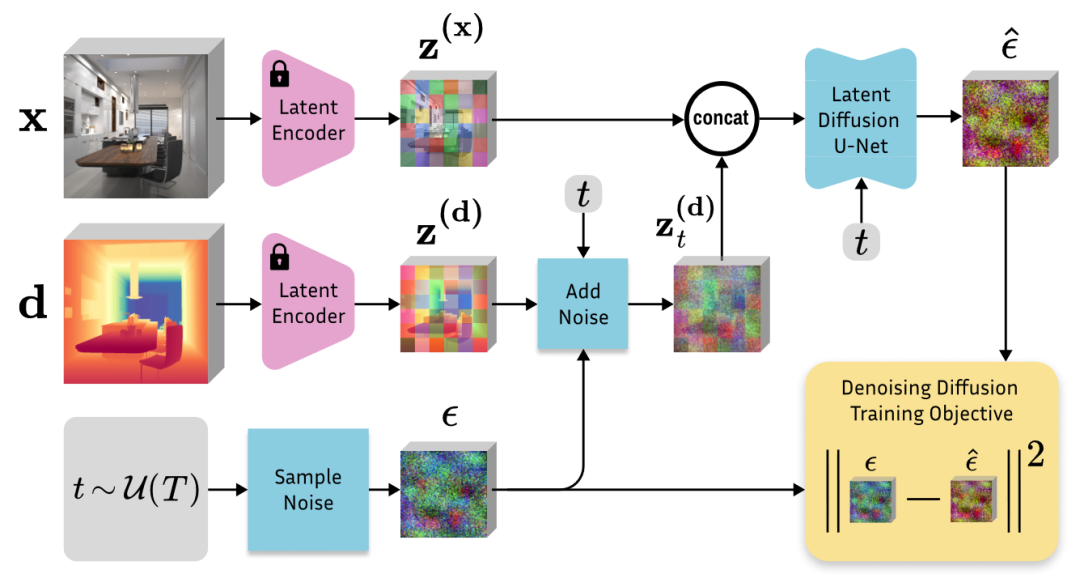
图2. Marigold 微调协议概述。
微调协议
Marigold模型的微调协议旨在利用预训练的潜在扩散模型(LDM)来进行深度估计。通过采用仿射不变深度归一化和训练于合成数据上的策略,模型能够有效地适应和学习从单一GPU上的短期训练中获得的合成RGB-D数据,这种数据无需复杂的预处理。此外,使用多分辨率噪声和退火调度的策略进一步提高了训练效率和模型性能。这一协议不仅提高了深度估计的准确性,还确保了模型对新场景的良好泛化能力,展示了在有限资源下通过微调预训练模型达到先进性能的可能性。
实验过程
Marigold模型推理时,模型通过逐步去除输入噪声来重构深度图,从一个随机噪声初始化开始,依次应用学习到的去噪操作。此外,为了提高预测的一致性和精度,研究者还提出了一个测试时集成方案,通过多次推理并聚合结果来优化最终深度预测。这种方法的实施,加上模型的生成性质和基于潜在空间的操作,使得Marigold在实际应用中能够有效地处理和优化深度估计任务。
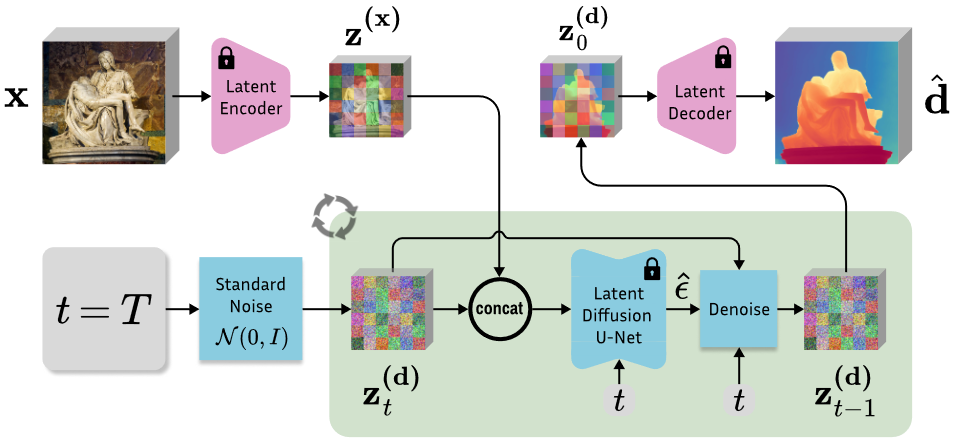
图3. Marigold 推理方案概述。
研究结果
实施细节
利用 Stable Diffusion v2 作为骨干并禁用文本调节。训练期间,应用具有 1000 个扩散步骤的 DDPM 噪声调度器。在推理时,应用 DDIM 并采样 50 个步骤。对于最终预测,汇总 10 次具有不同起始噪声的推理运行的结果。使用 32 的批量大小迭代 18000 次。为了适合一个 GPU,我们梯度累积步骤 16 ,使用Adam 优化器学习率为 3e−5 。此外,对训练数据应用随机水平翻转。在单个 Nvidia RTX 4090 GPU上,训练耗时大约需要 2.5 天。
评估
训练集:Marigold模型在两个合成数据集上进行训练:Hypersim 和 Virtual KITTI。Hypersim 数据集包含461个室内场景的高分辨率图像和深度图,而 Virtual KITTI 数据集模拟不同天气和摄像头视角下的街景环境。这些数据集提供了丰富的环境和控制条件下的数据,有助于模型学习和预测深度信息。
评估集:使用五个未见过的真实世界数据集,包括两个室内场景数据集(NYUv2 和 ScanNet)和三个室外场景数据集(KITTI、ETH3D 和 DIODE)。这些数据集通过RGB-D Kinect传感器或LiDAR传感器收集,涵盖从住宅室内到复杂城市街景的多种环境。
评估协议:通过最小二乘拟合方法对预测的深度图进行仿射变换校正,以对齐到真实深度图。性能指标包括绝对平均相对误差(AbsRel)和一致性度量(δ1精度),这些指标能够有效评价深度预测的质量和精度。
与其他方法对比:Marigold模型与其他几种声称具有零样本泛化能力的方法进行比较,以展示其在不同基准测试中的性能。通过这种对比,研究者展示了Marigold在处理多种复杂场景时,提供更准确和可靠的深度信息的能力,通常超越了其他现有方法,尤其是在室外和挑战性环境中的表现更为突出。
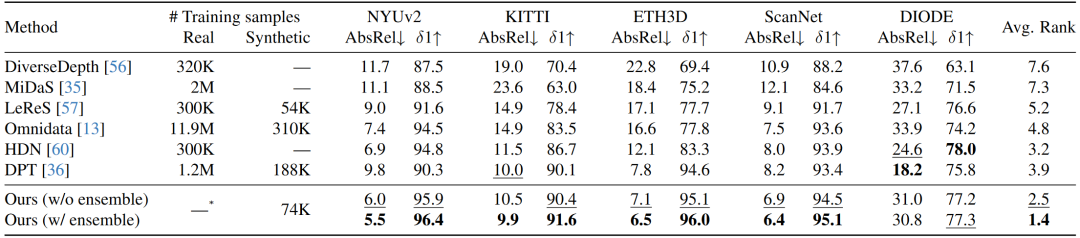
表1. 在几个零样本基准上对 Marigold 与 SOTA 仿射不变深度估计器进行定量比较。粗体代表最佳指标,下划线次之。
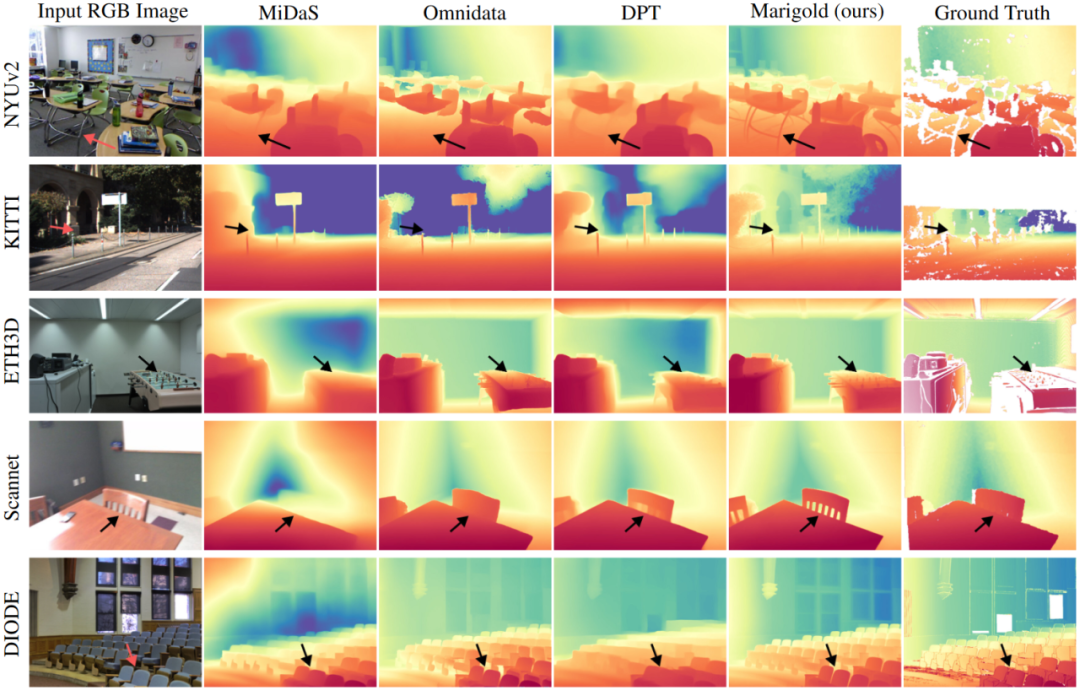
图4. 不同数据集的单目深度估计方法的定性比较(深度)。
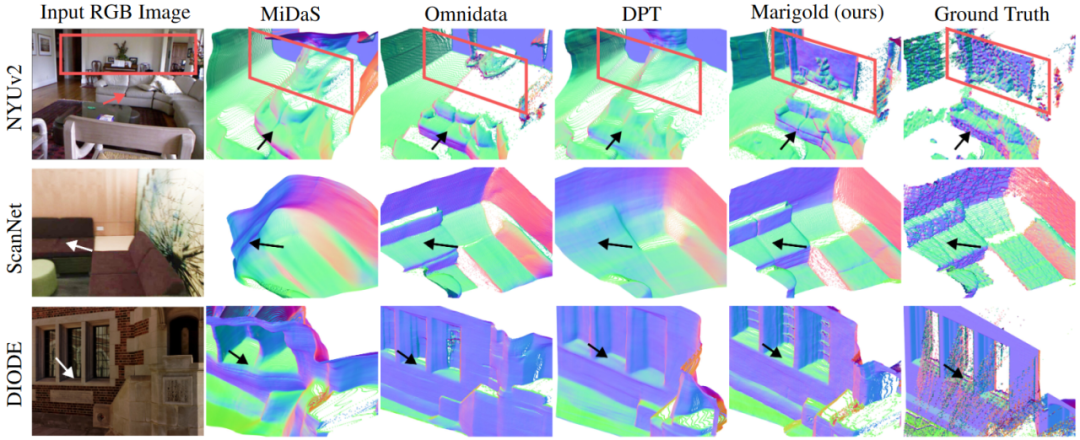
图5. 不同数据集的单目深度估计方法的定性比较(未投影,颜色为法线)。
消融研究
训练噪声
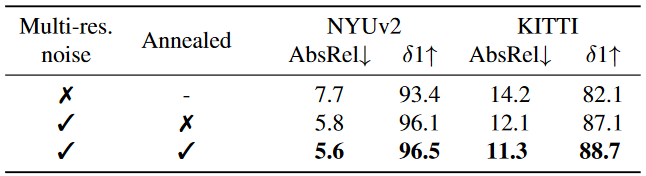
表2. 训练噪声消融。多分辨率噪声比高斯噪声有所改善;退火效益进一步提高。
训练数据域
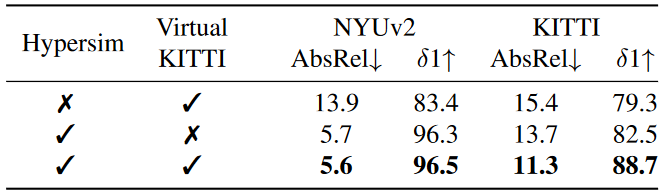
表3. 训练数据消融。Hypersim提供了强劲的结果;KITTI提高了户外性能。
测试时集成
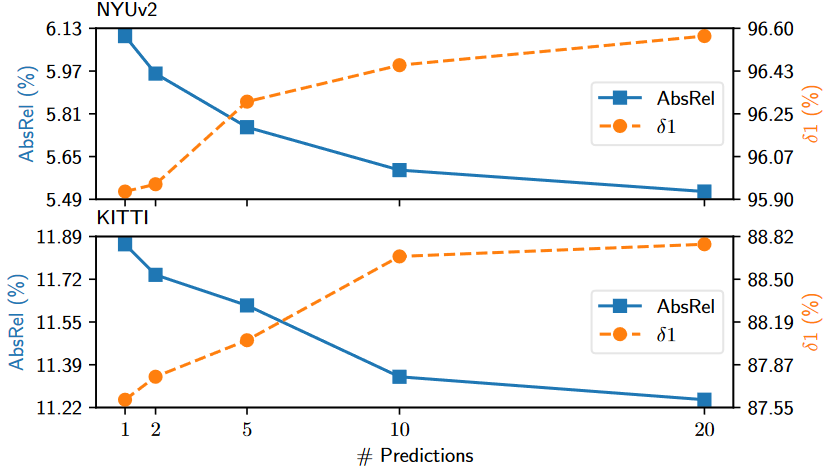
图6. 集合规模消融。随着集合规模的增长而单调改进。每个样本进行 10 次预测后,这种改进开始减弱。
去噪步数
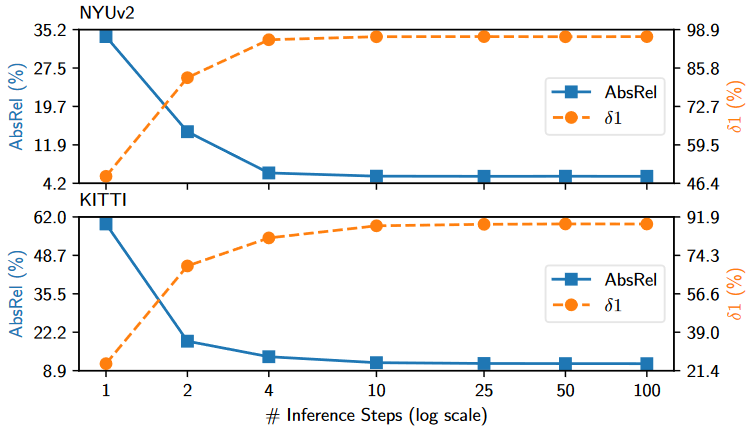
图7. 去噪步数消融。随着去噪步数的增加,性能会提高,10 步后性能趋于饱和。
主要结论
研究发现,通过利用预训练的文本到图像的潜在扩散模型(LDM),Marigold成功地将深度学习的强大视觉场景理解能力应用于单目深度估计任务,实现了在多个真实世界数据集上的优异性能。这一成果不仅证明了使用生成模型进行视觉任务的有效性,也展示了通过简单的微调协议可以显著提升深度估计的准确性和泛化能力。
一句话总结:本研究通过将预训练的图像生成扩散模型微调应用于单目深度估计,展示了利用丰富的视觉先验知识显著提升深度估计性能的可能性,并在多个数据集上实现了优异的泛化能力。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer5555,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
















 221
221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









