







很不幸这篇论文收藏很多但是没有复现教程 ·_·
试过docker但是一直run不起来
本机配置
一、配置环境
WSL2+Ubuntu22.04
本来像安装一个远程连接图像界面的但我失败了https://www.bilibili.com/video/BV1AV4y1K7Xe/?vd_source=48468d37677304f7842732d50721bc9c
详细攻略 WIN11 + WSL2+ Ubuntu22.04+CUDA + MINICONDA3+Pytorch安装踩坑总结,手把手教学,看不会你打我
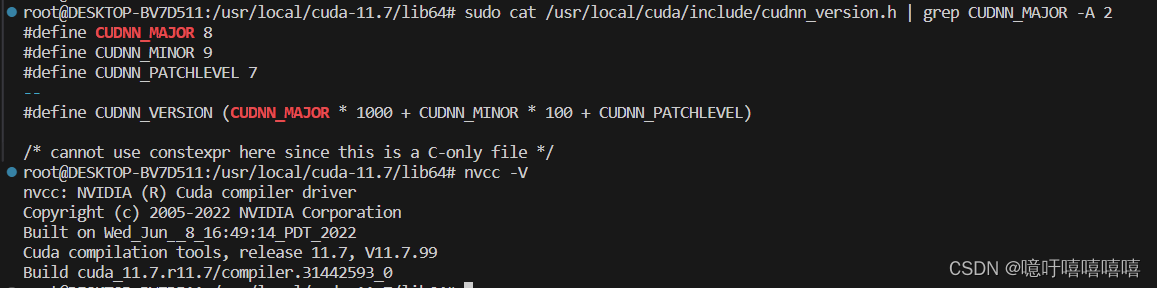
Cuda11.7+cudann
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.7.1/local_installers/cuda-repo-wsl-ubuntu-11-7-local_11.7.1-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-11-7-local_11.7.1-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-11-7-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda
MINICONDA3+Pytorch安装(先别用conda创建环境,我建议用Manba,原因后续提出)
详细攻略 WIN11 + WSL2+ Ubuntu22.04+CUDA + MINICONDA3+Pytorch安装踩坑总结,手把手教学,看不会你打我
二、在本机code编写代码
在powershell或者cmd中以管理员运行,输入wsl进入ubuntu系统,输入code .等待下载好后会在本机跳出vscode,等待它加载远程连接。
你的代码可以直接粘贴到ubuntu中
三、拉取代码创建conda / mamba环境
拉取代码
git clone https://github.com/prs-eth/Marigold.git
cd Marigold
方法一:conda方法
我没有用mamba或者pip 我有罪!我该用!后面看mamba使用方法
conda create -n marigold python=3.10
conda activate marigold
方法二:mamba方法
由于我在尝试train之前组织数据的时候一直在报错,我心想不至于吧!但我怀疑是因为我包之间有冲突导致的,于是我重新用mamba环境配置,就没报错了555(也可能是技术不精进我也看不出来哪里包有冲突,但我猜测是因为numpy和h5py那里出错了)
conda install mamba # 这个在base安装就可以
mamba init # 初次使用mamba需要
mamba env create -n marigold --file environment.yaml
conda activate marigold
这里虽然environment.yaml制定了cuda,但是安装后居然是cpu,再次运行下面命令安装cuda版本:
pip install torch==2.0.1+cu117 torchvision==0.15.2+cu117 torchaudio==2.0.2 -f https://download.pytorch.org/whl/torch_stable.html
这里之后两个方法都一样了
安装其他依赖
pip install -r requirements.txt -r requirements+.txt -r requirements++.txt
查看torch是否安装成功

整个文件结构如下:
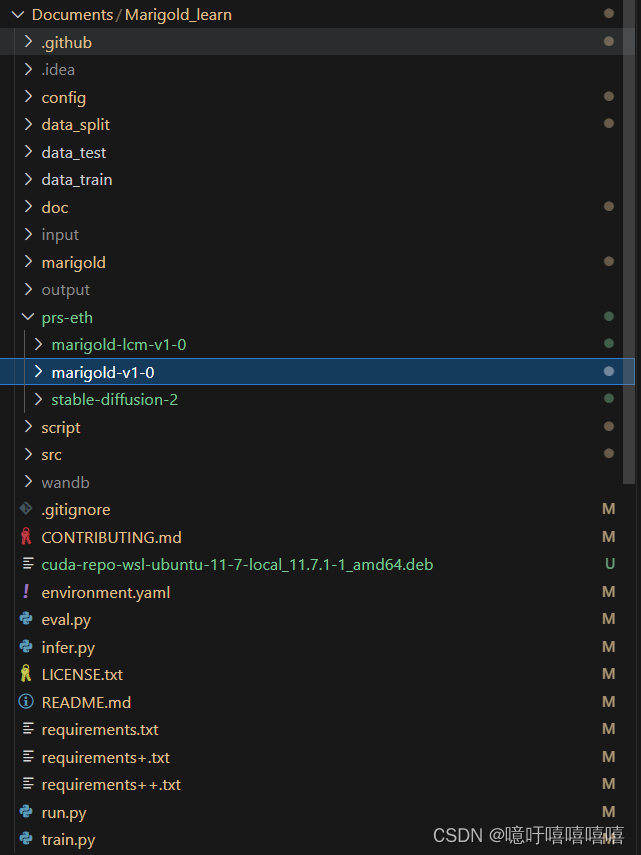
请注意文件结构不要错了,不然会有很多路径问题
四、Test
下载测试图片,下载到 input/in-the-wild_example
bash script/download_sample_data.sh
作者给了两个checkpoint
# 方法一
bash script/download_weights.sh marigold-lcm-v1-0
python run.py --input_rgb_dir input/in-the-wild_example --output_dir output/in-the-wild_example_lcm
# 方法二
bash script/download_weights.sh marigold-v1-0
python run.py --checkpoint prs-eth/marigold-v1-0 --denoise_steps 50 --ensemble_size 10 --input_rgb_dir input/in-the-wild_example --output_dir output/in-the-wild_example
参数解释:

run的时候报错如下:
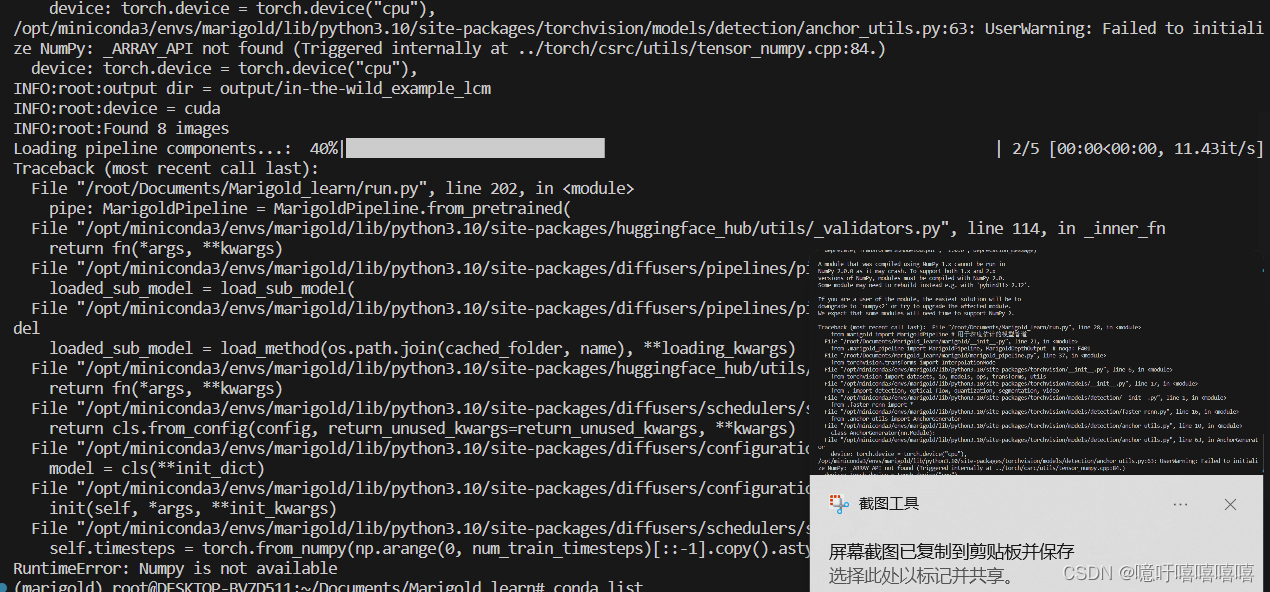
尝试重新conda install numpy解决问题(我猜就是这里把conda环境改坏了)
test结果如下:
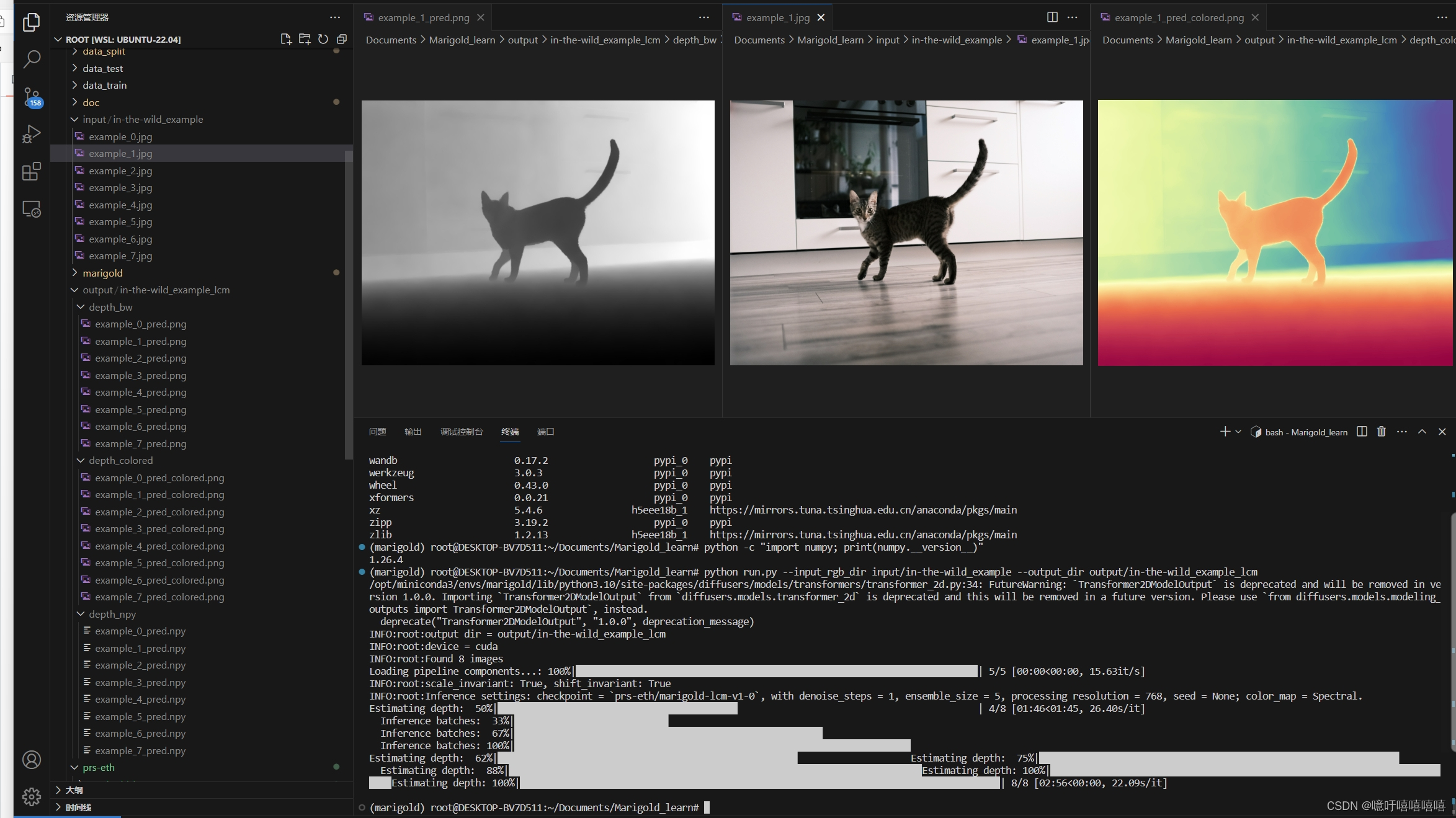
五、Train
真的下了很多东西。。。最后却以爆显存而告终。。。
hypersim数据组织
- 首先在官网中找到dataset_download_images.py并下载,下载后运行py文件。
我这里只尝试下载了三个数据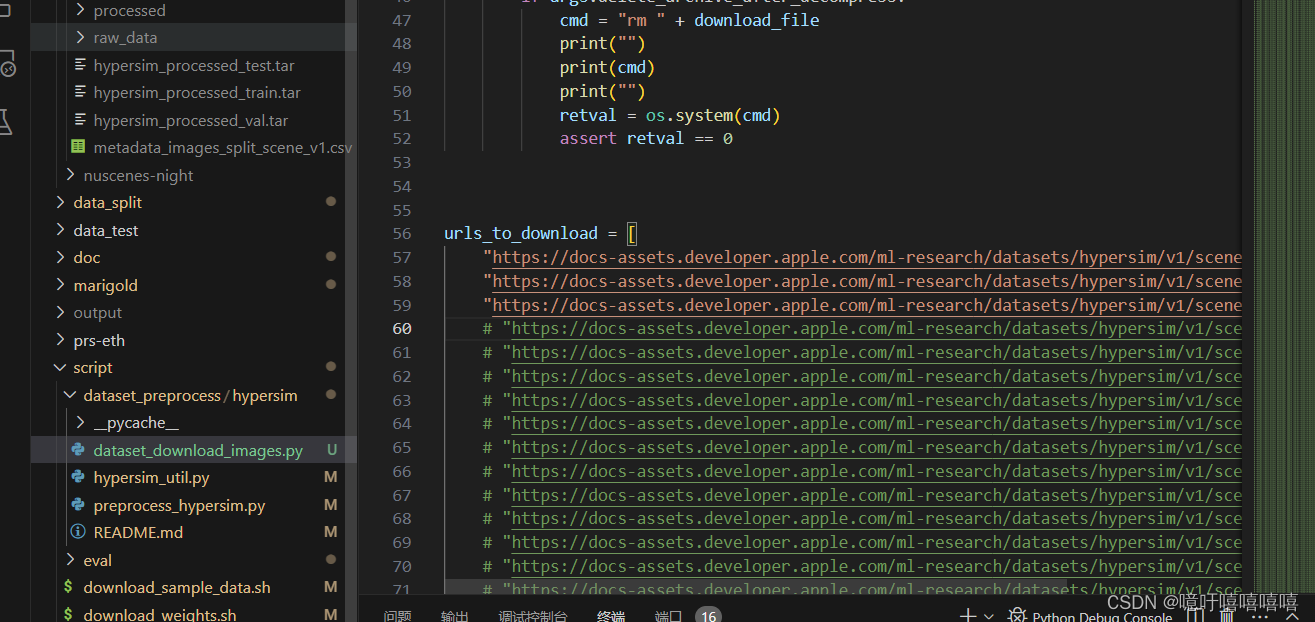
- 再下载分割图片所需要的csv文件
- 根据下载的数据修改一些文件:
- 修改metadata_images_split_scene_v1.csv文件为你有的数据,适当更改split_partition_name
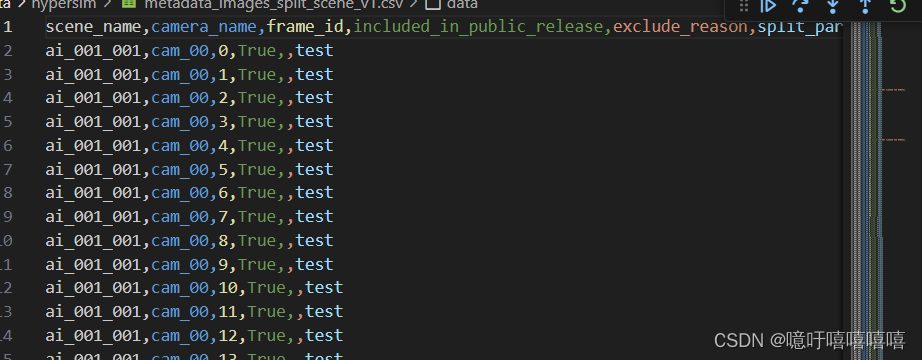
- 修改preprocess_hypersim.py文件中的路径然后运行该文件
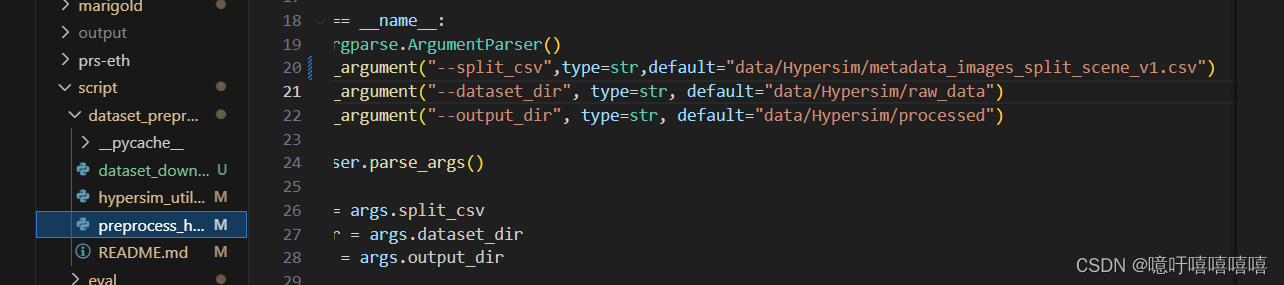
- 得到的数据结构如下,并将其process文件夹中的各个分割文件打包
cd data/Hypersim/processed/train tar -cf ../../hypersim_processed_train.tar .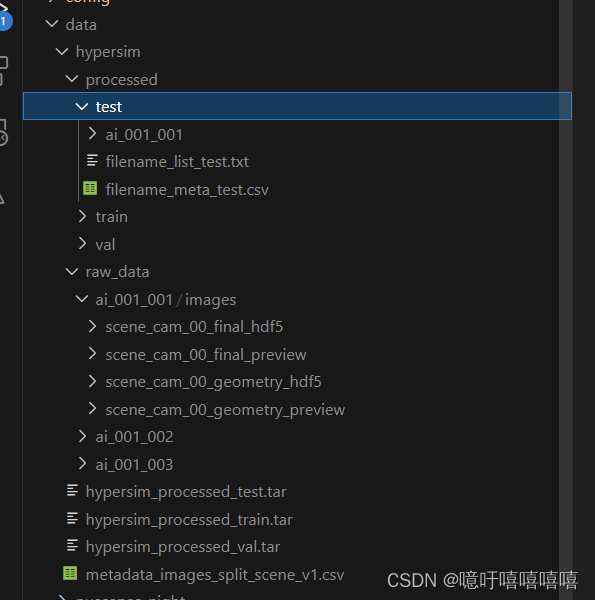
- 修改data_split/hypersim里面的数据文件以适应你自己的数据
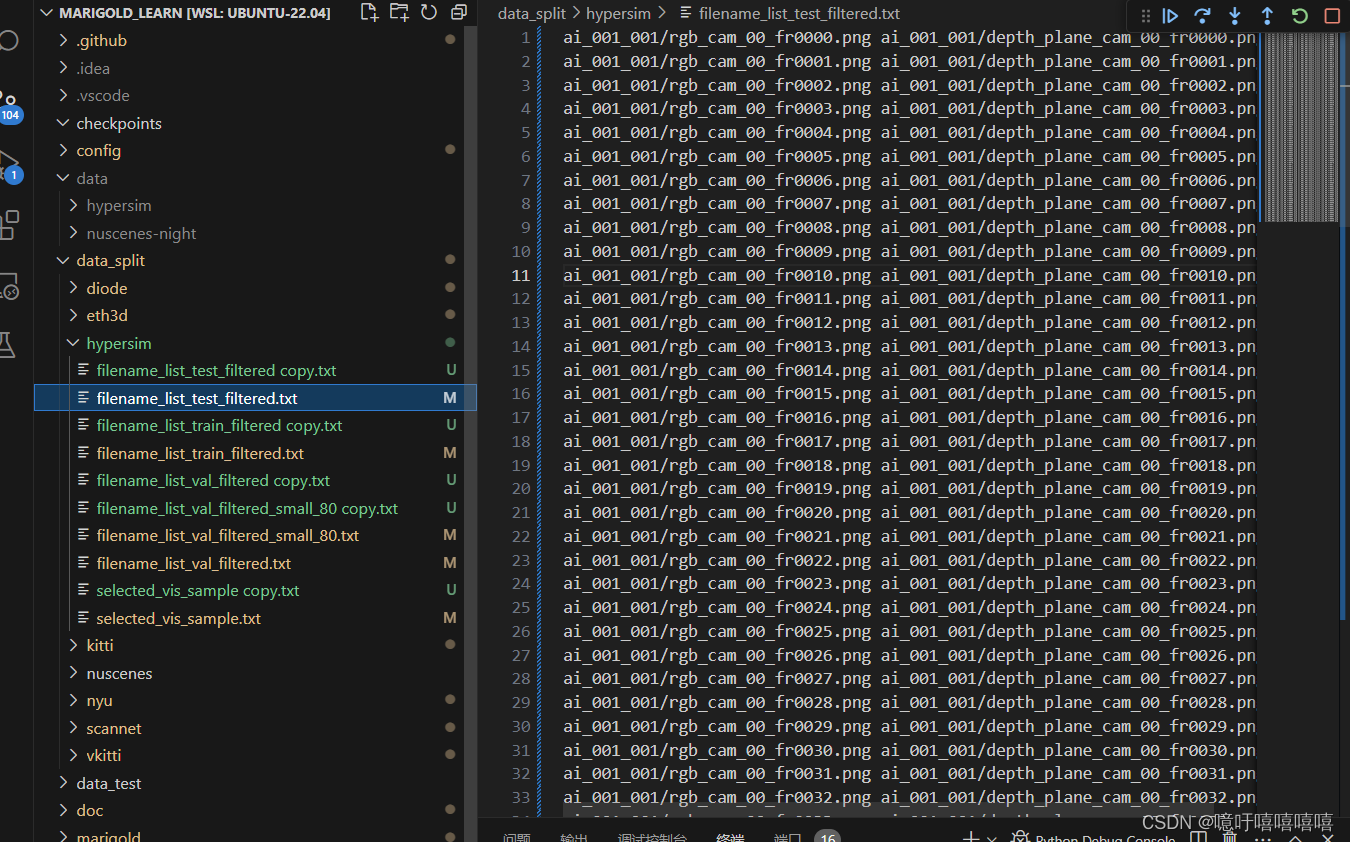
- 修改config中的配置文件
- dataset_train.yaml
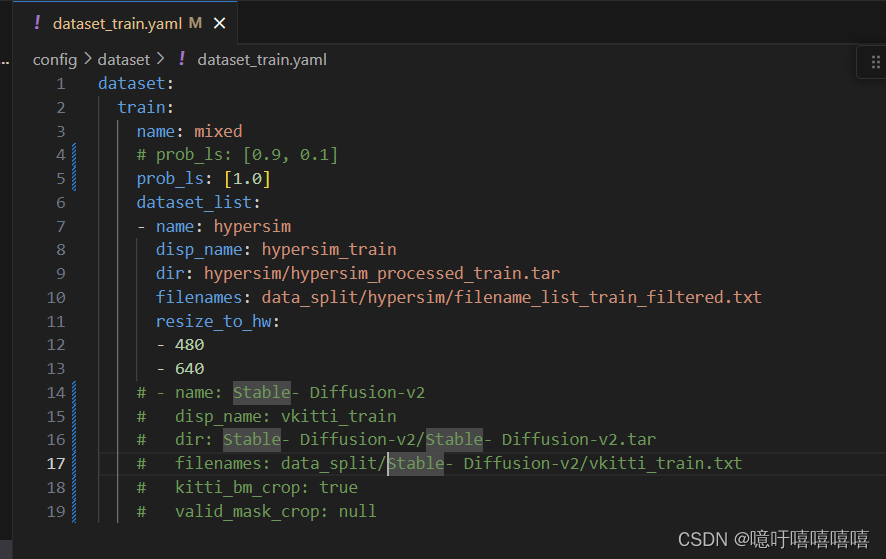
- dataset_val.yaml
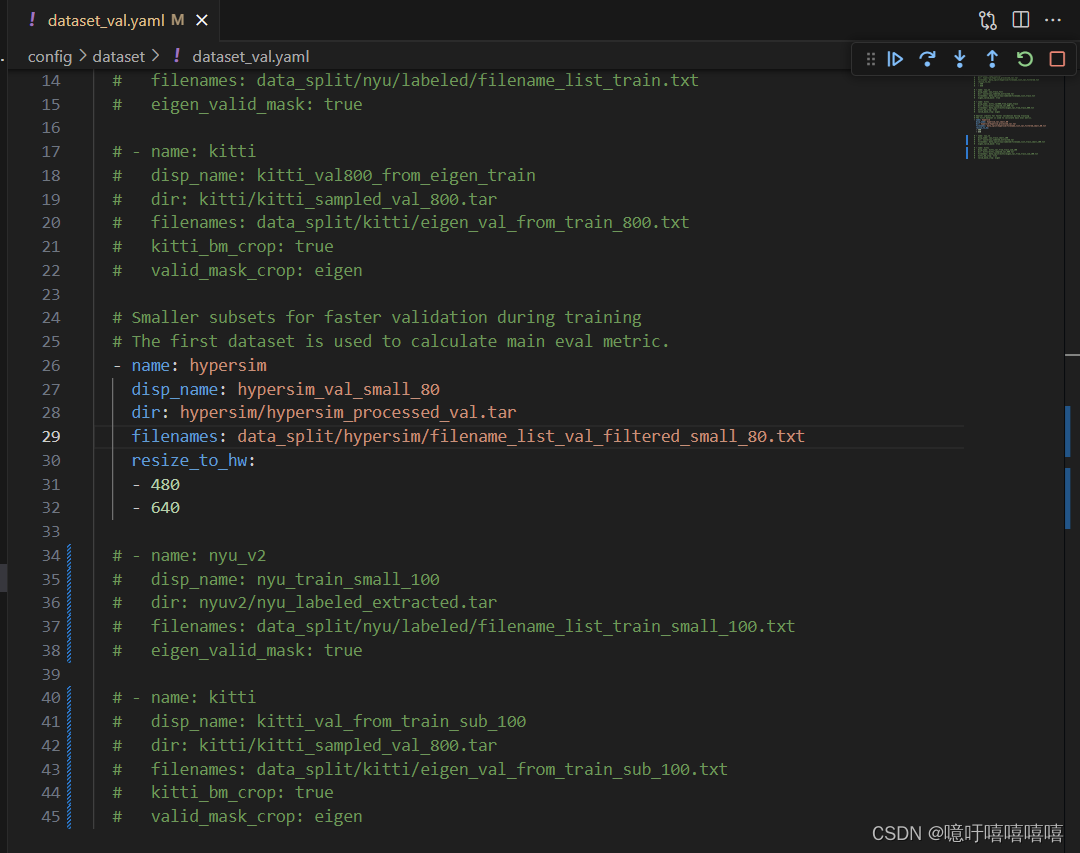
- dataset_train.yaml
- 修改metadata_images_split_scene_v1.csv文件为你有的数据,适当更改split_partition_name
- 官网下载stable-diffusion-2。
注意有些文件过大不会下载需要自己把他下载下来。权重文件我之前用的512的,结果贼慢,后来看到vae里面的配置文件写的768*768,所以换成了768快了很多。好吧后来我发现没有这个文件也可以运行

开始训练
代码使用了wandb网站,点进它的链接注册登录就可以了,然后再点下方的认证链接就会有一个认证码,复制到相应地方就可以继续了。
```bash
python train.py --config config/train_marigold.yaml
```
接下来就报错了:
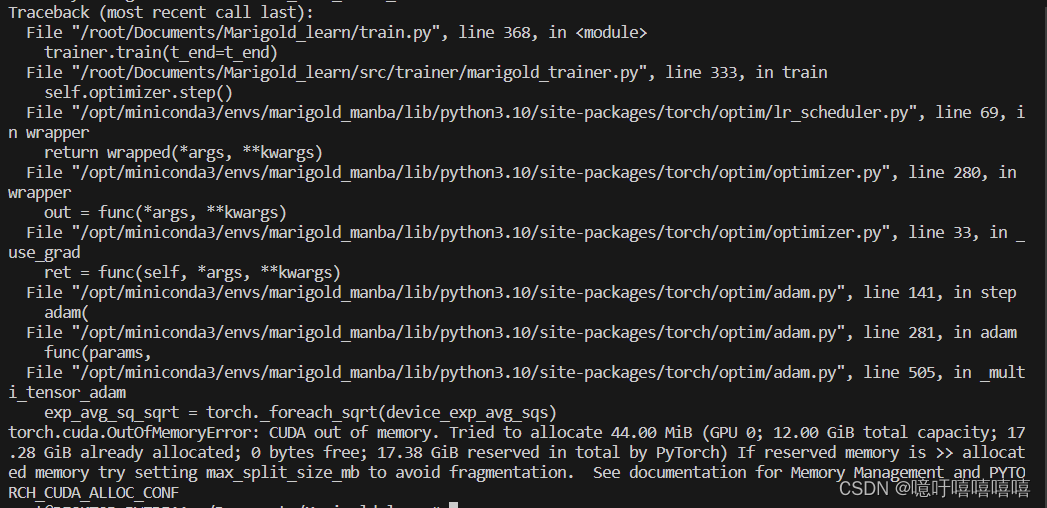
查找了很多解决方法都无效:
- pytorch: 四种方法解决RuntimeError: CUDA out of memory. Tried to allocate … MiB
- Pytorch运行错误:CUDA out of memory处理过程
- 通过设置PYTORCH_CUDA_ALLOC_CONF中的max_split_size_mb解决Pytorch的显存碎片化导致的CUDA:Out Of Memory问题
有没有大佬能帮忙解决一下,不然就只有放在服务器上去了。但是服务器大家都在用555
服务器配置
现在我已经连接好服务器,记得配置一下代理之类的
一、将本机内容传到服务器
运行命令:
scp -r source_folder(你自己指定你的文件夹名称) 用户名@服务器的ip地址:/remote/path/
服务器ip地址通过ip addr命令可以查看
二、配置vscode远程服务器
跟着下面的教程做:
并且给vscode的扩展里面安装python和debug,给本机和ssh都装上
三、配置服务器上的conda环境
Ubuntu 22.04 LTS, Python 3.10.12, CUDA 11.7
1. 安装miniconda
上面有讲
2. 配置项目的conda环境
(1)创建marigold环境
还是使用mamba
conda install mamba # 这个在base安装就可以
mamba init # 初次使用mamba需要
mamba create -n marigold python=3.10
mamba activate marigold
(2)conda下安装cuda
由于服务器上面我不能安装CUDA,只能在conda上安装cuda。由于原论文是在环境Ubuntu 22.04 LTS, Python 3.10.12, CUDA 11.7中做的,所以我也安装的cuda11.7.
跟着下面的教程做:
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/linux-64/cudatoolkit-11.7.1-h4bc3d14_13.conda
conda install --use-local cudatoolkit-11.7.1-h4bc3d14_13.conda
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/linux-64/cudnn-8.9.7.29-hcdd5f01_2.conda
conda install --use-local cudnn-8.9.7.29-hcdd5f01_2.conda
(3)安装其他依赖
pip install torch==2.0.1+cu117 torchvision==0.15.2+cu117 torchaudio==2.0.2 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt -r requirements+.txt -r requirements++.txt
注意:请使用1.26.4版本的numpy,否则会出错。
(4)检查torch是否安装正确以及cuda版本
python
import torch
torch.cuda.is_available()
torch.version.cuda
四、Train
设置不了全局变量BASE_DATA_DIR和BASE_CKPT_DIR的,直接更改参数中的base_data_dir和base_ckpt_dir的默认值,或者在命令行加入参数。

运行:
python train.py --config config/train_marigold.yaml

















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









