






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

转载自:AI科技评论

视觉基础模型与文生视频成为 CVPR 2024 两大热点。
作者丨赖文昕 马蕊蕾 编辑丨陈彩娴
北京时间今天凌晨,美国西雅图正在召开的计算机视觉盛会 CVPR 2024 正式公布了最佳论文等奖项。
今年共有 2 篇论文获得了这份全球最重要的计算机视觉领域的大奖,团队成员分别来自谷歌研究院、加州大学圣地亚哥分校、南加州大学、剑桥大学及布兰迪斯大学。
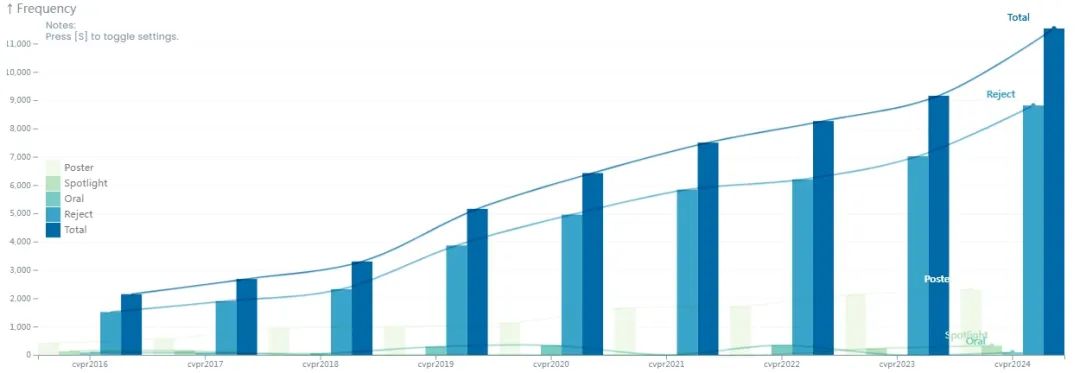
本周(6.17-6.21),第四十一届国际计算机视觉与模式识别会议(CVPR)在美国西雅图拉开帷幕。根据CVPR官方的最新公告,CVPR 2024已经成为该会议历史上规模最大、参与人数最多的一届,截止6月19日,现场参会人数已超过一万两千人。
作为计算机视觉乃至人工智能领域最具学术影响力的三大顶会之一,第一届 CVPR 会议要追溯到1983年美国华盛顿,自此每一年都会吸引全球的计算机研究者和行业领袖汇聚一堂,共同探讨计算机视觉领域最新的科学进展和产业成果。
作为领先的计算机视觉盛会,会议每年都会录用当前视觉领域的最新研究。早在2月27日,CVPR 官网就公布了今年的论文接收结果:CVPR 2024 共有 35691 位注册作者,11532 篇提交论文,其中 2719 篇被接收,录用率为 23.6%。
与之相比,CVPR 2023 共有 9155 篇论文被提交,2359 篇论文被接收,录用率为 25.8%。今年的论文数量提高了20.6%,创下新高,而录用率降低了 2.2%。另外,hightlights 和 Oral 两种类型的论文展示分别有 324 篇(占2.81%)和 90 篇(占0.78%)论文获选,由此可见,本届会议的热度、竞争难度与入选获奖的含金量都有所上升。
1
CVPR 2024 颁奖环节
入围 CVPR 2024 决赛圈的最佳论文有24篇,相比去年多了12篇。

AI 科技评论梳理了候选论文的基本情况:
从地理位置上来看,位列前三的国家依次为美国、中国和德国;从研究领域来看,主要聚焦在视觉与图形、单视图 3D 重建以及图像与视频合成等;从产业界来看,有三家机构入选,分别是 NAVER Cloud AI、Google Research 以及 NVIDIA;从学术界来看,高校依旧是研究的主要推动力,其中,国内入选的高校有北京大学、上海交通大学、中山大学和深圳大学。
最佳论文
本届 CVPR 总共评选出 2 篇最佳论文。
第一篇最佳论文属于谷歌研究院团队的《Generative Image Dynamics 》。

论文链接:https://arxiv.org/pdf/2309.07906
代码地址:http://generative-dynamics.github.io/
作者:Zhengqi Li, Richard Tucker, Noah Snavely, Aleksander Holynski
论文介绍:本文通过从真实视频中提取自然振荡动态的运动轨迹来学习图像空间中的场景运动先验。该方法利用傅里叶域对长期运动进行建模,通过单图像预测频谱体积,进而生成整个视频的运动纹理,可应用于将静态图像转化为循环视频,或通过图像空间模态基实现用户与真实图像中对象的交互,模拟其动态。
第二篇最佳论文颁给了由加州大学圣地亚哥分校、谷歌研究院、南加州大学、剑桥大学及布兰迪斯大学 5 所机构共同发表的《Rich Human Feedback for Text-to-Image Generation 》。

论文链接:https://arxiv.org/pdf/2312.10240
代码地址:https://github.com/google-research/google-research/tree/master/richhf_18k
作者:Youwei Liang, Junfeng He, Gang Li, Peizhao Li, Arseniy Klimovskiy, Nicholas Carolan, Jiao Sun, Jordi Pont-Tuset, Sarah Young, Feng Yang, Junjie Ke, Krishnamurthy Dj Dvijotham, Katherine M. Collins, Yiwen Luo, Yang Li, Kai J. Kohlhoff, Deepak Ramachandran, Vidhya Navalpakkam
论文介绍:许多生成的图像仍然存在诸如不真实性、与文本描述不一致以及审美质量低等问题。本文通过选择高质量的训练数据进行微调来改进生成模型,或者通过创建带有预测热图的掩模来修复问题区域。值得注意的是,这些改进可以推广到用于收集人类反馈数据的图像之外的模型(Muse)。
最佳学生论文
今年的最佳学生论文同样有 2 篇工作获选。
第一篇颁发给了来自德国图宾根大学、图宾根 AI 中心、上海科技大学及布拉格捷克技术大学共同发表的《Mip-Splatting: Alias-free 3D Gaussian Splatting》。值得注意的是,该篇论文的三位华人作者都是上海科技大学在读或毕业的硕士、博士生。

论文链接:https://arxiv.org/pdf/2311.16493
代码地址:https://github.com/autonomousvision/mip-splatting
作者:Zehao Yu , Anpei Chen, Binbin Huang , Torsten Sattler , Andreas Geiger
论文介绍:3D高斯点染技术在新视角合成方面取得了高保真度和效率的成果,但在改变采样率时会出现伪影。问题根源在于缺少3D频率约束和2D膨胀滤波器的使用。为解决此问题,本文引入了基于最大采样频率的 3D 平滑滤波器,限制了高斯基元的大小,消除了放大时的高频伪影。同时,用 2D Mip 滤波器替代 2D 膨胀,模拟 2D 盒滤波器,减轻了混叠和膨胀问题。评估结果显示,在单尺度训练和多尺度测试下,该方法有效。
第二篇最佳学生论文颁发给了来自美国俄亥俄州立大学、微软研究院、加州大学欧文分校、伦斯勒理工学院共同发布的《BioCLlP: A Vision Foundation Model for the Tree of Life》。

论文链接:https://arxiv.org/abs/2311.18803
代码地址:https://imageomics.github.io/bioclip/
作者:Samuel Stevens, Jiaman (Lisa) Wu, Matthew J Thompson, Elizabeth G Campolongo, Chan Hee (Luke) Song, David Edward Carlyn, Li Dong, Wasila M Dahdul, Charles Stewart, Tanya Berger-Wolf, Wei-Lun (Harry) Chao, Yu Su
论文介绍:自然界图像的丰富性为生物信息学提供了宝贵数据源。尽管针对特定任务的计算方法和工具不断涌现,但它们通常不易适应新问题或扩展到不同背景和数据集。为应对这一挑战,本文创建了 TreeOfLife-10M 数据集,这是迄今为止最大和最多样化的生物图像数据集。BioCLIP 模型基于生命树构建,利用 TreeOfLife-10M 的多样化生物图像和结构化知识,展现出在细粒度生物分类任务中的卓越性能,显著超越现有基线方法,其内在评估揭示了 BioCLIP 的强泛化能力。
其他奖项
本届黄煦涛纪念奖由 Andrea Vedaldi 获得。

Andrea Vedaldi 是牛津大学计算机视觉和机器学习教授,也是 VGG(视觉几何)组的成员。他的研究重点在于开发计算机视觉和机器学习方法,以自动理解图像和视频内容。此外,他还在 2012 年至 2023 年期间担任 Facebook AI Research(FAIR)的研究科学家,并在2023年成为 Meta AI 的研究科学家。
2
图像视频生成占领C位
从近期乔治亚理工学院计算机学院(College of Computing, Georgia Institute of Technology)对 CVPR 2024 录用数据的统计分析来看,论文主要涵盖36个主题领域,排名前十的主题分别是:图像和视频合成与生成,三维视觉,人体行为识别,视觉、语言与语言推理,底层视觉,识别(分类、检测、检索),迁移学习与多模态学习。
其中,除了自动驾驶与三维视觉这两位热点常客外,今年排在首位的关键词是图像和视频合成与生成(Image and video synthesis and generation),总计有 329 篇论文,成为了今年 CVPR 最火的研究主题。
热门主题从去年的扩散模型(Diffusion models)转变为今年的图像和视频合成与生成,也同 Sora 在春节打响的开门炮遥相呼应。
在被 CVPR 接收的图像和视频合成与生成相关论文中,有不少过去几个月令人惊艳的新科研成果或产品,比如谷歌 DeepMind 和研究院发布的 Instruct-Imagen。
Instruct-Imagen 是一个能够处理异构图像生成任务并在未见过的任务上泛化的模型。有趣的是,谷歌团队引入了多模态指令生成图像的任务表示,以精确地表达一系列生成意图,并使用自然语言将不同的模态(例如文本、边缘、风格、主题等)融合起来,使得丰富的生成意图可以在统一的格式中标准化。

华东理工大学提出的 DisenDiff 注意校准机制也被选为 Oral 文章,他们的工作旨在解决现有的文本到图像(T2I)模型在个性化定制时无法保持视觉一致性和概念交叉影响的问题。
该方法通过引入与类别绑定的学习型修饰符来捕捉多个概念的属性,并在交叉注意力操作激活后分离和加强类别,以确保概念的全面性和独立性。此外,通过抑制不同类别的注意力激活来减少概念间的相互影响。
实验结果表明,DisenDiff 在定性和定量评估中均优于现有技术,并能与 LoRA 和修复管道兼容,提供更丰富的交互体验。

扩散模型在当下可以说主导了图像生成这个领域,也对于大数据集展现出了强大的缩放性,由 NVIDIA 和 Aalto University 的研究人员撰写的《Analyzing and Improving the Training Dynamics of Diffusion Models》,关注点在于改进扩散模型的训练动态。
该篇研究者在不改变 high-level 架构的前提下,识别和纠正了流行的 ADM 扩散模型中的几个训练方面不均匀的原因。把 ImageNet 512×512 图像生成任务的 FID 由原来的 2.41 降低到了 1.81,这是一个衡量生成图像质量的重要指标,将生成质量和模型复杂度变得可视化。
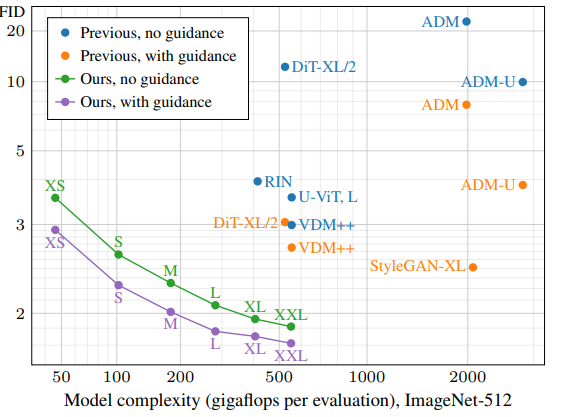
研究者还提出了一种在训练完成后设置EMA参数的方法,允许在不增加多次训练成本的情况下精确调整EMA长度,并揭示了其与网络架构、训练时间和引导的惊人交互作用。
这些突破性的研究,预示着人工智能在图像生成领域,正在以前所未有的速度重塑艺术创作和视觉上内容生产的边界。
值得一提的是,今年恰好是生成对抗网络(GANs)诞生的十周年。2014年,Ian Goodfellow 等人提出了深度学习领域的此项里程碑技术,不仅开辟了生成式模型的新领域,而且对无监督学习产生了深远影响。
3
视觉基础模型点燃现场
基于 Transformer,以及受到语言大模型的启发,计算机视觉领域在 2023 年以来对视觉基础模型(VFM)的研究热情高涨。
视觉基础模型 (VFM),一般在特定的领域,像图像分类、目标检测和图像生成等众多下游任务中表现突出。例如,多模态 CLIP 模型擅长零样本视觉语言理解,自监督学习模型DINOv2 擅长语义分割,自监督学习方法SAM 擅长开放词汇实例分割。
CVPR 2024 共有 123 个 workshop 与 24 场 tutorial,在这个年度盛会的现场,AI 科技评论观察到:尽管视觉基础模型的相关工作在被接收论文数量中的占比不大,但超过 10 场研讨会以视觉基础模型为主题,开展了学习和应用视觉基础模型最前沿方法的讨论。
比如 6 月 17 日举行的第二届基础模型研讨会上,与会者分享了视觉基础模型和大语言模型的理论洞察、高效架构设计、以及卷积和图混合网络设计的研究,并探讨了在图像和视频生成、不同监督学习设置、多模态模型等,还讨论了如何将基础模型的前沿研究成果应用于医疗、地球科学、遥感、生物、农业和气候科学等多个领域,以弥合研究与实际应用之间的差距。

在「视觉基础模型最新进展」的分享会中,嘉宾们讨论了用于多模态理解和生成的视觉基础模型,基准测试和评估视觉基础模型,以及基于视觉基础模型的智能体和其他高级系统。
分享嘉宾:Tiktok-Chunyuan Li
自 2020 年引入视觉 Transformers(ViT)以来,计算机视觉界见证了基于 Transformer 的计算机视觉模型的爆炸性增长,其应用范围从图像分类到密集预测(如目标检测、分割)、视频、自监督学习、3D和多模态学习。
因此,CVPR 2024 中的第三届视觉 Transformer 研讨会将会议重点放在了为视觉任务设计 Transformer 模型的机遇和其开放性挑战之中。
机器遗忘(Machine Unlearning,也称遗忘学习)对基础模型的重要性同样不言而喻,专注于从预训练模型中剔除那些不再需要的数据,如个人隐私信息或违反法规的数据,并确保模型继续发挥其应有的功能而不受影响,因此 CVPR 2024 中也有研讨会集中讨论视觉基础模型中机器遗忘的运用。
而 3D 基础模型的发展正成为自然语言处理和 2D 视觉之后的又一场技术革命,预示着在 3D 内容创作、AR/VR、机器人技术和自动驾驶等领域的广泛应用前景。CVPR 2024 的研讨会还邀请了 3D 视觉领域的专家,共同探讨 3D 基础模型的构建,包括数据集的选择、模型应针对的3D任务、架构共识以及潜在应用。
此外,基础模型还被视为构建更通用自主系统的新路径,因其能够从大量数据中学习并泛化到新任务。CVPR 2024 中有研讨会关注自主系统,探究基础模型对自主代理的潜力,与会者们认为未来在于可解释的、端到端的模型,这些模型能够理解世界并泛化到未访问的环境中。
CVPR 2024 的现场中还有研讨会探讨了对抗性机器学习的最新进展和挑战,重点关注基础模型的鲁棒性,该 workshop 还组织了一场针对基础模型的对抗性攻击挑战。
有的研讨会则聚焦于医学成像领域基础模型的集成和应用,讨论涵盖了各种医学数据的最新技术,如超声心动图、眼底、病理学和放射学,以及在临床环境中使用基础模型的实际挑战。
4
写在最后
两天前,Runway 时隔一年推出 Gen-3 Alpha,宣布视频生成赛道王者归来。在 CVPR 2024 的现场,AI 科技评论也听到了关于 GPT-5 或于 3 个月后发布的消息,业内对其推理能力与多模态能力更是报以期待。
那么,计算机视觉还有哪些热点会是未来趋势?图像、视频生成与视觉基础模型的下一步发展在哪里?3D 视觉、自动驾驶等往届「花旦」又有何新动态?机器人与具身智能有无新亮点?
让我们一起期待,CVPR 2024 的精彩仍在继续。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer5555,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









