






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer111,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

作者:liuhs
https://zhuanlan.zhihu.com/p/709576252
本文介绍我们发表在ECCV 2024的新工作:Fully Sparse 3D Occupancy Prediction

之前的3D occupancy工作,大多需要构建一个稠密的3D特征,或者依赖sparse-to-dense模块来做dense prediction,计算量大。本文中我们探索了一个全新的纯稀疏的Occupancy架构,取名为SparseOcc。SparseOcc不依赖任何的dense设计,架构简洁高效,并且可以无缝迁移到全景分割。此外,我们还深入分析了当前评测指标存在的漏洞,并提出了新的指标:RayIoU。代码已经开源在了GitHub:
https://github.com/MCG-NJU/SparseOcc
重要事项
首先,我们要声明一下,市面上还有一个和我们同名的SparseOcc,题目是 "SparseOcc: Rethinking sparse latent representation for vision-based semantic occupancy prediction" (by Tang et al),但内容和本文完全不同。请大家在引用的时候务必做好区分,以下是几个注意点:
我们的题目是 Fully Sparse 3D Occupancy Prediction,我们的题目中没有SparseOcc字样
我们的arxiv ID是2312开头(https://arxiv.org/abs/2312.17118)
我们已经发现了超过3篇存在错误引用的文章,也已经联系他们并指出错误。他们承认了疏忽并表示已经更正。我们在此也恳请大家再三确认好,您所引用的SparseOcc是不是您真正想引用的。
如果您想在Google Scholar上搜索本文,请搜索 Fully Sparse 3D Panoptic Occupancy Prediction。因为我们在后续的更新中,删除了题目中的 Panoptic 一词,而Google scholar的数据库还没有更新,依然显示第一版的标题。在引用时,您选择第一版还是第二版都可以,只要arxiv ID对上就行。非常抱歉带来不便!以后还是尽量不改题目了...x)
SparseOcc
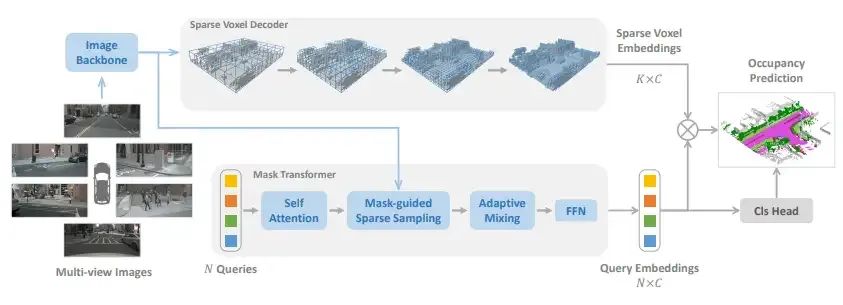
SparseOcc是一个纯稀疏的占用网络。首先,它利用Sparse voxel decoder以从粗到细的方式重建场景的稀疏几何形状。由于这一步仅对non-free区域进行建模,显着节省了计算成本。接着,一个mask transformer使用稀疏的 semantic/instance query来预测稀疏空间中每个segment的mask和label。Mask transformer不仅提高了semantic occupancy的性能,而且为panoptic occupancy铺平了道路。
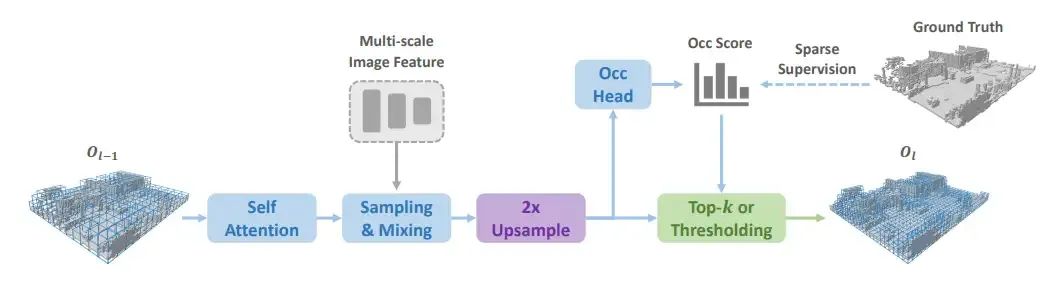
具体来说,在sparse voxel decoder 的每一层中,所有query都是voxel query,他们经过self attention,sparse sampling 和 adaptive mixing (这三个模块来自SparseBEV)之后,会经过上采样和稀疏化这关键的两步。上采样就是把一个voxel分裂成8个(两倍上采样);稀疏化就是根据每个voxel的分数,决定其是否被丢弃。一种做法是卡阈值 (thresholding)。但我们这里用top-k来实现稀疏化,因为这样子样本之间的长度一致,便于多卡多batch训练。测试的时候,可以随时切换thresholding / top-k两种方式。
Mask transformer部分主要就是把原先的cross attention换成了稀疏采样,因为cross attention需要和image中的每一个location交互,属于dense操作。换成稀疏采样之后,我们进一步设计了mask-guided策略,让采样点的生成会依照predicted mask的指导。在此不再赘述。
RayIoU
目前市面上最主流的数据集是Occ3D-nuScenes,它的评估指标是voxel-level的mIoU。并且,他们还提供了一个visible mask,在评测时,只有visible mask=true的区域会被纳入评估。后来,大家发现在训练的时候,用上这个visible mask可以大幅涨点。举个例子,BEVFormer用上visible mask之后,mIoU从24涨到了39,足足15个点。这个现象也在BEVDet-Occ,FB-Occ等等方法中出现。那么自然而然我们就有了疑惑:这真的是来自于性能提升吗?
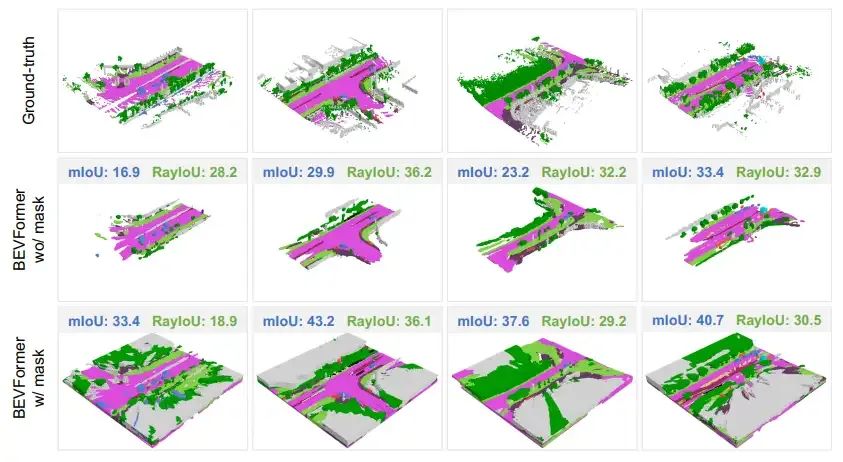
于是,我们拿BEVFormer开刀,train了两个版本,分别是用/不用visible mask。如上图所示,出乎意料的是,用了visible mask之后,我们并没有发现性能有什么真正提升,无非就是墙变厚了,甚至prediction还更加noisy了。然而,Occ3D的mIoU指标却显示有15个点的巨大提升。
究其原因,我们发现,是现在的这个评估指标存在漏洞。简单地说,只要你预测一个厚表面(把墙后面看不见的区域全部填满),你就能轻松获得很高的指标。下图是一个例子:
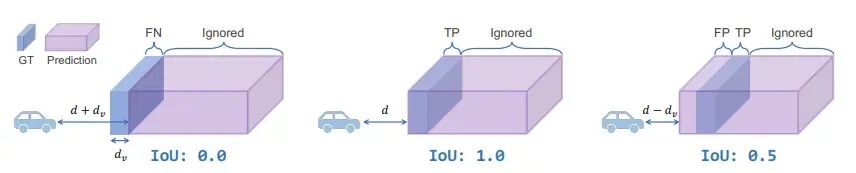
想象我们面前有一堵墙,它到我们的GT距离为 d,且GT的厚度为 dv(这里的dv往往都很小,因为GT是根据LiDAR做的,所有表面都是薄薄的一层)。
当我们预测的墙壁很厚,其 dp ≫ dv 时,我们会遇到深度上的不一致惩罚。具体而言,如果预测的距离比GT更远(总距离为 d + dv,最左边的例子),其 IoU 将为零。相反,如果预测的墙比地面真实值更近(总距离为 d - dv,最右边的例子),IoU 依然会有 0.5。这是因为表面后面的所有体素都被重复填充,并且现在的评估指标会忽略GT之后的区域。类似地,当预测的深度为 d - 2dv 时,得到的 IoU 为 1/3,以此类推。
综上,现在的mIoU指标存在以下几个问题:
如果模型填充了表面后面的所有区域,沿着深度方向的惩罚是不一致的。通过填充表面后面的所有区域,并预测一个更近的深度,模型可以轻松获得更高的 IoU。这种厚表面的现象,在那些使用visible mask或2D监督(比如RenderOcc)训练的模型中非常常见。这会导致和薄表面的方法的对比不公平。
如果预测的占用表示一个薄表面,惩罚会变得过于严格。即使只有一个voxel的偏差,IoU 也会变为零。
Visible mask仅考虑当前时刻的可见区域,将occupancy简化为深度估计任务,忽视了场景补全能力。
于是,我们提出了一个新的评估指标,叫RayIoU(也就是CVPR 2024 自动驾驶挑战赛 Occuapncy 赛道所使用的评估指标)。不同于之前的voxel-level mIoU,我们的RayIoU的基本元素是Ray,也就是光线。我们模拟LiDAR,将Query ray投射到预测的3D occupancy。对于每个查询光线,我们计算它在与任何表面相交之前所经过的距离,并拿到相应的类别标签。一个query ray只有在其类别预测是对的,并且深度的预测误差在一定阈值之内,才算True Positive(TP)。
此外,我们还可以控制query ray的分布。直接模拟LiDAR会导致远近不均匀,所以我们重新平衡了一下光线分布。并且,query ray还可以从过去、未来时刻的ego位置出发,从而更好地评估补全能力。大家可能也发现了,今年挑战赛里,时序建模的涨点会非常多,因为它让补全性能更好了。

FAQ
RayIoU作为今年挑战赛的指标,自问世之后就得到了不少好评。同时,也有一些同行提出了疑问,我们在此收集记录一下:
为什么训练时使用visible mask会导致厚表面?这是因为表面之后的区域不会受到监督,模型就倾向于将这个区域用重复的prediction填满,造成厚墙壁的效果。
RenderOcc 没有使用visible mask,为什么它的预测的表面也很厚?这是因为它用的渲染loss,2D监督,这种loss本身就不监督表面后面的区域,原理和visible mask差不多。
为什么SparseOcc不能利用老指标的漏洞?由于 SparseOcc 采用完全稀疏架构,因此它始终会预测一个薄表面。因此,想要公平对比只有两种办法:(a)使用旧指标,但所有方法都必须预测薄表面,这意味着它们在训练期间不能使用visible mask;(b)使用 RayIoU,因为它更合理,可以公平地比较厚或薄表面。我们的方法在这两种情况下都实现了 SOTA 性能。
RayIoU 是否忽略了物体内部的重建?首先,我们无法获得物体内部occupancy的GT。这是因为GT是通过体素化 LiDAR 点云得出的,而 LiDAR 只能扫描物体的薄表面。其次,RayIoU 中的ray可以来自场景中的任何位置(见上图)。这使得它能够评估整体重建性能,而不像深度估计。我们要指出,RayIoU 的评估逻辑与GT生成过程一致。
那么以后在训练时应不应该用visible mask呢?好问题,我觉得有利有弊。利处是:它解决了LiDAR unscanned区域的歧义问题。毕竟有很多区域只是LiDAR没扫到,并不是真的free,用visible mask能很好解决这个问题。弊处是:它会让深度估计不准。具体可以看我们最新版arxiv文章的More Studies (sec 5.4)一节。因此,我的建议是:用,但是要解决掉它让深度不准的问题。如果仅仅是墙后的区域不监督了,模型自然倾向于预测一个深度更近的表面以达到更低的loss。这一块可以留作future work。
对于较远处的地面,如果Prediction相比于GT只是高了一层voxel(0.4m),那么在经过ray casting之后是否会导致较大的depth error?是的,并且这也是合理的。预测一个准确的地面至关重要,因为occupancy的主要应用价值就是处理不规则物体(包括地面的坑洞,凸起)等。对于模型来说,这可能难了一点,但这不是RayIoU的问题,这是现在的 voxel 表达形式太粗糙(只有0.4m的精度)的问题。未来可以采用更细粒度的voxel(小米都用0.1m了),或者用点云来表示occupancy(下面会介绍),或者用连续曲面来建模地面。
为什么要逐光线算L1误差,而不是对打完光线得到的点云直接算Chamfer distance?因为我们当时还要办比赛。办比赛的时候有一个硬件限制,就是服务器上只有CPU,没有GPU。算chamfer distance的复杂度太高了,评测一次就要10个小时,到时候大家又要骂街了。无奈采用了L1误差,并且还要求了大家在本地打完光线再提交:) 我们也觉得chamfer distance是更合理的,未来大家可以自行修改尝试。
Limitations
累积误差。在sparse voxel decoder中,早期被丢掉的voxel再也回不来了。
部署问题。由于网络中存在一些自定义算子(稀疏采样等),因此目前部署还存在难题。对于工业界的同学,我更推荐另一个同期工作 FlashOcc和最近新出的 Panoptic FlashOcc
Future Work
SparseOcc 作为第一个纯稀疏框架,未来还有很多进步空间。在此列举一些:
解决累积误差问题。现版本最大的问题应该就是累计误差,早期被丢掉的voxel再也回不来了。因此可以设计一种growing机制,或者仿照gaussian splatting的density control机制,来解决这个问题。
换掉voxel的表达形式。抛弃离散,voxel那一套东西,用点云表示occupancy。点云的坐标是连续的浮点数,然后通过预测一个offset来移动点云(就像DETR系列一样)。监督就用chamfer distance,更加soft。最后这个预测出来的点云还可以转成mesh,非常灵活。相比于voxel,纯点云的粒度可以做的无限细。难点在于点云密度很高,两两做self attention代价昂贵。而且,如何解决unscanned区域的歧义也是个问题。voxel方法可以通过visible mask解决,但是point-based方法就不好说了。本来在2023年12月挂出第一版之后就想做这个方案的,但后来发现评估指标才是目前最大的痛点。这个方案也就搁置了。
用RayIoU实现跨数据集评测。现在市面上一大堆基于nuscenes的occupancy数据集,比如Occ3d, OpenOcc, OpenOccupancy, SurroundOcc等等,讲道理他们都区别不大。后来,有的方法它在A数据集上做的,有的方法又是在B数据集做的,没法公平对比,很烦人。但现在,我们可以通过RayIoU来实现跨数据集统一评测。只要改一处地方:每根光线,打到predicted occupancy上拿到距离之后直接和raw LiDAR measurements去比,这样就不需要GT occupancy了。这样依然可以从过去和未来的时刻去打光线,但必须得模拟LiDAR,不能自定义光线分布(我觉得问题不大)。于是,不管这个模型是用什么数据集训的,只要它是基于nuScenes的,全都可以统一评测,公平对比。此外,这个指标还可以评测GT occupancy制作的好坏,比如我想评估Occ3D和OpenOcc这两个数据集谁更好更准,我也可以用这个指标直接去和LiDAR比。这样Occupancy这个领域在评估指标这方面就可以迎来大一统,避免大家在各自的数据集上各玩各的。
以上就是我对我们本次工作的介绍,和我对未来的一些思考。这个工作和OpenDriveLab合作完成,感谢李弘扬老师和其他的小伙伴们!
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer111,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer111,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看














 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









