







 本文围绕AI芯片展开,介绍了NN计算的硬件设计瓶颈,包括数学运算速度和IO问题。还分析了深鉴科技的AI芯片SDK,提及Google的TPU系列及搭载其的Coral Dev Board,介绍了脉动阵列和HBM内存芯片,最后提供了大量AI芯片行业信息及参考资料。
本文围绕AI芯片展开,介绍了NN计算的硬件设计瓶颈,包括数学运算速度和IO问题。还分析了深鉴科技的AI芯片SDK,提及Google的TPU系列及搭载其的Coral Dev Board,介绍了脉动阵列和HBM内存芯片,最后提供了大量AI芯片行业信息及参考资料。
AI Chip

https://basicmi.github.io/AI-Chip/
A list of ICs and IPs for AI, Machine Learning and Deep Learning.
NN计算的硬件设计
NN计算问题的瓶颈主要包括两类:
1.数学运算的速度。NN运算主要以乘加为主,实现这类加速功能的硬件单元一般被称为NN Processor。这也是第一代AI芯片主要解决的问题。
再细分的话,又有矩阵派和卷积派两种。
矩阵派的通用性好,且FC运算速度快于卷积派。
而卷积派由于针对Conv的Kernel数据不变这一特点进行优化,Conv速度极快。
2.IO问题,也称带宽问题。早期的NN由于算子有限,基本只有FC、Conv、Pooling、Activation等少数几种算子。但现在的NN模型算子可就多了,且有相当部分算子属于非计算类的搬运数据算子,比如permute等。针对这类运算,一般采用被称作Tensor Processor的硬件单元进行加速。
DEEPHi
2018.8
深鉴科技是一家AI Chip公司。
官网:
它最近出了一套深度学习SDK:
http://www.deephi.com/zh-cn/dnndk.html
如果说2017年以前的AI Chip领域,主要解决的是芯片有无的问题的话,那么2018年的重点就聚焦在如何更好的使用上了。
性能方面各家各有千秋,即使不考虑功耗、面积等约束,也没有哪家在所有运算上,都比别人快,因此产品只要不是全面落伍,就还有的混。但易用性方面差距就比较大了。
1.CPU+NN混合编程。深鉴这方面做的还不错,似乎一套工具链就可以搞定,就是不知道自动化程度如何。有的友商连这一步都没做好,两套工具链+手动链接,把应用工程师折腾惨了。
2.模型压缩。Pruning方面由于有韩神的加持,确然做的很好,比我司强。Quantization方面,INT8量化算是最基本的量化了,不知道UINT8/INT16,他们做的如何。
3.Tensor Processor。深鉴这方面似乎是空白,这导致的一个结果就是AI Chip支持的运算非常有限,CPU负载过高,而AI Chip的负载相对就不行了。
4.模型导入。这方面深鉴只能说还不入流。虽然表面看来,它支持了Caffe和Tensorflow。然而它的支持方案是修改源代码。。。众所周知,pb文件的易用性是建立在通信双方使用同一套协议的基础之上。但目前AI领域魔改成风,跑个开源模型,还必须要下载作者魔改版的Caffe。。。可以想见深鉴这方面的自动化程度一定不咋样,肯定有很多手工活要做。
那么正确的做法是什么呢?参见ONNX。我司的方案比ONNX略早,但思路基本一致。
5.Model Zoo。这个比较寒碜了,只有三个模型,而且还都是最简单的分类模型。不过从支持Inception v1来看,应该是掌握了加速分支网络的技巧。其他的Face Detection等只有视频,没有模型,似乎还处于实验室阶段,可能易用性还有待提升。
无耻的谈一下我司的Model Zoo。包含40+的模型,涵盖图像分类、目标检测、图像分割、人脸识别、超分辨率、OCR等。目前,主要往RNN、Attention方面发展。这里会遇到循环结构的问题,还没有做的太好。
目前的AI Chip战争,入局的玩家基本都解决了芯片有无的问题。体系结构的红利也吃的差不多了,在未来几年不大可能再保持目前的算力增速。因此,未来争夺的焦点将转向软件方面。实际上,今年以来,已经有客户拿友商产品性能来压我们。然而也就是压一下而已,让他弃用他肯定不干。原因无他,我司80%的功能都已经自动化,没人会和好用过不去。
TPU
Tensor Processing Unit(TPU)是Google推出的AI芯片系列。目前已经有3个版本:
TPU v1, deployed 2015, 92 teraops, inference only.
TPU v2, cloud TPU 2017, pod 2018, 180 teraflops, 64 GB HBM, training and inference, generally available. 11.5 petaflops in a pod.
TPU v3, cloud beta 2018, 420 teraflops, 128 GB HBM, training and inference, beta. >100 petaflops in a pod.
论文:
《In-Datacenter Performance Analysis of a Tensor Processing Unit》
Coral Dev Board
Coral Dev Board是Google于2019年3月推出的一款搭载TPU的嵌入式开发板。
参考:
http://linuxgizmos.com/google-launches-i-mx8m-dev-board-with-edge-tpu-ai-chip/
Google launches i.MX8M dev board with Edge TPU AI chip
脉动阵列
Systolic array是孔祥重和他的博士生Charles Leiserson于1978年发明的。
论文:
《Why systolic architectures?》
孔祥重(H. T. Kung/Kung, Hsiang-Tsung),1945年生。台湾国立清华大学本科(1968)+CMU博士(1974)。CMU、Harvard教授。台湾中央研究院院士、美国工程院院士。除了Systolic array之外,数据库领域的Optimistic concurrency control(乐观并发控制)也是他的贡献。
除了Charles Eric Leiserson之外,他的博士生还有Robert Tappan Morris,也就是著名的Morris Worm的作者。
参考:
http://web.cecs.pdx.edu/~mperkows/temp/May22/0020.Matrix-multiplication-systolic.pdf
矩阵乘法器原理
http://www.eecs.harvard.edu/~htk/publication/1980-introduction-to-vlsi-systems-kung-leiserson.pdf
Algorithms for VLSI Processor Arrays
https://zhuanlan.zhihu.com/p/26522315
脉动阵列-因Google TPU获得新生
http://www.sohu.com/a/142237570_505803
我们应该拥抱“脉动阵列”吗?
https://zhuanlan.zhihu.com/p/26882794
Google深度揭秘TPU
参考
https://mp.weixin.qq.com/s/1X9xiZkmVPI-j-aipr-ocg
AlphaGo Master最新架构和算法,谷歌云与TPU拆解
https://mp.weixin.qq.com/s/Yo0uKd1Mzy4mmS4r0mxfVw
有图有真相:深度拆解谷歌TPU3.0,新一代AI协同处理器
https://mp.weixin.qq.com/s/kPrZ0PuevXEJjVB7RXs70g
谷歌TPU率队,颠覆3350亿美元的半导体行业
https://mp.weixin.qq.com/s/wunqEHC6c-yUVXTl4yTG4w
仅需1/5成本:TPU是如何超越GPU,成为深度学习首选处理器的
https://mp.weixin.qq.com/s/vncPcczTyqglndeZAgjWfw
一文读懂:谷歌千元级Edge TPU为何如此之快?
https://www.nextplatform.com/2018/05/10/tearing-apart-googles-tpu-3-0-ai-coprocessor/
Tearing Apart Google’s TPU 3.0 AI Coprocessor
HBM
HBM==High Bandwidth Memory是一款新型的CPU/GPU内存芯片(即 “RAM”),其实就是将很多个DDR芯片堆叠在一起后和GPU封装在一起,实现大容量,高位宽的DDR组合阵列。
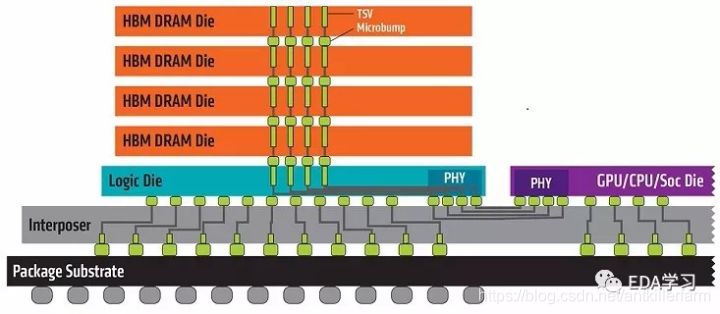
这是HBM的结构图。
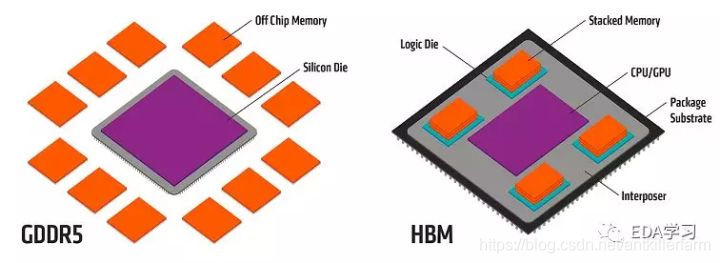
这是HBM和GDDR5的对比图。
从上面两图可以看出,HBM的集成程度在die一级,介于PCB和chip之间。
HBM带宽是传统内存(DRAM)的4.5倍,因此更适合处理AI应用程序所需的大量数据。这种性能的提升是如此之大,以至于许多客户更愿意支付专用内存所需的更高价格(每GB大约25美元,标准内存大约8美元)。
参考:
https://zhuanlan.zhihu.com/p/33990592
HBM火了,它到底是什么?
https://zhuanlan.zhihu.com/p/34164501
HBM技术之显卡应用
行业信息
https://mp.weixin.qq.com/s/vGoWsyaal-gAzsrhPguvFg
深度解读:华为麒麟芯片是如何炼成的!
http://tieba.baidu.com/p/2250616047
史上最全桌面显卡天梯图
https://mp.weixin.qq.com/s/jGGGMDokN9akzbjRkvUOaA
NVIDIA GPU架构的变迁史
https://mp.weixin.qq.com/s/8RDHTn6P63otKXUdrHhbjw
一文看懂AI芯片产业生态及竞争格局
https://mp.weixin.qq.com/s/jINnom16KWiEKiug3N-f8g
一文看懂AI芯片:三大门派四大场景146亿美元大蛋糕
https://mp.weixin.qq.com/s/-FwuhibwwG6CFUcZXNBTFA
投资者梳理AI芯片产业,一文秒懂AI芯片生态!
https://zhuanlan.zhihu.com/p/28325678
零基础看懂全球AI芯片:详解“xPU”
https://mp.weixin.qq.com/s/Zng0NTR9P78lnR_vniiM8g
Chris Rowen: 分析全球334家真正的深度学习创业公司,盘点25家AI芯片创业公司
https://zhuanlan.zhihu.com/p/33462550
传统IP Vendor的AI加速器一览
https://mp.weixin.qq.com/s/IaCWZXQI8mYLJQXwDoNQcQ
自动驾驶芯片:GPU的现在和ASIC的未来
https://mp.weixin.qq.com/s/KjQ5BTGd92Y0Mqzk1A5JYg
老兵戴辉讲述海思视频监控芯片从0到1的血泪史!如何一步步成为行业霸主的
参考
https://zhuanlan.zhihu.com/p/58971347
深度学习的芯片加速器
https://cloud.tencent.com/community/article/244743
深度学习的异构加速技术(一):AI需要一个多大的“心脏”?
https://cloud.tencent.com/community/article/581797
深度学习的异构加速技术(二):螺狮壳里做道场
https://cloud.tencent.com/community/article/446425
深度学习的异构加速技术(三):互联网巨头们“心水”这些AI计算平台
https://zhuanlan.zhihu.com/p/25382177
AI芯片怎么降功耗?
https://mp.weixin.qq.com/s/8HIZRhb-KJOtPnQtQ3GQVg
第一代芯片是CPU,第二代是GPU,第三代是什么?
https://mp.weixin.qq.com/s/qkpbKN62YV2f0W5HLnr7Dg
GPU是如何工作的?与CPU、DSP有什么区别?
https://mp.weixin.qq.com/s/Jof-u8oUuLR4v7t3jjXEmA
GPU和线下训练
https://mp.weixin.qq.com/s/2aE5fzGZeyX-oFyWbcbA5A
揭开神经网络加速器的神秘面纱之DianNao
https://mp.weixin.qq.com/s/VAFb0DAZAUyDnjE6SlNcXw
如何对比评价各种深度神经网络硬件?不妨给它们跑个分
https://mp.weixin.qq.com/s/zTO4UZ3zDLZL0GOjv0YqrQ
GPU加速深度学习
https://mp.weixin.qq.com/s/7vxJTh4IHeqUsc7IsLFLSA
解密哈萨比斯投资的IPU,他们要分英伟达一杯羹
https://zhuanlan.zhihu.com/p/26594188
浅析Yann LeCun提到的两款Dataflow Chip
https://zhuanlan.zhihu.com/p/25728988
AI芯片的几种选择,你更看好哪个?
https://zhuanlan.zhihu.com/p/25510056
ISSCC 2017看AI芯片的四大趋势
https://zhuanlan.zhihu.com/p/26404565
AI芯片四大流派论剑,中国能否弯道超车?
https://zhuanlan.zhihu.com/p/27472524
从AI芯片说起,一起来看芯片门类
https://mp.weixin.qq.com/s/Cy_vb0PpcvGTDmlMt1VkSw
从GPU、TPU到FPGA及其它:一文读懂神经网络硬件平台战局
https://mp.weixin.qq.com/s/RKRDBiBzG5u2P2eaqNAFbg
机器学习的处理器列表
https://mp.weixin.qq.com/s/bL1PoUjZ_sH2VKcBxI6N5A
Wave公司发布数据流处理架构DPU
https://mp.weixin.qq.com/s/1r7G84les7FihqPbSiS0Ng
华为首款手机端AI芯片麒麟970
https://mp.weixin.qq.com/s/y9dVg9YtfWxu6NcW-fxi6Q
内存带宽与计算能力,谁才是决定深度学习执行性能的关键?
https://mp.weixin.qq.com/s/K_dohaZbCISZlxe1Utu50w
如何用FPGA加速卷积神经网络(CNN)?
https://mp.weixin.qq.com/s/z68hk1yqg60QCjgTyzgG2w
GPU深度学习的“加速神器”

















 3467
3467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









