







3.4 汽车油耗预测实战(使用神经网络实现分类)
请看下面的实例文件wang02.py,功能是采用 Auto MPG 数据集,然后使用TensorFlow创建一个神经网络模型预测汽车的油耗。
3.4.1 准备数据
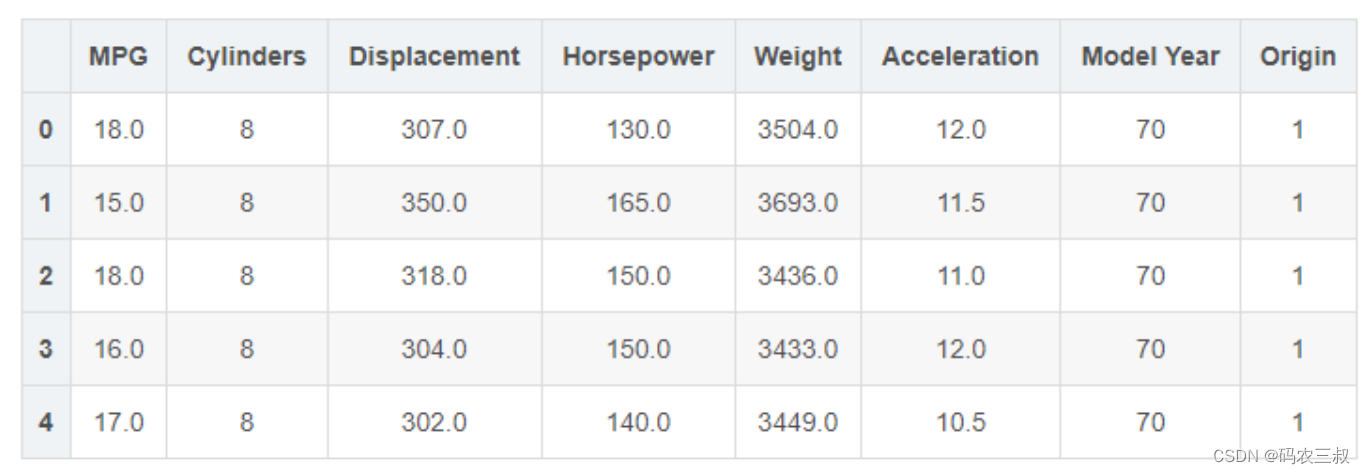
本实例采用 Auto MPG 数据集,在里面记录了各种汽车效能指标与气缸数、重量、马力等其
他因子的真实数据。数据集中的前5项数据如下表3-1所示。
表3-1 数据集中的前5项数据
(1)首先导入我们要使用的库,代码如下:
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, losses(2)编写函数load_dataset()下载数据集,代码如下:
def load_dataset():
# 在线下载汽车效能数据集
dataset_path = keras.utils.get_file("auto-mpg.data","http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
# 效能(公里数每加仑),气缸数,排量,马力,重量
# 加速度,型号年份,产地
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names,
na_values="?", comment='\t',
sep=" ", skipinitialspace=True)
dataset = raw_dataset.copy()
return dataset(3)通过如下代码查看数据集中的前5条数据:
dataset = load_dataset()
# 查看部分数据
print(dataset.head())执行后会输出:
MPG Cylinders Displacement ... Acceleration Model Year Origin
0 18.0 8 307.0 ... 12.0 70 1
1 15.0 8 350.0 ... 11.5 70 1
2 18.0 8 318.0 ... 11.0 70 1
3 16.0 8 304.0 ... 12.0 70 1
4 17.0 8 302.0 ... 10.5 70 1(4)读者需要注意,原始数据中的数据可能含有空字段(缺失值)的数据项,需要通过如下代码清除这些记录项:
def preprocess_dataset(dataset):
dataset = dataset.copy()
# 统计空白数据,并清除
dataset = dataset.dropna()
# 处理类别型数据,其中origin列代表了类别1,2,3,分布代表产地:美国、欧洲、日本
# 其弹出这一列
origin = dataset.pop('Origin')
# 根据origin列来写入新列
dataset['USA'] = (origin == 1) * 1.0
dataset['Europe'] = (origin == 2) * 1.0
dataset['Japan'] = (origin == 3) * 1.0
# 切分为训练集和测试集
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
return train_dataset, test_dataset(5)可视化统计数据集中的数据,代码如下:
train_dataset, test_dataset = preprocess_dataset(dataset)
# 统计数据
sns_plot = sns.pairplot(train_dataset[["Cylinders", "Displacement", "Weight", "MPG"]], diag_kind="kde")
plt.figure()
plt.show()执行后的效果如图3-5所示。
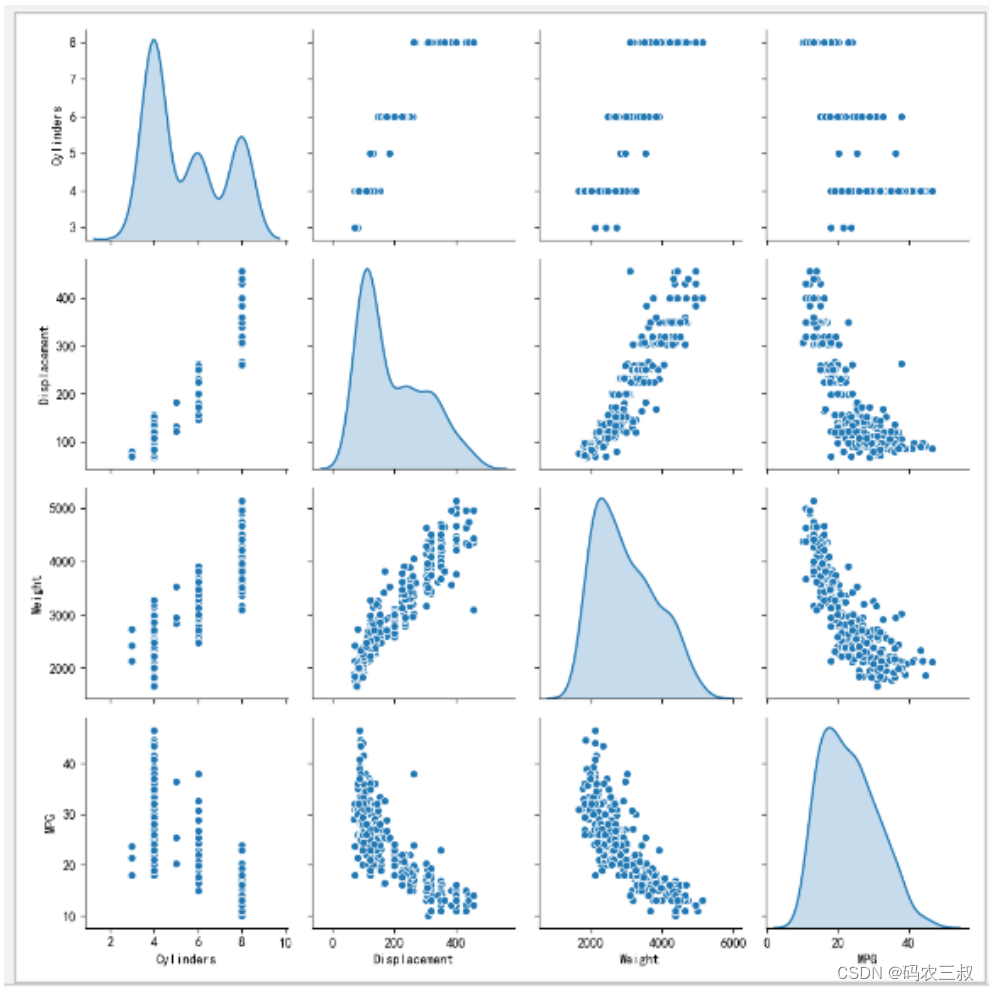
图3-5 数据集可视化
(6)将 MPG 字段移出为标签数据,代码如下:
# 查看训练集的输入X的统计数据
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats此时执行后会输出如图3-6所示的效果。
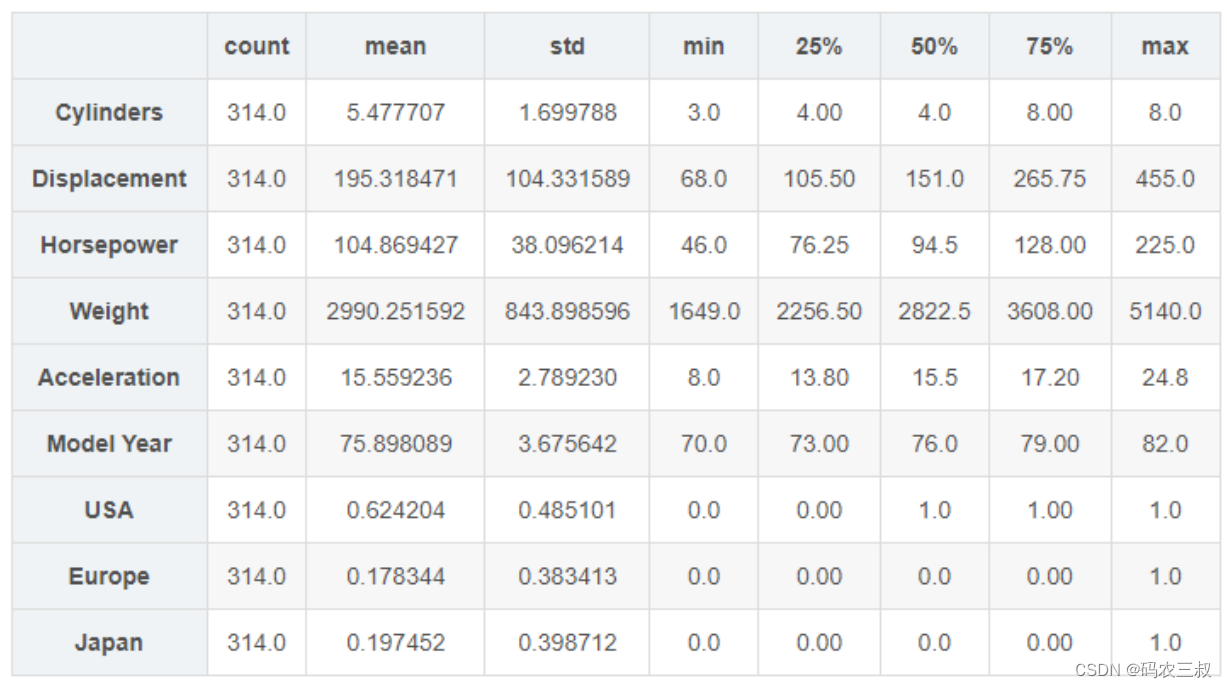
图3-6 处理后的数据
3.4.2 创建网络模型
实现数据的标准化处理,通过回归网络创建3个全连接层,然后通过函数build_model()创建网络模型。代码如下:
def norm(x, train_stats):
"""
标准化数据
:param x:
:param train_stats: get_train_stats(train_dataset)
:return:
"""
return (x - train_stats['mean']) / train_stats['std']
# 移动MPG油耗效能这一列为真实标签Y
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
# 进行标准化
normed_train_data = norm(train_dataset, train_stats)
normed_test_data = norm(test_dataset, train_stats)
print(normed_train_data.shape,train_labels.shape)
print(normed_test_data.shape, test_labels.shape)
class Network(keras.Model):
# 回归网络
def __init__(self):
super(Network, self).__init__()
# 创建3个全连接层
self.fc1 = layers.Dense(64, activation='relu')
self.fc2 = layers.Dense(64, activation='relu')
self.fc3 = layers.Dense(1)
def call(self, inputs):
# 依次通过3个全连接层
x1 = self.fc1(inputs)
x2 = self.fc2(x1)
out = self.fc3(x2)
return out
def build_model():
# 创建网络
model = Network()
# 通过 build 函数完成内部张量的创建,其中 4 为任意的 batch 数量,9 为输入特征长度
model.build(input_shape=(4, 9))
model.summary() # 打印网络信息
return model
model = build_model()
optimizer = tf.keras.optimizers.RMSprop(0.001) # 创建优化器,指定学习率
train_db = tf.data.Dataset.from_tensor_slices((normed_train_data.values, train_labels.values))
train_db = train_db.shuffle(100).batch(32)执行后会输出:
(314, 9) (314,)
(78, 9) (78,)
Model: "network_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) multiple 640
_________________________________________________________________
dense_4 (Dense) multiple 4160
_________________________________________________________________
dense_5 (Dense) multiple 65
=================================================================
Total params: 4,865
Trainable params: 4,865
Non-trainable params: 0
_________________________________________________________________3.4.3 训练、测试模型
接下来开始训练并测试模型,具体实现流程如下:
(1)通过 Epoch 和 Step 的双层循环训练网络,共训练 200 个 epoch,代码如下:
def train(model, train_db, optimizer, normed_test_data, test_labels):
train_mae_losses = []
test_mae_losses = []
for epoch in range(200):
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
out = model(x)
# 均方误差
loss = tf.reduce_mean(losses.MSE(y, out))
#平均绝对值误差
mae_loss = tf.reduce_mean(losses.MAE(y, out))
if step % 10 == 0:
print(epoch, step, float(loss))
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_mae_losses.append(float(mae_loss))
out = model(tf.constant(normed_test_data.values))
test_mae_losses.append(tf.reduce_mean(losses.MAE(test_labels, out)))
return train_mae_losses, test_mae_losses
def plot(train_mae_losses, test_mae_losses):
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('MAE')
plt.plot(train_mae_losses, label='Train')
plt.plot(test_mae_losses, label='Test')
plt.legend()
# plt.ylim([0,10])
plt.legend()
plt.show()(2)绘制损失和预测曲线图,代码如下:
train_mae_losses, test_mae_losses = train(model, train_db, optimizer, normed_test_data, test_labels)
plot(train_mae_losses, test_mae_losses)执行后的效果如图3-7所示。
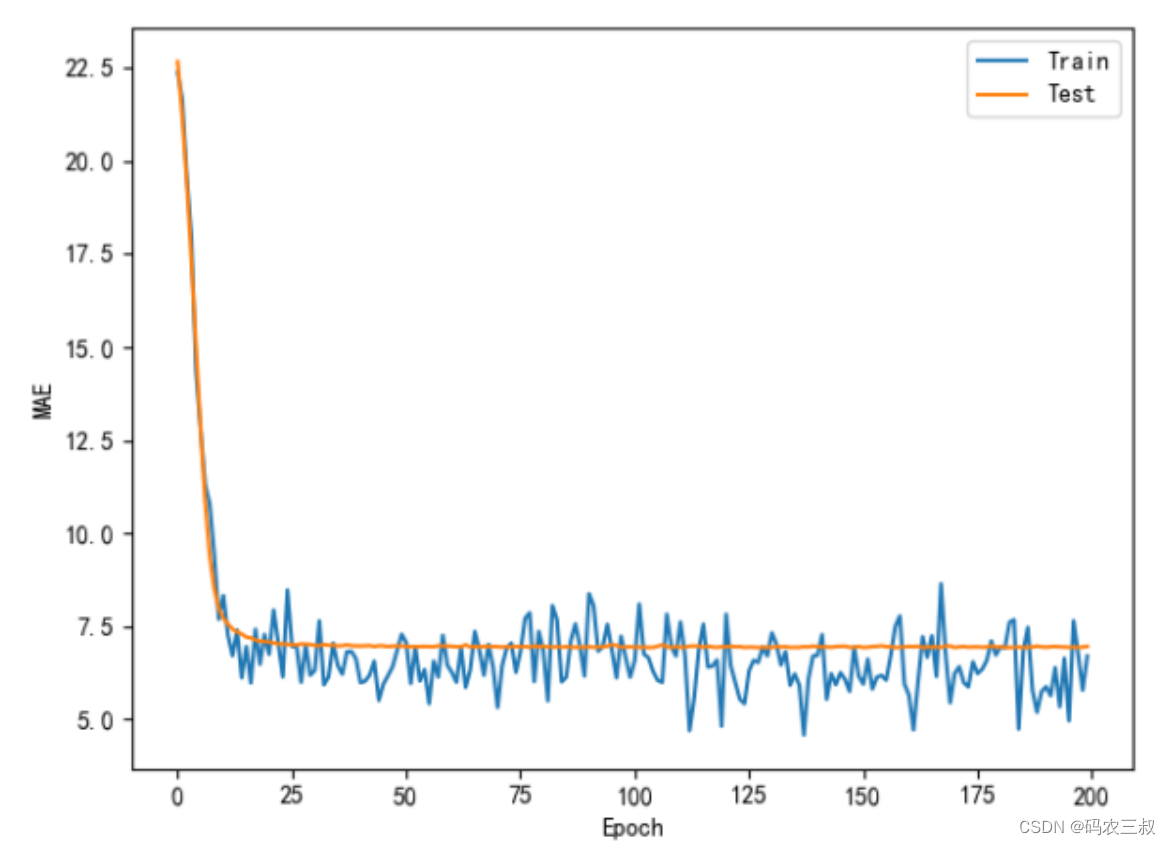
图3-7 执行效果

















 2750
2750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











