






PPO(Proximal Policy Optimization)和DPO(Direct Preference Optimization)是两种不同的优化算法,分别应用于强化学习和基于人类反馈的模型微调。以下是它们的核心含义和原理:
1. PPO(Proximal Policy Optimization)
含义
PPO 是一种强化学习算法,属于策略梯度(Policy Gradient)方法的改进版本,由OpenAI于2017年提出。其核心目标是在保证训练稳定性的同时高效优化策略,避免策略更新幅度过大导致的性能崩溃。
原理
-
策略梯度基础
策略梯度方法直接优化策略(即状态到动作的映射函数),通过最大化期望回报的梯度更新策略参数。公式为:
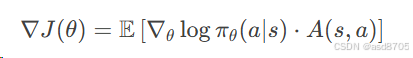
其中,(A(s,a)) 是优势函数(衡量当前动作优于平均水平的程度)。
-
重要性采样与截断
PPO 的核心改进在于引入重要性采样和截断机制,限制新旧策略之间的差异,防止更新步幅过大:

-
优势函数估计
通常使用广义优势估计(GAE)计算 (A(s,a)),平衡偏差与方差。
优点
- 稳定性高,适合复杂环境(如机器人控制、游戏AI);
- 实现简单,调参相对容易。
2. DPO(Direct Preference Optimization)
含义
DPO 是一种直接基于人类偏好数据优化模型的方法,用于替代传统的RLHF(基于人类反馈的强化学习)流程。由斯坦福团队在2023年提出,旨在简化大语言模型(如ChatGPT)的微调过程。
原理
-
传统RLHF的痛点
传统RLHF分为三步:- 预训练模型 → 收集人类偏好数据训练奖励模型(RM)→ 使用PPO微调模型以最大化奖励。
此过程需要训练奖励模型,且PPO的计算成本高。
- 预训练模型 → 收集人类偏好数据训练奖励模型(RM)→ 使用PPO微调模型以最大化奖励。
-
DPO的核心思想
DPO 直接利用偏好数据(如标注了“好答案”和“坏答案”的样本对)优化模型,绕过显式的奖励建模和强化学习步骤。其核心公式为:

-
理论依据
DPO 将奖励函数隐式地编码到策略优化中,通过理论推导证明其等价于最大化基于奖励模型的策略目标,但无需显式训练奖励模型。
优点
- 无需训练奖励模型,节省计算资源;
- 训练更稳定,避免PPO的复杂性;
- 对偏好数据的利用更高效。
PPO vs. DPO 对比
| 特性 | PPO | DPO |
|---|---|---|
| 应用场景 | 通用强化学习(如游戏、机器人) | 基于人类偏好的模型微调(如对话模型) |
| 数据需求 | 环境交互数据 | 标注的偏好数据对 |
| 计算复杂度 | 高(需策略迭代+奖励模型) | 低(直接优化策略) |
| 稳定性 | 依赖超参数调优 | 更稳定(避免奖励模型误差) |
总结
- PPO 是强化学习的经典算法,通过截断机制平衡探索与利用,适合需要环境交互的任务;
- DPO 是RLHF的简化方案,直接利用偏好数据优化模型,适合大语言模型的高效微调。
两者分别针对不同场景,DPO的提出反映了学术界对简化复杂训练流程的持续探索。
在设计PPO(Proximal Policy Optimization)的奖励模型时,核心目标是为智能体的行为提供有效、稳定且可学习的反馈信号。奖励模型(Reward Model)的设计直接影响策略优化的效果,尤其是在复杂任务或需要人类偏好的场景中(如对话生成、机器人控制)。以下是设计奖励模型的关键步骤和原理:
1. 奖励模型的作用
- PPO的依赖:PPO是策略优化算法,本身不生成奖励,而是依赖外部提供的奖励信号更新策略。
- 奖励模型的功能:将智能体的行为(或环境状态)映射为标量奖励值,用于量化行为的好坏。
2. 奖励模型的设计方法
(1) 任务目标明确时的显式设计
如果任务目标可直接量化(如游戏得分、机器人移动距离),可直接设计人工规则化的奖励函数:
- 示例:
- 迷宫导航:到达终点奖励+100,每走一步惩罚-1。
- 机械臂抓取:成功抓取物体奖励+50,碰撞惩罚-10。
- 注意事项:
- 稀疏奖励问题:若奖励过于稀疏(如仅在任务完成时给予奖励),需通过**奖励塑造(Reward Shaping)**添加中间奖励(如逐步接近目标的奖励)。
- 奖励冲突:避免多个子目标的奖励设计相互矛盾。
(2) 复杂任务的隐式学习(基于人类反馈)
当任务目标难以显式定义时(如对话质量、艺术创作),需通过人类偏好数据训练奖励模型(Reward Model, RM):
-
数据收集:
- 收集人类对智能体行为的偏好标注(如标注两个答案中哪个更好)。
- 示例:在对话任务中,标注
(prompt, response_A, response_B, 偏好)四元组。
-
模型训练:
- 使用对比学习训练奖励模型,使其能预测人类偏好。
- 损失函数(如Bradley-Terry模型):

-
模型集成:
- 将训练好的奖励模型作为PPO的奖励来源,用于生成训练信号。
(3) 逆强化学习(Inverse RL)
当无法直接设计奖励函数且缺乏人类标注时,通过逆强化学习从专家示范中推断奖励模型:
- 输入:专家演示的轨迹(如人类驾驶数据)。
- 输出:奖励函数,使得专家行为在奖励下最优。
- 常用算法:最大熵逆强化学习(MaxEnt IRL)、GAIL(生成对抗模仿学习)。
3. 奖励模型的实现细节
(1) 模型架构
- 根据任务复杂度选择模型:
- 简单任务:线性模型、小规模神经网络。
- 复杂任务:预训练语言模型(如BERT、GPT)的微调,用于文本/图像类奖励预测。
- 输入设计:
- 状态(s) + 动作(a) → 奖励(r)(适用于机器人控制)。
- 文本对
(prompt, response)→ 质量评分(适用于对话生成)。
(2) 训练稳定性
- 正则化:防止奖励模型过拟合(如L2正则化、Dropout)。
- 数据增强:对偏好数据添加噪声或扰动,提升泛化能力。
- 多模型集成:使用多个奖励模型投票,减少偏差。
(3) 与PPO的协同
- 奖励归一化:将奖励缩放至合理范围(如[-1, 1]),避免策略更新步幅过大。
- 奖励延迟处理:对长期任务,需设计折扣因子(\gamma),平衡即时与未来奖励。
- 对抗过优化:若智能体学会“欺骗”奖励模型(如生成高奖励但无意义的行为),需动态更新奖励模型或引入人工审核。
4. 实际案例
(1) OpenAI的ChatGPT(RLHF流程)
- 奖励模型训练:
- 收集人类标注的对话偏好数据。
- 训练一个基于GPT的奖励模型,预测人类更喜欢哪个回答。
- PPO微调:
- 使用奖励模型为生成的回答打分,驱动策略优化。
(2) AlphaGo的奖励设计
- 显式奖励:围棋胜利+1,失败-1。
- 中间奖励:通过蒙特卡洛树搜索(MCTS)模拟未来胜率,隐式提供中间奖励信号。
5. 常见问题与解决方案
| 问题 | 解决方案 |
|---|---|
| 奖励稀疏导致学习缓慢 | 奖励塑造(添加中间奖励) |
| 奖励模型过拟合人类偏好数据 | 数据增强、正则化、多模型集成 |
| 智能体“欺骗”奖励模型 | 动态更新奖励模型、引入人工审核机制 |
| 奖励数值范围不稳定 | 奖励归一化、使用优势函数(Advantage) |
总结
PPO的奖励模型设计需要结合任务特点灵活选择方法:
- 显式设计:适合目标明确、可量化的任务(如游戏、机器人控制)。
- 隐式学习:适合依赖人类偏好或复杂语义的任务(如对话生成、内容创作)。
- 逆强化学习:适合从专家示范中推导奖励函数。
关键是通过奖励模型提供稳定、可解释且对齐任务目标的信号,确保PPO能高效优化策略。实际应用中,常需多次迭代调整奖励模型和策略训练的协同。

















 1518
1518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









