







Ollama
简单易用的LLM部署工具
Ollama是一个开源的本地运行和管理大语言模型(LLM)的工具,旨在帮助用户快速在本地设备上部署和管理大模型,如Llama 2和DeepSeek。通过Ollama,用户可以在不依赖云端的情况下实现智能对话、文本生成等功能,保护数据隐私并降低对硬件的要求。
Ollama提供了一个直观且易于使用的命令行界面(CLI),使得即使是非技术人员也能轻松安装和使用。此外,它还支持通过HTTP接口和Web UI进行访问,进一步增强了用户体验。
- 特点
- 具备简单直观的命令行界面,操作便捷,可快速启动模型。
- 内置了大量预训练模型,涵盖多种不同类型,方便用户选择使用。
- 支持对模型进行微调,用户能够根据自身需求定制模型。
- 支持macOS、Windows和Linux系统,具有良好的跨平台兼容性。
- 优势
- 部署过程极为简单,即使是没有深厚技术背景的用户也能轻松上手。
- 模型管理功能强大,能方便地进行模型的下载、更新和删除操作。
- 社区活跃度较高,用户可以在社区中获取帮助和分享经验。
- 适用场景
- 适合初学者快速体验大模型,无需复杂配置即可使用。
- 用于快速验证模型在特定任务上的表现,节省时间。
- 适用于个人开发者进行小型项目开发。
- 吸引点
- 简洁的操作流程降低了使用门槛,让更多人能够参与到大模型应用中。
- 丰富的模型库提供了多样化的选择,满足不同需求。
- 不足之处
- 对于复杂的定制需求,其功能可能相对有限。
- 性能优化方面可能不如一些专门针对性能优化的工具。
安装示例
curl -fsSL https://ollama.com/install.sh | sh运行示例
ollama run deepseek-r1vLLM
高性能LLM推理引擎
vLLM(虚拟大型语言模型)是一种由vLLM社区维护的开源代码库,旨在帮助大型语言模型(LLM)更高效地大规模执行计算。vLLM通过优化推理服务器和内存管理技术,显著提升了生成式AI应用的输出速度和性能。
- 特点
- 采用了先进的推理加速技术,能够显著提高模型的推理速度。
- 支持分布式推理,可充分利用多核CPU和GPU资源。
- 提供了 Python API,方便与其他 Python 项目集成。
- 优势
- 高性能的推理能力使得在处理大规模数据或高并发请求时表现出色。
- 分布式推理功能可扩展性强,能根据需求灵活调整计算资源。
- 与 Python 生态的良好集成,便于开发者进行二次开发。
- 适用场景
- 适用于需要快速响应的实时应用,如聊天机器人、智能客服等。
- 处理大规模数据集的推理任务,如大规模文本生成。
- 适合企业级应用,对性能和可扩展性有较高要求的场景。
- 吸引点
- 快速的推理速度能提升用户体验,满足实时交互需求。
- 分布式推理和良好的扩展性为大规模应用提供了保障。
- 不足之处
- 部署和配置相对复杂,需要一定的技术基础。
- 对于小型项目或对性能要求不高的场景,可能会显得过于复杂。

安装示例
pip install vllm运行示例
vllm serve --host 0.0.0.0 --port 8080 --model-path /modelpathllama.cpp
CPU 上的轻量级王者
llama.cpp是一个基于C/C++的开源项目,旨在高效地运行大型语言模型(LLM)推理,特别是在本地设备上。它由Georgi Gerganov开发,专注于轻量级、高性能的模型推理,支持多种硬件平台,包括CPU和GPU。llama.cpp的主要目标是通过最小化设置和优化性能,在本地和云端设备上运行LLM推理,特别适合资源受限的环境。
- 特点
- 轻量级实现,对硬件资源的要求较低,可在普通设备上运行。
- 支持多种量化方法,能够在保证一定精度的前提下大幅减少内存使用。
- 提供了简单的命令行工具,方便进行模型推理。
- 优势
- 低资源消耗使得在资源有限的设备上也能运行大模型。
- 量化技术有效降低了内存需求,提高了模型的运行效率。
- 开源且代码简洁,便于开发者进行修改和扩展。
- 适用场景
- 适用于在资源受限的设备上进行模型推理,如嵌入式设备、移动设备等。
- 对内存使用有严格要求的场景,如在内存较小的服务器上部署。
- 适合开发者进行模型研究和学习,方便理解模型的推理过程。
- 吸引点
- 低资源消耗让更多设备能够运行大模型,扩大了应用范围。
- 开源代码为开发者提供了深入研究和定制的机会。
- 不足之处
- 功能相对单一,主要侧重于模型推理,缺乏一些高级的管理和优化功能。
- 对模型的支持范围可能相对较窄,主要集中在特定类型的模型。

安装示例
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
# 启动cuda加速 (服务器使用的是nvidia-A10的gpu,编译使用的cuda编译版本)
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release运行示例
cd llama.cpp/build/bin
./llama-cli -m /models/qwen2.5-7b-instruct-q4_k_m.gguf -co -cnv -p "你是AI助手" -fa -ngl 80 -n 512LM Studio
LM Studio是一款功能强大的桌面应用程序,旨在让用户能够在本地设备上轻松运行、管理和部署大型语言模型(LLMs),而无需依赖昂贵的云端服务。它降低了使用大语言模型的门槛,提供了离线运行、灵活使用模型和广泛模型兼容性等核心功能,特别适合开发者和爱好者使用。
- 特点
- 拥有直观的图形用户界面(GUI),操作方便,无需编写代码。
- 支持多种模型格式,能轻松集成不同来源的模型。
- 提供了可视化的模型配置和管理功能,方便用户进行参数调整。
- 优势
- GUI 界面降低了使用门槛,非技术人员也能轻松使用。
- 多模型格式支持增加了模型选择的灵活性,用户可以使用不同类型的模型。
- 可视化配置和管理功能让用户能够直观地调整模型参数,提高效率。
- 适用场景
- 适合普通用户进行模型体验和测试,无需具备编程知识。
- 用于快速比较不同模型在同一任务上的表现,方便选择合适的模型。
- 适用于非技术部门的人员使用,如市场调研、内容创作等部门。
- 吸引点
- 直观的 GUI 界面让操作变得简单易懂,提高了用户体验。
- 多模型支持和可视化管理功能为用户提供了便利。
- 不足之处
- 相比命令行工具,在自动化和脚本化方面可能存在一定局限性。
- 对于复杂的定制需求,GUI 界面可能无法提供足够的灵活性。
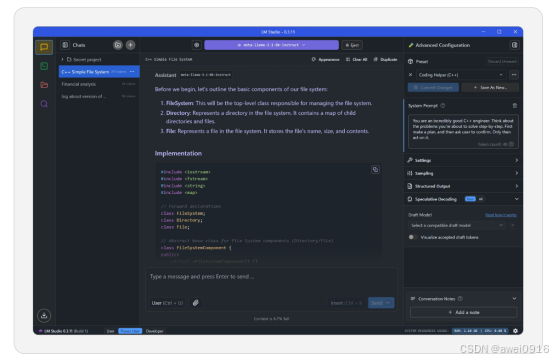
安装示例:
下载地址:Download LM Studio - Mac, Linux, Windows
对比总结
| 工具名称 | 特点 | 优势 | 适用场景 | 吸引点 | 不足之处 |
|---|---|---|---|---|---|
| Ollama | 有简单直观命令行界面,内置大量预训练模型,支持模型微调 | 部署简单,模型管理功能强,社区活跃 | 初学者体验、快速验证模型、个人开发者小型项目 | 操作门槛低,模型选择多 | 复杂定制功能有限,性能优化不足 |
| vLLM | 采用推理加速技术,支持分布式推理,有 Python API | 推理性能高,可扩展性强,与 Python 生态集成好 | 实时应用、大规模数据集推理、企业级应用 | 推理速度快,扩展性好保障大规模应用 | 部署配置复杂,小型项目使用可能过于复杂 |
| llama.cpp | 轻量级,支持多种量化方法,有简单命令行工具 | 资源消耗低,量化技术降内存,开源代码简洁 | 资源受限设备、对内存要求高的场景、模型研究学习 | 低资源让更多设备可用,开源便于定制 | 功能单一,模型支持范围窄 |
| LM Studio | 有直观图形用户界面,支持多种模型格式,有可视化配置管理功能 | 操作方便,多模型格式支持,可视化配置高效 | 普通用户体验测试、比较不同模型、非技术部门使用 | GUI 界面易懂,多模型支持和可视化管理便利 | 自动化和脚本化有局限,复杂定制灵活性不足 |
选择建议
-
初学者或个人开发者进行简单体验和小型项目:可优先选择 Ollama 或 LM Studio。Ollama 操作简单且模型管理方便,LM Studio 则有直观的图形界面,无需编程知识。
-
对推理性能和可扩展性有高要求的企业级应用或实时应用:vLLM 是较好的选择,其推理加速和分布式推理能力能满足大规模数据处理和高并发需求。
-
在资源受限设备上运行模型或进行模型研究学习:llama.cpp 更合适,它对硬件资源要求低,且开源代码便于理解和修改。


















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









