









目录
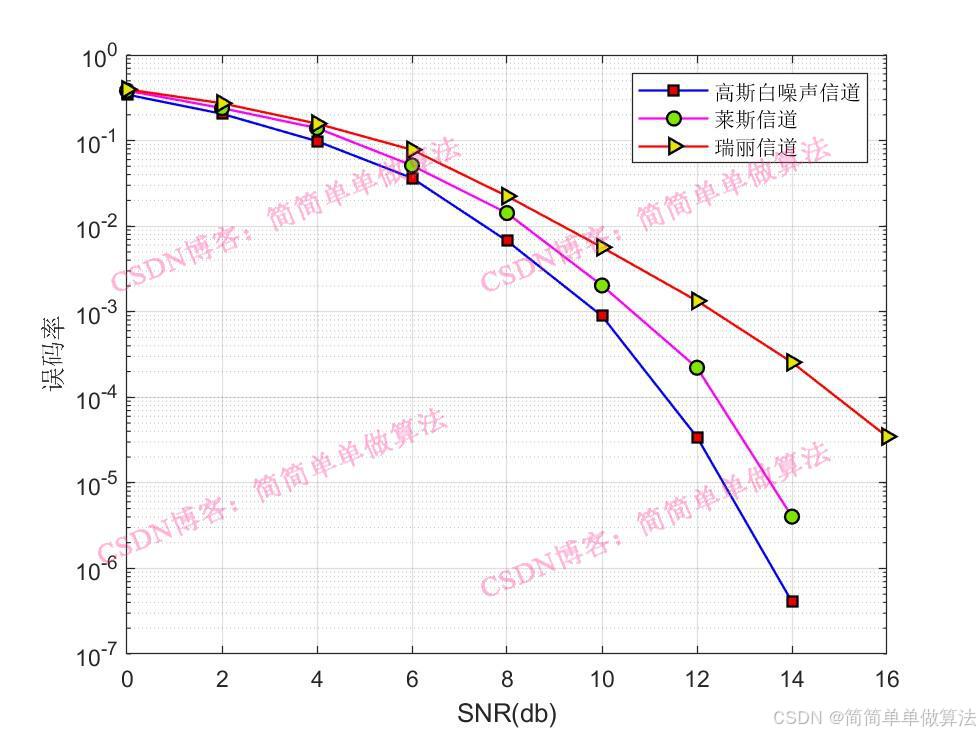
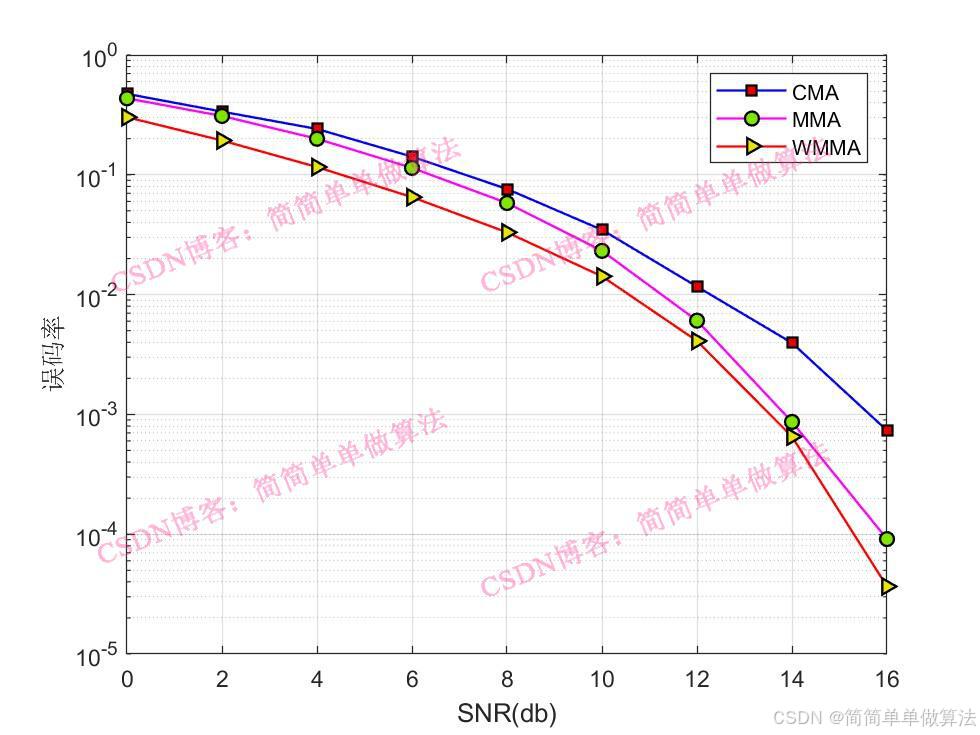
1.算法运行效果图预览
(完整程序运行后无水印)
2.算法运行软件版本
Matlab2024b
3.部分核心程序
(完整版代码包含详细中文注释和操作步骤视频)
function [y,ws] = func_WMMA(x,M,mu)
R = 1+sqrt(-1);
w = zeros(1,M);
w((M+1)/2) = 1;
wo = w;
N = length(x);
m = 1;
am = 0.001;
for n = M:1:N
coff = x(n:-1:n-M+1);
y(m) = w*coff;
er(m) = real(y(m))*(real(y(m))^2 - real(R)^2);
ei(m) = imag(y(m))*(imag(y(m))^2 - imag(R)^2);
if m>1
w = w + mu*[er(m)+ei(m)]*coff'*y(m) + am*(ws(:,m)-ws(:,m-1))^2;
else
w = w + mu*[er(m)+ei(m)]*coff'*y(m);
end
m = m + 1;
ws(:,m) = w;
end
end
01_249m4.算法理论概述
在无线通信系统中,信道估计与均衡是克服多径衰落、提高信号传输可靠性的关键技术。传统的信道估计方法需要发送训练序列,这会降低频谱效率。盲信道估计则仅利用接收信号的统计特性来估计信道,无需额外的训练开销,因此受到广泛关注。本文将详细介绍基于加权多模算法 (Weighted Multi-Modulus Algorithm, WMMA) 的盲信道估计与均衡系统,并与多模算法 (MMA) 和恒模算法 (CMA) 进行对比分析。
盲均衡
盲均衡的目标是设计一个自适应滤波器w(n),使得均衡器输出y(n)尽可能接近期望信号s(n):
 恒模算法 (CMA)
恒模算法 (CMA)
恒模算法是最早提出的盲均衡算法之一,特别适用于恒包络调制信号,如BPSK、QPSK等。CMA的基本思想是利用恒包络信号的特性,即信号的幅度是恒定的。

多模算法 (MMA)
CMA虽然在恒包络信号上表现良好,但对于非恒包络信号,如16-QAM、64-QAM等,性能较差。多模算法 (MMA) 是CMA的扩展,能够处理非恒包络信号。

加权多模算法 (WMMA)
WMMA是MMA的进一步改进,通过引入权重因子来提高算法的性能。WMMA的核心思想是根据均衡器输出与各个星座点的距离动态调整权重,使得算法能够更灵活地适应不同的信号分布。

三组算法的权值更新公式对比:
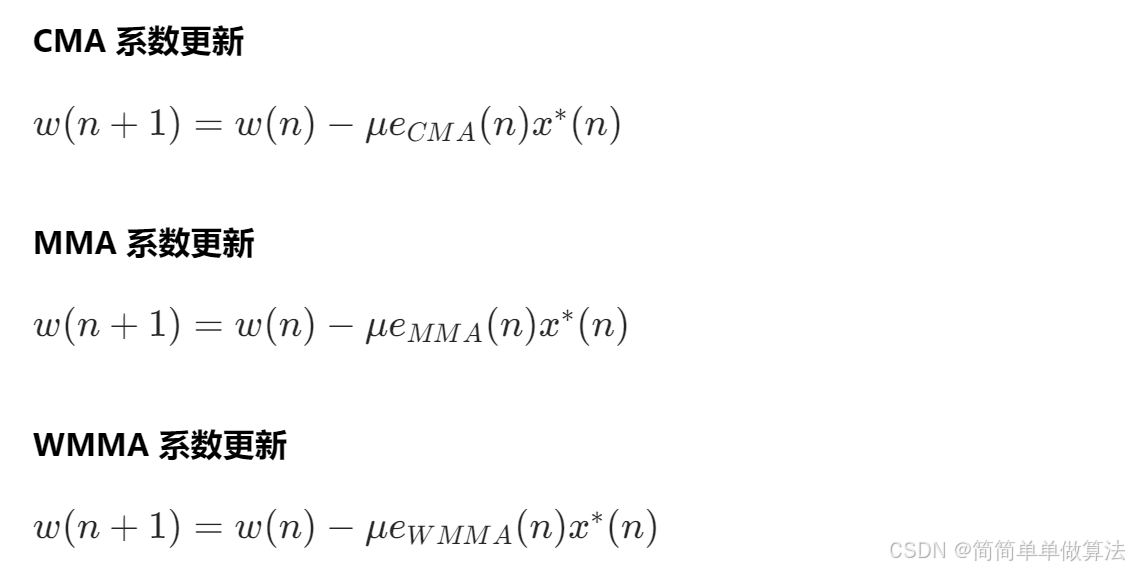
WMMA通过引入动态权重因子,能够更灵活地适应不同的信号分布,在收敛速度、稳态误差和误码率性能方面均优于CMA和MMA。尽管WMMA的计算复杂度较高,但随着硬件技术的发展,其在高性能通信系统中的应用前景广阔。未来的研究方向包括进一步优化WMMA算法、探索与其他技术的结合,以及拓展其在新兴通信领域的应用。
5.算法完整程序工程
OOOOO
OOO
O


















 1909
1909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











