







 本文深入探讨了主成分分析(PCA)及功能性主成分分析(fPCA)的基本原理和技术细节,包括多元PCA、平滑PCA等内容,并介绍了如何通过旋转等手段增强结果的可解释性。
本文深入探讨了主成分分析(PCA)及功能性主成分分析(fPCA)的基本原理和技术细节,包括多元PCA、平滑PCA等内容,并介绍了如何通过旋转等手段增强结果的可解释性。
阅读材料:Ramsay, J.O., Silverman, B.W. (2005) Functional Data Analysis (2nd Edition) Section 8.1-8.6, 9.1-9.4.
contents
1 Multivariate Principal Components Analysis
The basic idea of Principal Components Analysis is to transform a group of potentially correlated variables into a group of linearly uncorrelated variables through orthogonal transformation, and this group of variables after conversion are called principal components.

1.1 A little analysis
- Measure total variation in the data as total squared distance from center:
∑ j = 1 d ∑ i = 1 n ( x i j − x ˉ j ) 2 = t r a c e [ Σ ] ; \sum_{j=1}^d \sum_{i=1}^{n} (x_{ij} - \bar{x}_j)^2 = trace[\Sigma]; j=1∑di=1∑n(xij−xˉj)2=trace[Σ]; - If x x x has covariance Σ \Sigma Σ, the variance of u T x u^Tx uTx is u T Σ u u^T \Sigma u uTΣu;
- To maximize
u
T
Σ
u
u^T \Sigma u
uTΣu (or
u
T
u
u^Tu
uTu) we solve the eigen-equation
Σ u = λ u ; \Sigma u = \lambda u; Σu=λu; - For
u
T
u
=
1
u^Tu = 1
uTu=1, the closest multiple of
u
u
u to
x
−
x
ˉ
x-\bar{x}
x−xˉ is
( u T u ) − 1 ( u T x ) u = ( u T ( x − x ˉ ) ) u . (u^Tu)^{-1} (u^Tx)u = (u^T(x-\bar{x}))u. (uTu)−1(uTx)u=(uT(x−xˉ))u.
1.2 Mechanics of PCA
For an n × p n \times p n×p data matrix with n n n observations and p p p attributions:
- Estimate the covariance matrix (using sample covariance matrix)
Σ = 1 n − 1 ( X − X ˉ ) T ( X − X ˉ ) , \Sigma = \frac{1}{n-1} (X - \bar{X})^T(X - \bar{X}), Σ=n−11(X−Xˉ)T(X−Xˉ),
where X ˉ \bar{X} Xˉ is the mean vector of the p p p attributions of the data matrix X X X; - Take the eigen-decomposition of
Σ
\Sigma
Σ
Σ = U T D U = ∑ d i i u i u i T ; \Sigma = U^TDU = \sum d_{ii} u_i u_i^T; Σ=UTDU=∑diiuiuiT;- Columns of U U U are orthogonal; represent a new basis. Denoting the i i ith column of U U U by u i u_i ui;
- D D D is a diagonal matrix. Its entries ( d i i d_{ii} dii) (eigenvalues) give variances of data along corresponding directions U U U.
- Order D D D, U U U in terms of decreasing d i i d_{ii} dii;
- ( X − X ˉ ) T u i (X - \bar{X})^T u_i (X−Xˉ)Tui is the i i ith principal component score.
2 Functional PCA
2.1 Re-interpretation
Instead of covariance matrix Σ \Sigma Σ, we have a surface σ ( s , t ) \sigma (s, t) σ(s,t).
Re-interpret eigen-decomposition:
Σ = U T D U = ∑ d i i u i u i T . \Sigma = U^TDU = \sum d_{ii} u_i u_i^T. Σ=UTDU=∑diiuiuiT.
For functions, this is the Karhunen-Loève decomposition:
σ ( s , t ) = ∑ i = 1 ∞ d i i ξ i ( s ) ξ i ( t ) , \sigma (s, t) = \sum_{i=1}^{\infty} d_{ii} \xi_i (s) \xi_i (t), σ(s,t)=i=1∑∞diiξi(s)ξi(t),
where
- d i i d_{ii} dii represents amount of variation in direction ξ i ( t ) \xi_i (t) ξi(t);
- ∫ ξ i ( t ) 2 d t = I . \int \xi_i (t)^2 dt = I. ∫ξi(t)2dt=I. (??)
For the collection of curves x i ( t ) x_i (t) xi(t), i = 1 , . . . , n i = 1, ..., n i=1,...,n, we want to find the probe ξ 1 ( t ) \xi_1 (t) ξ1(t) that maximizes
V a r [ ∫ ξ 1 ( t ) x i ( t ) d t ] . Var \bigg[ \int \xi_1 (t) x_i (t) dt \bigg]. Var[∫ξ1(t)xi(t)dt].
But we need to constrain ∫ ξ 1 ( t ) 2 d t = 1 \int \xi_1 (t)^2 dt = 1 ∫ξ1(t)2dt=1.
For
ξ
2
(
t
)
\xi_2 (t)
ξ2(t) we want to maximize the variance subject to the orthogonality condition
∫
ξ
1
(
t
)
ξ
2
(
t
)
d
t
=
0
\int \xi_1 (t) \xi_2(t) dt = 0
∫ξ1(t)ξ2(t)dt=0
For ξ 1 , . . . , ξ d \xi_1, ..., \xi_d ξ1,...,ξd best approximation to x ( t ) x(t) x(t) is
x ^ ( t ) = x ˉ ( t ) + ( ∫ ( x ( t ) − x ˉ ( t ) ) ξ 1 ( t ) d t ) ξ 1 ( t ) + . . . + ( ∫ ( x ( t ) − x ˉ ( t ) ) ξ d ( t ) d t ) ξ d ( t ) = f 1 ξ 1 ( t ) + . . . + f d ξ d ( t ) . \begin{aligned} \hat{x} (t) &= \bar{x} (t) + \bigg( \int \Big( x(t) - \bar{x} (t) \Big) \xi_1 (t) ~ dt \bigg) \xi_1 (t) + ... \\\\ &~~~~~ + \bigg( \int \Big( x(t) - \bar{x} (t) \Big) \xi_d (t) ~ dt \bigg) \xi_d (t) \\\\ &= f_1 \xi_1 (t) + ... + f_d \xi_d (t). \end{aligned} x^(t)=xˉ(t)+(∫(x(t)−xˉ(t))ξ1(t) dt)ξ1(t)+... +(∫(x(t)−xˉ(t))ξd(t) dt)ξd(t)=f1ξ1(t)+...+fdξd(t).
which can be seen as a new basis!
For y ^ = g 1 ξ 1 ( t ) + . . . + g d ξ d ( t ) \hat{y} = g_1 \xi_1 (t) + ... + g_d \xi_d(t) y^=g1ξ1(t)+...+gdξd(t):
∫ ( x ^ ( t ) − y ^ ( t ) ) 2 d t = ∑ i = 1 d ( f i − g i ) 2 . \int \big( \hat{x}(t) - \hat{y} (t) \big)^2 ~ dt = \sum_{i=1}^d (f_i - g_i)^2. ∫(x^(t)−y^(t))2 dt=i=1∑d(fi−gi)2.
The covariance surface can be decomposed:
σ ( s , t ) = ∑ i = 1 ∞ d i i ξ i ( s ) ξ i ( t ) \sigma (s, t) = \sum_{i=1}^\infty d_{ii} \xi_i (s) \xi_i (t) σ(s,t)=i=1∑∞diiξi(s)ξi(t)
with the ξ i \xi_i ξi orthonormal.
- The ξ i ( t ) \xi_i (t) ξi(t) are the principal components; successively maximize V a r i [ ∫ ξ i ( t ) x j ( t ) d t ] Var_i \big[ \int \xi_i (t) x_j (t) ~ dt \big] Vari[∫ξi(t)xj(t) dt].
- d i i = V a r i [ ∫ ξ i ( t ) x j ( t ) d t ] d_{ii} = Var_i \big[ \int \xi_i (t) x_j (t) ~ dt \big] dii=Vari[∫ξi(t)xj(t) dt].
- d i i / ∑ d i i d_{ii} / \sum d_{ii} dii/∑dii is proportion of variance explained.
- ξ 1 , . . . \xi_1, ... ξ1,... is a basis system specifically designed for the x i ( t ) x_i (t) xi(t).
- Principal component scores are
f i j = ∫ ξ i ( t ) [ x j ( t ) − x ˉ ( t ) ] d t f_{ij} = \int \xi_i (t) [x_j(t) - \bar{x}(t)] ~ dt fij=∫ξi(t)[xj(t)−xˉ(t)] dt - Reconstrction of
x
i
(
t
)
x_i (t)
xi(t):
x i ( t ) = x ˉ ( t ) + ∑ j = 1 ∞ f i j ξ j ( t ) x_i (t) = \bar{x} (t) + \sum_{j = 1}^{\infty} f_{ij} \xi_j (t) xi(t)=xˉ(t)+j=1∑∞fijξj(t)
2.2 Computing FPCA
Components solve the eigen-equation:
∫ σ ( s , t ) ξ i ( t ) d t = λ ξ i ( t ) \int \sigma (s, t) \xi_i (t) ~ dt = \lambda \xi_i (t) ∫σ(s,t)ξi(t) dt=λξi(t)
Option 1:
- take a fine grid t = [ t 1 , . . . , t K ] \mathbf{t} = [t_1, ..., t_K] t=[t1,...,tK]
- find the eigen-decomposition of Σ ( t , t ) \Sigma (\mathbf{t}, \mathbf{t}) Σ(t,t)
- interpolate the eigenvectors
Option 2 (in fda library):
- if the x i ( t ) x_i(t) xi(t) have a common basis expansion, so must the eigen-functions;
- can re-express eigen-equation in terms of co-efficients;
- basis expansion will become apparent for smaller eigenvalues.
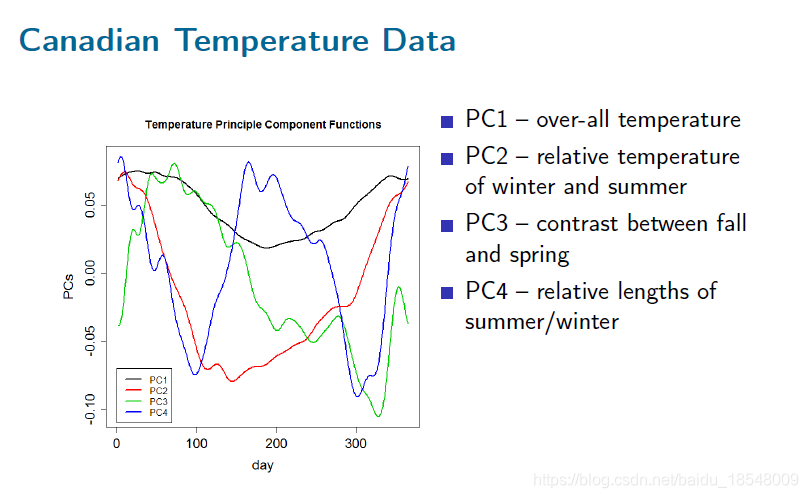
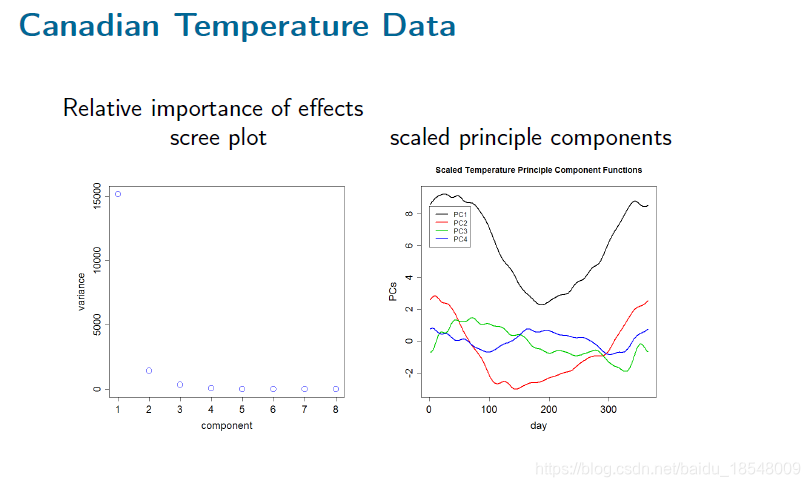
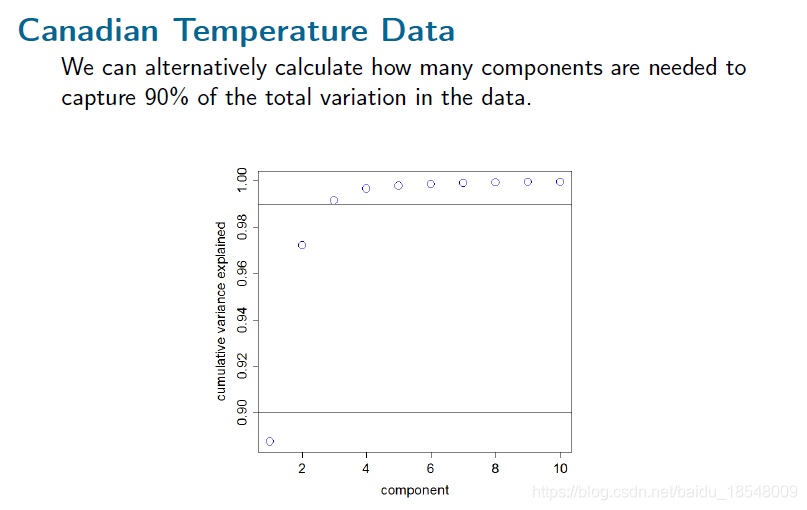
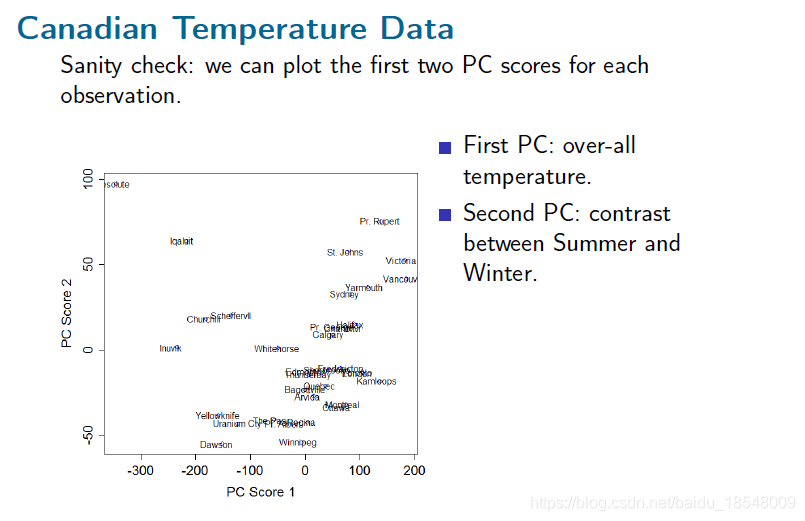
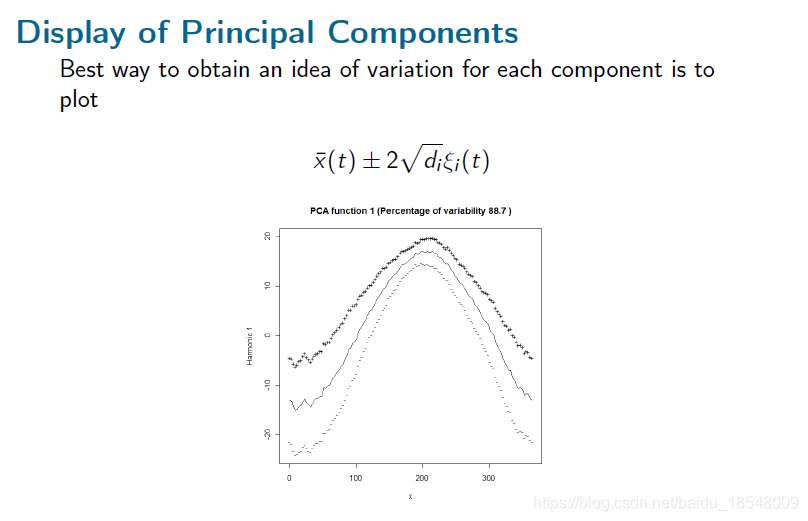
2.3 Varimax rotations
A set of principal components defines a subspace. Within that space, we can try to find a more interpretable basis. That amounts to a rotation of the coordinate axes.
The basic idea is to try to find coordinate system where PC loadings are either very large or very small.
The varimax criterion is
m a x i m i z e ∑ V a r ( u i 2 ) . maximize \sum Var(u_i^2). maximize∑Var(ui2).
2.4 Summary
- PCA = means of summarizing high dimensional covariation;
- fPCA = extension to infinite-dimensional covariation;
- Representation terms of basis functions for fast(er) computation;
- Varimax rotations = focus on particular regions; nice display properties.
3 Smoothed PCA
3.1 A general perspective of PCA
For observations x 1 , x 2 , . . . , x n x_1, x_2, ..., x_n x1,x2,...,xn (vectors, functions, …), we want to find ξ 1 \xi_1 ξ1 so that
∑ ∥ x i − < x i , ξ 1 > ξ 1 ∥ \sum \| x_i - <x_i, \xi_1> \xi_1 \| ∑∥xi−<xi,ξ1>ξ1∥
is as small as possible.
< x i , ξ 1 > <x_i, \xi_1> <xi,ξ1> is the best multiplier of ξ 1 \xi_1 ξ1 to fit x i x_i xi.
Now we want ξ 2 \xi_2 ξ2 to be the next best such that < ξ 2 , ξ 1 > = 0 <\xi_2, \xi_1> = 0 <ξ2,ξ1>=0.
3.1.1 Inner product
Vectors are otrhogonal if they intersect at right angles.
x \mathbf{x} x and y \mathbf{y} y are orthogonal if x T y = 0 \mathbf{x}^T \mathbf{y} = 0 xTy=0 (i.e. ∑ x i y i = 0 \sum x_i y_i = 0 ∑xiyi=0).
In order to deal with x ( t ) x(t) x(t) that are functions, multivariate functions, or mixed functions and scalars, we need a more general notation.
This will also help us understand smoothing a little more.
An inner produnct is a symmetric bilinear operator <., .> on a vector space F \mathcal{F} F taking values in R \mathbb{R} R:
-
<
x
,
y
>
=
<
y
,
x
>
<x, y> = <y, x>
<x,y>=<y,x>;
(symmetry) - < a x , y > = a < x , y > <ax, y> = a <x, y> <ax,y>=a<x,y>;
-
<
x
+
y
,
z
>
=
<
x
,
z
>
+
<
y
,
z
>
<x+y, z> = <x, z> + <y, z>
<x+y,z>=<x,z>+<y,z>;
(linearity for one element) -
<
x
,
x
>
>
0
<x, x> ~ > 0
<x,x> >0 with
x
x
x a non-zero vector.
(positivity)
For example:
- Euclidean space: < x , y > = x T y <x, y> = x^Ty <x,y>=xTy.
- L 2 ( R ) \mathcal{L}^2 (\mathbb{R}) L2(R): ∫ x ( t ) y ( t ) d t \int x(t) y(t) ~ dt ∫x(t)y(t) dt.
Associated notion of distance or size:
∥ x − y ∥ = < x − y , x − y > . \| x - y \| = < x - y, x - y>. ∥x−y∥=<x−y,x−y>.
So to get to x x x as close as possible in the direction y y y:
min a < x − a y , x − a y > , \min_a <x - ay, x - ay>, amin<x−ay,x−ay>,
which is solved at
a = < x , y > / < y , y > . a = <x, y> / <y, y>. a=<x,y>/<y,y>.
If < y , y > = 1 <y, y> = 1 <y,y>=1, < x , y > <x, y> <x,y> is a measure of commonality.
If < y , z > = 0 <y, z> = 0 <y,z>=0 minimum of ∥ x − a y − b z ∥ \| x - ay - bz \| ∥x−ay−bz∥ at
a = < x , y > , b = < x , z > . a = <x, y>, ~ b = <x, z>. a=<x,y>, b=<x,z>.
3.1.2 Inner produncts and PCA
For a collection x 1 , x 2 , . . . , x n x_1, x_2, ..., x_n x1,x2,...,xn, seek a probe ξ \xi ξ to maximize
V a r [ < ξ , x i > ] . Var[<\xi, x_i>]. Var[<ξ,xi>].
Require < ξ i , ξ j > = δ i j <\xi_i, \xi_j> = \delta_{ij} <ξi,ξj>=δij.
Implies optimal reconstruction:
[ < x 1 , ξ 1 > ⋯ < x 1 , ξ d > ⋮ ⋮ < x n , ξ 1 > ⋯ < x n , ξ d > ] , \left[ \begin{matrix} <x_1, \xi_1> & \cdots & <x_1, \xi_d> \\ \vdots & & \vdots\\ <x_n, \xi_1> & \cdots & <x_n, \xi_d> \end{matrix} \right], ⎣⎢⎡<x1,ξ1>⋮<xn,ξ1>⋯⋯<x1,ξd>⋮<xn,ξd>⎦⎥⎤,
best summarization of x 1 , . . . , x n x_1, ..., x_n x1,...,xn with d d d numbers.
3.1.3 Defining new inner products
For a multivariate function x ( t ) = ( x 1 ( t ) , x 2 ( t ) ) \mathbf{x}(t) = \big( x_1(t), x_2(t) \big) x(t)=(x1(t),x2(t)).
A new inner product is
< ( x 1 , x 2 ) , ( y 1 , y 2 ) > = < x 1 , y 1 > + < x 2 , y 2 > , <(x_1, x_2), (y_1, y_2)> = <x_1, y_1> + <x_2, y_2>, <(x1,x2),(y1,y2)>=<x1,y1>+<x2,y2>,
which can be check that this is a bilinear form.
Note that
< ( x 1 ( t ) , x 2 ( t ) ) , ( y 1 ( t ) , y 2 ( t ) ) > = 0 <\big( x_1 (t), x_2 (t) \big), \big( y_1 (t), y_2 (t) \big) > = 0 <(x1(t),x2(t)),(y1(t),y2(t))>=0
does NOT imply
< x 1 , y 1 > = 0 a n d < x 2 , y 2 > = 0 <x_1, y_1> = 0 ~~ and ~~ <x_2, y_2> = 0 <x1,y1>=0 and <x2,y2>=0
3.1.4 fPCA with multivariate functions
If we have x i ( t ) x_i(t) xi(t) and y i ( t ) y_i(t) yi(t), i = 1 , . . . , n i = 1, ..., n i=1,...,n.
Then we want to find ( ξ x ( t ) , ξ y ( t ) ) \big( \xi_x (t), \xi_y (t) \big) (ξx(t),ξy(t)) to maximize
V a r [ ∫ ξ x ( t ) x i ( t ) d t + ∫ ξ y ( t ) y i ( t ) d t ] . Var \bigg[ \int \xi_x (t) x_i (t) ~ dt + \int \xi_y (t) y_i (t) ~ dt \bigg]. Var[∫ξx(t)xi(t) dt+∫ξy(t)yi(t) dt].
This is like putting x x x and y y y together end-to-end:
z ( t ) = { x ( t ) , t ≤ T y ( t ) , t > T . z(t) = \begin{cases} x(t), ~~~ t \leq T \\ y(t), ~~~ t > T \end{cases}~~. z(t)={x(t), t≤Ty(t), t>T .
3.2 Smoothing and fPCA
When observed functions are rough, we may want the PCA to be smooth
- reduces high-frequency variation in the x i ( t ) x_i(t) xi(t);
- provides better reconstruction of future x i ( t ) x_i(t) xi(t).
We therefore want to find a way to impose smoothness on the principal components.
3.2.1 Including derivatives
Consider the multivariate function ( x ( t ) , L x ( t ) ) \big( x(t), Lx(t) \big) (x(t),Lx(t)), where L x ( t ) Lx(t) Lx(t) is the acceleration function (i.e. a function of D n x ( t ) D^n x(t) Dnx(t) ).
Inner product:
< x , y > = < ( x ( t ) , L x ( t ) ) , ( y ( t ) , L y ( t ) ) > = ∫ x ( t ) y ( t ) d t + λ ∫ L x ( t ) L y ( t ) n d t . \begin{aligned} <x, y> &= < \big( x(t), Lx(t)), (y(t), Ly(t) \big) > \\\\ &= \int x(t) y(t) ~ dt + \lambda \int Lx(t) Ly(t)n ~ dt. \end{aligned} <x,y>=<(x(t),Lx(t)),(y(t),Ly(t))>=∫x(t)y(t) dt+λ∫Lx(t)Ly(t)n dt.
Smoothing:
- think of y = ( y 1 ( t ) , y 2 ( t ) ) = ( y ( t ) , 0 ) \mathbf{y} = \big( y_1 (t), y_2 (t) \big) = \big( y(t), 0 \big) y=(y1(t),y2(t))=(y(t),0);
- try to fit with x = ( x ( t ) , L x ( t ) ) \mathbf{x} = \big( x(t), Lx(t) \big) x=(x(t),Lx(t));
- but the norm is defined by the Sobolev inner product above.
3.2.2 A new measure of size
Usually, we measure size in the L 2 L^2 L2 norm
∥ ξ ( t ) ∥ 2 2 = ∫ ξ ( t ) 2 d t . \| \xi (t) \|_2^2 = \int \xi (t)^2 ~ dt. ∥ξ(t)∥22=∫ξ(t)2 dt.
But penalization methods implicitly use a *Sobolev norm:
∥ ξ ( t ) ∥ L 2 = ∫ ξ ( t ) 2 d t + λ ∫ [ L ξ ( t ) ] 2 d t . \| \xi(t) \|_L^2 = \int \xi (t)^2 ~ dt + \lambda \int [L \xi(t)]^2 ~ dt. ∥ξ(t)∥L2=∫ξ(t)2 dt+λ∫[Lξ(t)]2 dt.
Search for the ξ \xi ξ that maximizes
V a r [ ∫ ξ ( t ) x i ( t ) d t ] ∥ ξ ( t ) ∥ L 2 = V a r [ ∫ ξ ( t ) x i ( t ) d t ] ∫ ξ ( t ) 2 d t + λ ∫ [ L ξ ( t ) ] 2 d t . \frac{Var \big[ \int \xi(t) x_i (t) ~ dt \big]}{\| \xi(t) \|_L^2} = \frac{Var \big[ \int \xi(t) x_i (t) ~ dt \big]}{\int \xi (t)^2 dt + \lambda \int \big[ L \xi (t) \big]^2dt}. ∥ξ(t)∥L2Var[∫ξ(t)xi(t) dt]=∫ξ(t)2dt+λ∫[Lξ(t)]2dtVar[∫ξ(t)xi(t) dt].
3.2.3 Size and orthogonality
- As λ \lambda λ increases, emphasize making L ξ ( t ) L \xi(t) Lξ(t) small over maximizing the variance.
- Successive
ξ
i
\xi_i
ξi now satisfy
∫ ξ i ( t ) ξ j d t + λ ∫ L ξ i ( t ) L ξ j ( t ) d t = 0. \int \xi_i (t) \xi_j dt + \lambda \int L \xi_i (t) L \xi_j (t) dt = 0. ∫ξi(t)ξjdt+λ∫Lξi(t)Lξj(t)dt=0. - Effectively “pretending” that L x i ( t ) = 0 Lx_i(t) = 0 Lxi(t)=0.
- Coeffiicients of best (in least-squares sense) fit no longer ∫ ξ i ( t ) x j ( t ) d t \int \xi_i (t) x_j (t) dt ∫ξi(t)xj(t)dt.
- Best fit coefficents now also depend on which eigenfunctions are used.
3.3 Summary
- Multivariate and Mixed PCs – like extending the vector;
- Need to think about weighting;
- Smoothing: may be done through a new inner product;
- Cross Validation: objective way to work out if smoothing is doing anything useful for you;
- Can use fPCA to help reconstruct partially-observed functions
4 Research papers
Liu, C., Ray, S., Hooker, G. and Friedl, M. (201), Functional principal component and factor analysis of spatially correlated data,
Statistics and Computing
Liu, C., Ray, S., Hooker, G. and Friedl, M. (2012), Functional factor analysis for periodic remote sensing data, The Annals of Applied Statistics 6(2), 601–624.
Paul, D. and Peng, J. (2011), Principal components analysis for sparsely observed correlated functional data using kernel smoothing method. Electronic Journal of Statistics (5).
Yao, F., Muller, H. and Wang, J. (2005), Functional data analysis for sparse longitudinal data, Journal of the American Statistical Association 100(470), 577–590.

















 147
147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









