









引言
风控模型能够准确判别好坏的基本前提是我们精准定义了好坏样本。 如何定义好坏通常被认为是风控建模中最难的环节。
在风控中,当定义风险模型标签时,我们一般会使用类似3T ever 15(该客户在3期应还之中是否有至少一笔超过15天以上的逾期表现)这样的标签来界定好坏样本,在实际工作中,我们到底应该选几期来看,应该用多少天逾期作为标准,又如何证明我们定义的坏真的足够坏,本篇文章就来探讨一下这三个问题。
一、界定天数——收回率曲线
首先,风控中基本不会用大于等于1天逾期作为好坏样本的界定,因为仅有几天逾期的人很可能真是忘了还了,并非真的坏;另一方面,风控体系中都会有催收系统,逾期几天的人大部分是能够催回来的,所以风控中常常把15天、30天甚至60,90天作为是否逾期的判别,具体应该用多少天,我们可以通过收回率曲线帮我们界定:
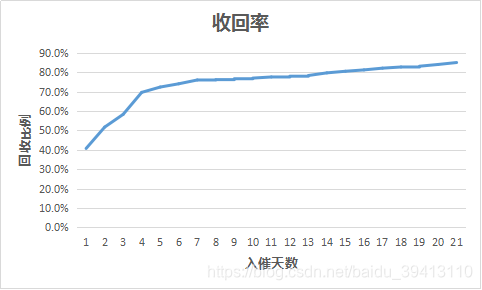
如图是一张收回率曲线,横坐标代表入催天数,可以理解为这个人逾期的第n天,纵坐标为收回比例,这张图标呈现的信息是,在应还款日后的第1天,有40%入催的人可以被催回还款,到第4天,有70%能够催回,越往后曲线变得愈发平缓,每天能催回的人数越来越少。
假设我们以逾期天数是否超过4天作为好坏判别的临界点,那有30%的人都会被我们界定为坏。假如最终85%的人都可以被催回,即最后真正坏的只有15%的人,那说明有一半能够还款的人都被我们误判为了坏;如果我们以15天作为临界点,我们能够界定出20%的坏人,其中误判的人就只占1/4。
当然,天数越长,我们对坏的定位就越精准,但同时,有足够表现期并可用来建模的样本也会越少;所以,我们必须在精准度和样本量之间做一个权衡;另一方面,入催天数越长,新增可催回的人数也就越少,意味着对好坏定义精准度的提升也就越有限。
二、界定期数——vintage曲线
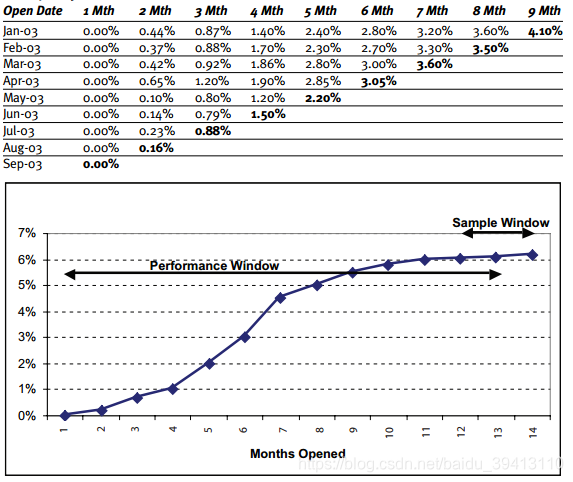
如上图描绘的是vintage表格及曲线,表格第一行代表:把所有一月份借款的人作为分析样本,在他们还款日后的1,2,3……个月后,有多少比例的人发生了逾期。当我们把数字描绘成曲线后,可以看到,随期数增多,逾期率也会跟着上升,前期快速增长,10个月后逐渐趋于稳定。
最理想的状态下,我们会把坏账率趋于稳定的那个时点作为好坏的界定点,比如10期。选择的期数越少,我们遗漏的坏人也就越多,假如我们以7期作为坏样本的界定,可以捕捉到约4.5%的坏人,但当全账龄走完后,逾期率大概能达到6%,所以7期为标准大概会漏掉约1.5%的坏人。
同样,我们考察的期数越长,越能够精确定位到坏人,但样本也会随之大大减少。所以vintage曲线也只是帮我们做一个权衡,评估在每一期我们牺牲了多少精准度。
三、好坏定义的验证——滚动率分析
当我们敲定了一个好坏样本的定义方式后,我们可以通过滚动率分析来证明我们定义的坏确实足够坏。
滚动率分析的核心思想就是把时间段分为两部分,考察在前半时段我们定义的坏到后半时段时,有多少比例依然为坏。以循环额度的信用卡产品为例,下图呈现的是一个完整24个月的周期被拆分为“前”、“后”两个时段,在前12个月中逾期30、60、90天以上的人在后12个月中是如何转换的。
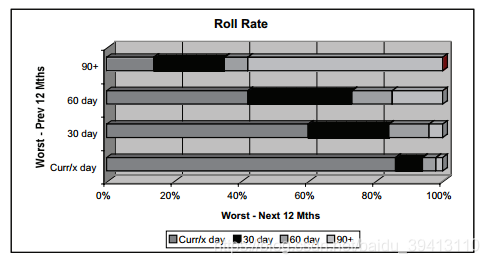
可以看到,如果以30天逾期作为坏的界定,在后12个月中,只有40%的人仍然出现了30+的逾期,而如果以90天作为界定,在后12个月中有60%的人仍然为我们定义的坏。滚动率的分析可以证明以90天为界定定义出的坏人在时间上是稳定的,即大部分前期逾期90天的人后期都不会再变好,以此证明了这种定义方法的合理性。
四、实际情况
以上的分析都只能帮我们从数据上去评估我们定义好坏的精准度,但实际业务中往往没有足够的余地让我们去找到那个最优解,一是受限于样本量,越严苛的定义越会导致样本过少而无法建模,尤其对于新开的业务来讲。二是受限于样本时效性,在市场环境快速变化的背景下,客户群体也在不断变化,意味着只有用最新的数据建模,才会对未来的客户群体有预测性,而这也直接限制了我们定义好坏时的期数选择。所以实际业务中,常用2-4期来定义好坏,某些情况下甚至只用1期。当然,最终模型建好,还是要在不同期数的好坏定义下进行验证的。
*参考书目:《Credit Risk Scorecards》Naeem Siddiqi

















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









