









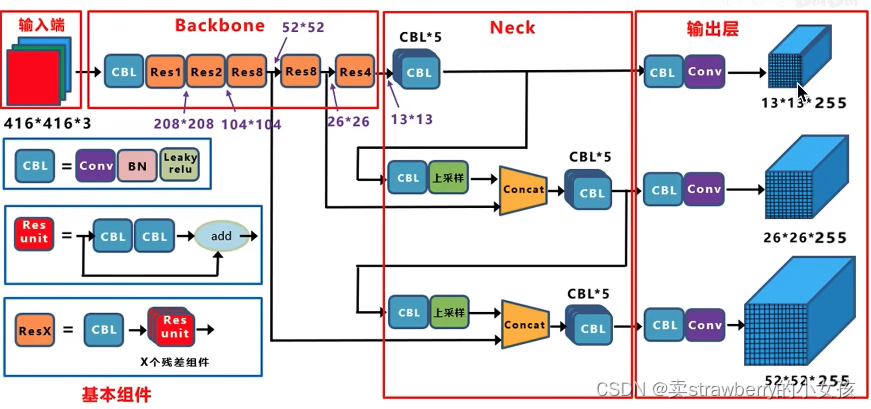
一、网络解析
输入:416x416x3
输出:3个feature map:13x13x255、26x26x255、52x52x255(255 = 3x85 =3 x(4+1+80) )
分别下采样32倍、16倍、8倍得到输出13x13x255、26x26x255、52x52x255,在MCCOCO目标检测竞赛中,小物体<32x32,大物体>96x96
13x13x255:13x13个grid cell,每一个grid cell 对应原图上的感受野是32X32,负责预测大物体
26x26x255:26x26个grid cell,每一个grid cell 对应原图上的感受野是16X16,负责预测中等物体
52x52x255:52x52个grid cell,每一个grid cell 对应原图上的感受野是8X8,负责预测小物体
1、分别抽取到下采样32倍、16倍、8倍的特征
2、下采样32倍的特征变成13x13x255 ——> 经过一次上采样2倍变成26x26 ——> 和26x26尺度的特征进行拼接(Concat,沿厚度方向堆落)——> 26x26的数据结构再经过上采样变成52x52 ——> 和52x52尺度的特征进行拼接
3、该结构可以实现多尺度特征融合和不同尺寸物体的预测,既能发挥深层网络的特化抽象的语义信息,又能发挥浅层网络像素结构的底层的细粒度的信息
+ 深度学习浅层学习:边缘、形状、转角、斑块、颜色等底层细粒度的信息
+ 深度学习深层学习:纹理、眼睛、腿等抽象特化的语义信息
4、CBL = Conv + BN + Leaky relu(每个卷积层之后包含一个批量归一化层和一个Leaky ReLU,目的是为了防止过拟合)
5、Res unit :残差模块
二、YOLOV3 骨干网络
darknet-53去除了全局平均池化层和全连接层,是一个全卷积网络
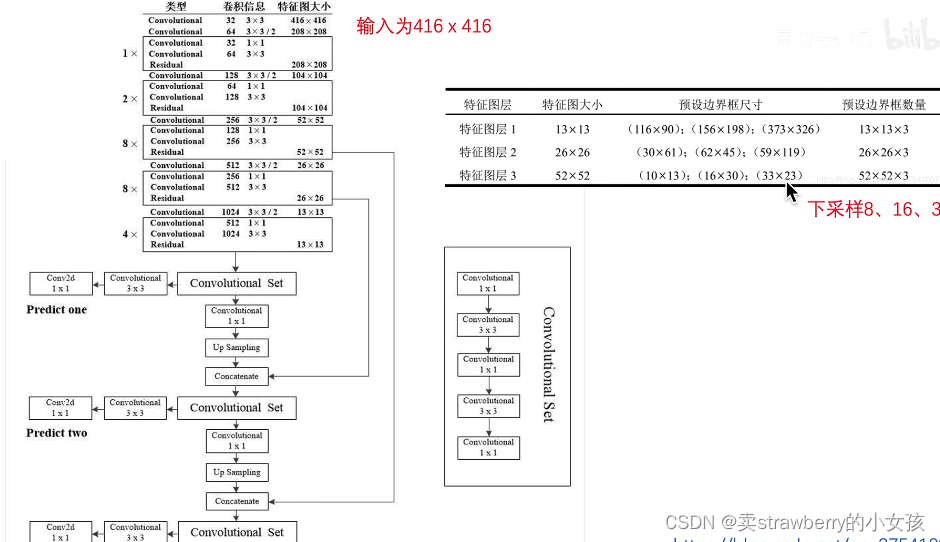
anchor数:
yolov1:7x7x2 = 98
yolov2:13x13x5 = 845
yolov3:3x(13x13+26x26+52x52) = 10647
三、训练

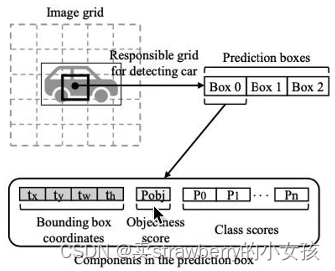
对于负责拟合物体的grid cell:
对标注框中心点所在的grid cell产生的3个anchor(三个尺寸 13x13、26x26、52x52),由与物体实际标注iou重合度最高的那个anchor所在的grid cel来拟合物体
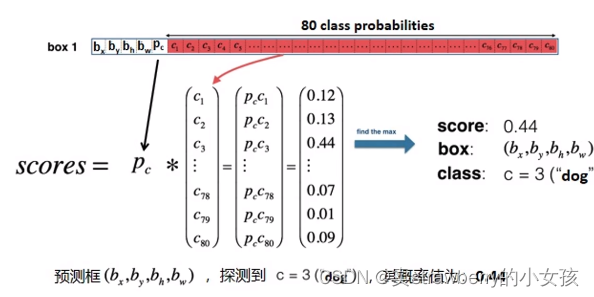
每个grid cell生成3个anchor,每个anchor对应一个预测框,每一个预测框5+80(x,y,w,h,objectness score,coco数据集80个类)
+ objectness score : 预测框包含目标的概率
+ class scores : 在预测框已经包含目标的概率下80个类别的条件概率
正负样本:
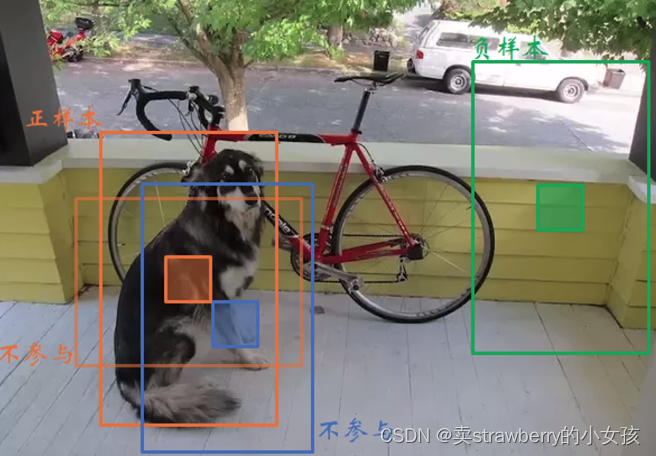
对于人工设置的阈值(yolov3为0.5)
正样本:与ground_truth 的IOU(大于设定的阈值)最大的anchor
忽略:与ground_truth的IOU大于设定的阈值,但不是最大的那个,忽略
负样本:与ground_truth的IOU小于设定的阈值
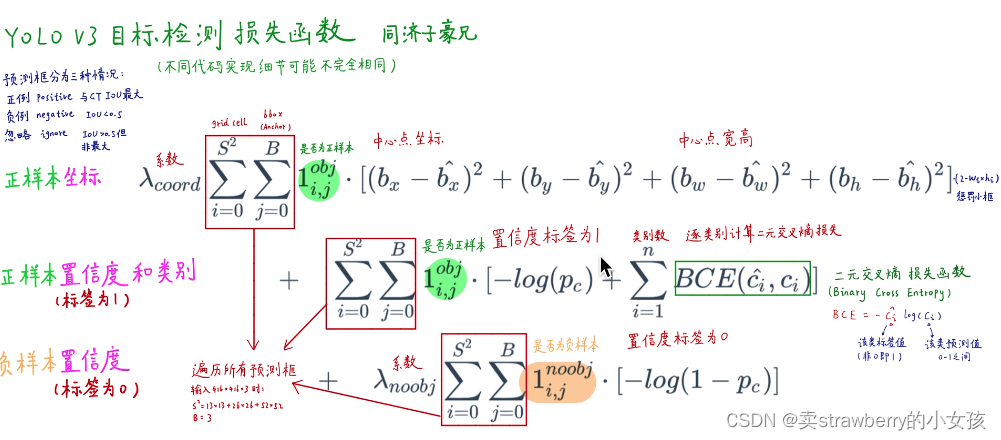
损失函数:
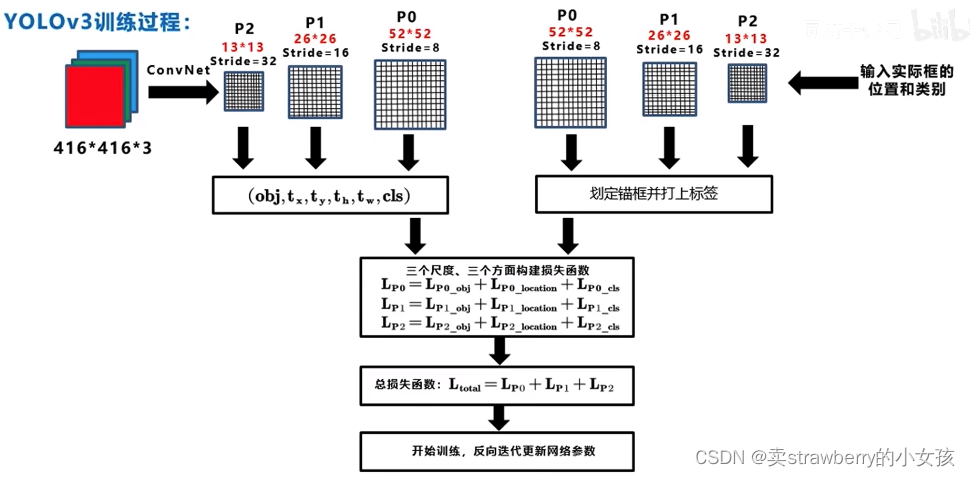
四、训练过程
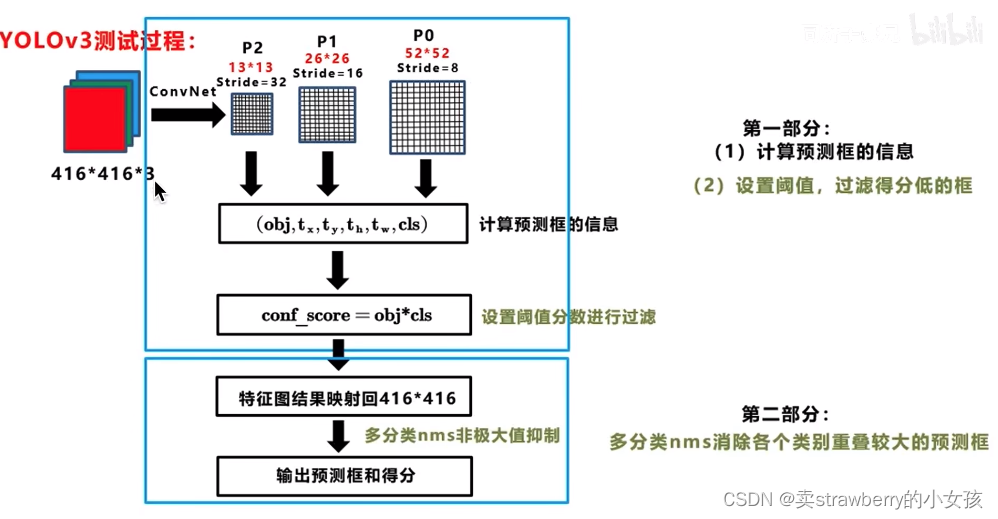

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









