







机器学习算法
1.监督学习 用的多
2.无监督学习
1.监督学习
监督学习算法的关键特征是我们给学习算法示例。这包括正确的答案。意思就是,对于给定的输入x的正确标签y,是通过看到正确的输入x和期望的输出标签y,学习算法最终学会只接受输入而不接受输出标签,并给出输出的合理准确的预测或者猜测。
学习输入、输出或x到y的映射。
例子:

具体的例子,根据大小预测房价,得到一个数,或者更多可能的数。
可以用拟合直线,拟合曲线或者其他更复杂的函数。
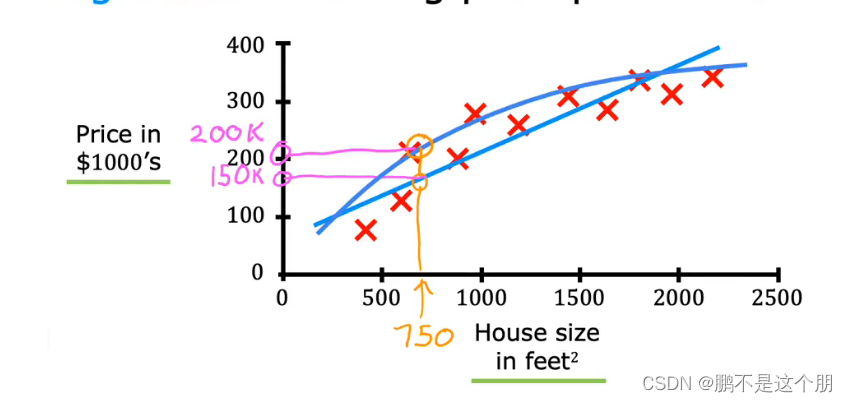
我们给算法一个数据集,即所谓正确的答案。
房价预测类型的supervised learning叫做回归
两类监督学习问题:
regression回归(第一类)
classification分类(第二类)
例子:以乳腺癌检测问题为例
output仅为1或0
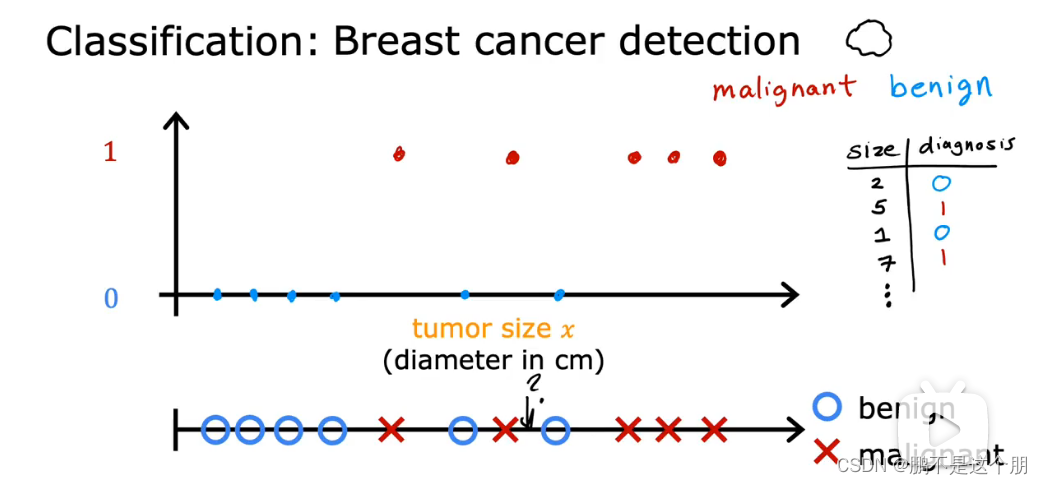
事实证明,话可能有两个以上的输出
分类算法预测类别,类别既可以是数字也可以是非数字。
分类预测一组有限可能的输出类别。
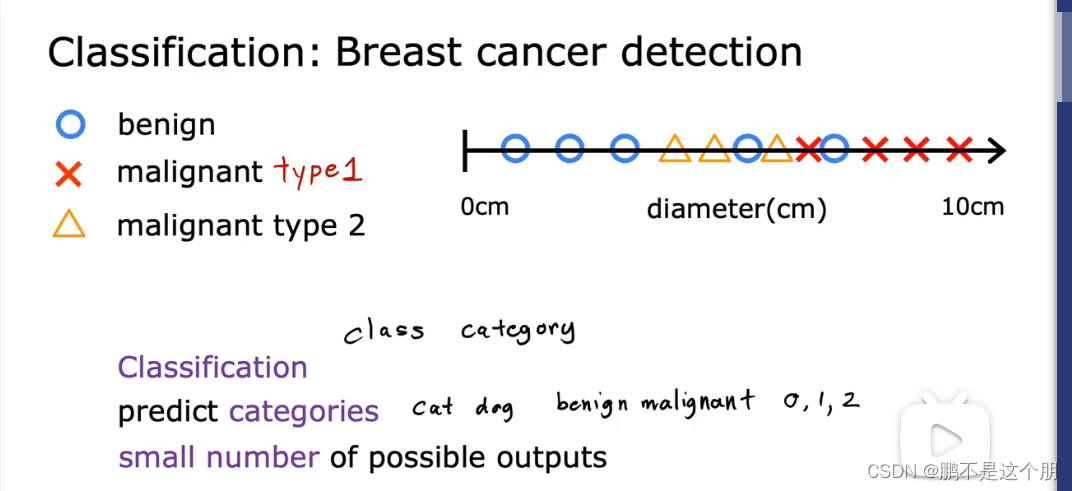
引入多个指标,年龄和肿瘤大小


2.无监督学习
右边的图片,没有给出标签,告诉这个肿瘤是恶性还是良性。
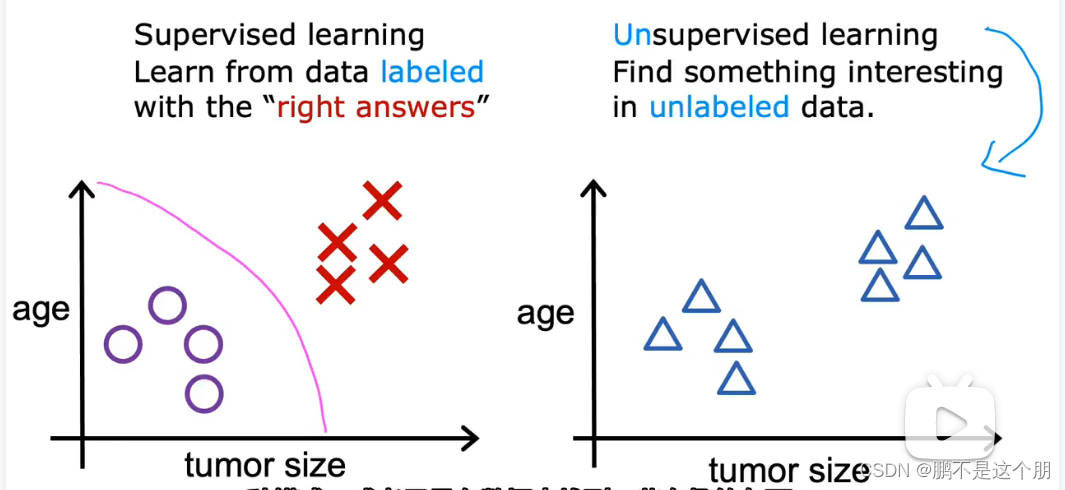
在数据集中我们的工作是找到某种结构或者模式,或者子啊数据中找到一些有趣的事情。这是无监督学习。
无监督学习算法可能决定数据可以分配给两个不同的组或两个不同的集群。这是一种特殊的类型的无监督学习,成为聚类算法。
我们没有提前告诉算法,有具有特征1的人,有具有特征的2种人。
聚类算法是一种无监督学习算法,获取没有标签的数据并尝试将它们自动分组到集群中。
正式定义:仅有输入x,没有标签y,算法需要找到数据中的结构。
另外两类无监督学习:
1.异常检测
2.降维















 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









