







监督学习及其目标函数
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。
模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子(一般来说,监督学习可以看做最小化下面的目标函数):
或者
式子左边表示经验风险函数,损失函数是其核心部分;式子右边是正则项。式子整体是结构风险函数,其由经验风险函数和正则项组成。
其中,第一项L(yi,f(xi;w)) 衡量我们的模型(分类或者回归)对第i个样本的预测值f(xi;w)和真实的标签yi之前的误差。因为我们的模型是要拟合我们的训练样本的,所以我们要求这一项最小。即前面的均值函数表示的是经验风险函数,L代表的是损失函数;
但正如上面说言,我们不仅要保证训练误差最小,我们更希望我们的模型测试误差小,所以我们需要加上第二项,也就是对参数w的规则化函数Ω(w)去约束我们的模型尽量的简单。即后面的Φ是正则化项(regularizer)或者叫惩罚项(penalty term),它可以是L1,也可以是L2,或者其他的正则函数。
整个式子表示的意思是找到使目标函数最小时的θ值。机器学习的大部分带参模型都和这个不但形似,而且神似,其实大部分无非就是变换这两项而已。
损失函数/loss函数
对于第一项Loss函数,如果是Square loss,那就是最小二乘;如果是Hinge Loss,那就是著名的SVM;如果是exp-Loss,那就是 Boosting;如果是log-Loss,那就是Logistic Regression;还有等等。不同的loss函数,具有不同的拟合特性,这个也得就具体问题具体分析的。
loss函数一般都是通过mle推导出来的。使用最大似然来导出代价函数的方法的一个优势是,它减轻了为每个模型设计代价函数的负担。明确一个模型p(y | x)则自动地确定了一个代价函数log p(y | x)。[深度学习]
下面主要列出几种常见的损失函数:
- 平方损失
- 0-1损失
- Log损失
- Hinge损失
- 指数损失
- 感知损失
规则项参考[最优化方法:范数和规则化regularization]。
Note: lz: Loss functions一般指一个样本的;而cost functions指N个样本的。但是有时是混用的。
平方损失函数(最小二乘法, Ordinary Least Squares )
最小二乘法是线性回归的一种,OLS将问题转化成了一个凸优化问题。在线性回归中,它假设样本和噪声都服从高斯分布(为什么假设成高斯分布呢?其实这里隐藏了一个小知识点,就是中心极限定理),最后通过极大似然估计MLE可以推导出最小二乘式子,即平方损失函数可以通过线性回归在假设样本是高斯分布的条件下推导得到。
最小二乘的基本原则是:最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。换言之,OLS是基于距离的,而这个距离就是我们用的最多的欧几里得距离。为什么它会选择使用欧式距离作为误差度量呢(即Mean squared error, MSE),主要有以下几个原因:
- 简单,计算方便;
- 欧氏距离是一种很好的相似性度量标准;
- 在不同的表示域变换后特征性质不变。
平方损失(Square loss)的标准形式
当样本个数为n时,此时的损失函数变为:
Y-f(X)表示的是残差,整个式子表示的是残差的平方和,而我们的目的就是最小化这个目标函数值,也就是最小化残差的平方和(residual sum of squares,RSS)。
而在实际应用中,通常会使用均方差(MSE)作为一项衡量指标,公式如下:
上面提到了线性回归,这里额外补充一句,我们通常说的线性有两种情况,一种是因变量y是自变量x的线性函数,一种是因变量y是参数的线性函数。在机器学习中,通常指的都是后一种情况。
最小二乘法解线性回归
首先构建Design matrix



Note: 用这种方法时不需要feature scaling。
[Linear Regression with Multiple Variables多变量线性规划 (Week 2) ]
最小二乘解

log对数损失函数(逻辑回归)
在逻辑回归的推导中,它假设样本服从伯努利分布(0-1分布),然后求得满足该分布的似然函数,接着取对数求极值等等。但是逻辑回归并没有求似然函数的极值,而是把极大化当做是一种思想,进而推导出它的经验风险函数为:最小化负的似然函数(即max F(y, f(x)) —-> min -F(y, f(x)))。从损失函数的视角来看,它就成了log损失函数了。Log损失log(1+exp(−m)) 是0-1损失函数的一种代理函数。
log损失函数的标准形式:交叉熵
取对数是为了方便计算极大似然估计,因为在MLE中直接求导比较困难,所以通常都是先取对数再求导找极值点。损失函数L(Y, P(Y|X))表达的是样本X在分类Y的情况下,使概率P(Y|X)达到最大值(换言之,就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值;或者说什么样的参数才能使我们观测到目前这组数据的概率最大)。因为log函数是单调递增的,所以logP(Y|X)也会达到最大值,因此在前面加上负号之后,最大化P(Y|X)就等价于最小化L了。
对于Logistic回归算法,分类器(针对二分类而言)可以表示为:
为了求解其中的参数,通常使用极大似然估计的方法,具体的过程如下:
1、似然函数
其中,
2、log似然
3、需要求解的是使得log似然取得最大值的。将其改变为最小值,可以得到如下的形式:
逻辑回归的P(Y=y|x)(单值时)表达式(为了将类别标签y统一为1和0,下面将表达式分开表示):

将它带入到上式−logP(Y|X),通过推导可以得到
logistic的损失函数表达式


蓝色线代表logistic regression, 紫洋红色线代表SVM;
PDF参考一下:Lecture 6: logistic regression.pdf。
Hinge损失函数(SVM)
SVM的损失函数是hinge损失函数。
在线性支持向量机中,最优化问题可以等价于下列式子:
下面来对式子做个变形,令:,于是,原式就变成了:
如若取,式子就可以表示成:
可以看出,该式子与下式非常相似:
前半部分中的就是hinge损失函数,而后面相当于L2正则项。
Hinge 损失函数的标准形式
或者表示为[ 1 - t(wx + b) ]+

可以看出,当|y|>=1时,L(y)=0。[Hinge-loss]
核函数
在libsvm中一共有4中核函数可以选择,对应的是-t参数分别是:
- 0-线性核;
- 1-多项式核;
- 2-RBF核;
- 3-sigmoid核。
[http://math.stackexchange.com/questions/782586/how-do-you-minimize-hinge-loss]
感知损失(感知机算法)
感知损失是Hinge损失的一个变种,感知损失的具体形式如下: 。运用感知损失的典型分类器是感知机算法。
感知机算法的损失函数
感知机算法只需要对每个样本判断其是否分类正确,只记录分类错误的样本,其损失函数为:
两者的等价
对于感知损失:
或者表示为[ - t(wx + b) ]+
优化的目标为:
在上述的函数中引入截距,即:
上述的形式转变为:
对于max函数中的内容,可知:
对于错误的样本,有:
类似于Hinge损失,令下式成立:
约束条件为:
则感知损失变成:
即为:
Hinge损失对于判定边界附近的点的惩罚力度较高,而感知损失只要样本的类别判定正确即可,而不需要其离判定边界的距离,这样的变化使得其比Hinge损失简单,但是泛化能力没有Hinge损失强。
指数损失函数(Adaboost)
学过Adaboost算法的人都知道,它是前向分步加法算法的特例,是一个加和模型,损失函数就是指数函数。
在Adaboost中,经过m此迭代之后,可以得到 :
Adaboost每次迭代时的目的是为了找到最小化下列式子时的参数和G:
指数损失函数(exp-loss)的标准形式

可以看出,Adaboost的目标式子就是指数损失,在给定n个样本的情况下,Adaboost的损失函数为:
在AdaBoost中,数据权重的更新方式为:
AdaBoost的训练的目标就是减少,因此其风险函数为:
其损失函数为:
关于Adaboost的推导,可以参考Wikipedia: AdaBoost 或者《统计学习方法》P145。
其它损失函数
除了以上这几种损失函数,常用的还有:
0-1损失函数
01 loss是最本质的分类损失函数,但是这个函数不易求导,在模型的训练不常用,通常用于模型的评价。0-1损失是一个非凸的函数,在求解的过程中,存在很多的不足,通常在实际的使用中将0-1损失函数作为一个标准,选择0-1损失函数的代理函数(如log损失函数,hinge损失函数(0-1损失函数的上界))作为损失函数。the zero-one loss is what you actually want in classification. Unfortunately it is non-convex and thus not practical since the optimization problem becomes more or less intractable。
在分类问题中,可以使用函数的正负号来进行模式判断,函数值本身的大小并不是很重要,0-1损失函数比较的是预测值与真实值的符号是否相同,0-1损失的具体形式如下:
以上的函数等价于下述的函数:
0-1损失并不依赖m值的大小,只取决于m的正负号。
绝对值损失函数
Loss函数总结
- squared loss方便求导,缺点是当分类正确的时候随着的增大损失函数也增大。
- cross entropy方便求导,逼近01 loss。
- Hinge Loss当,损失为0,对应分类正确的情况;当时,损失与成正比,对应分类不正确的情况(软间隔中的松弛变量)。
- exponential loss方便求导,逼近01 loss。
- squared loss, cross entropy,exponential loss以及hinge loss的左侧都是凸函数,方便求导有利于优化问题的求解;同时这些loss函数都是01 error的上界,可以通过减少loss来实现01问题的求解,即求解分类问题。
- the zero-one loss is what you actually want in classification. Unfortunately it is non-convex and thus not practical since the optimization problem becomes more or less intractable
- the hinge loss (used in support-vector classification) results in solutions which are sparse in the data (due to it being zero for) and is relatively robust to outliers (it grows only linearly for
- ) . It doesn't provide well-calibrated probabilities.
- the log-loss (used, e.g., in logistic regression) results in well calibrated probabilities. It is thus the loss of choice if you don't want only binary predictions but also probabilities for the outcomes. On the downside, it's solutions are not sparse in the data space and it is more influenced by outliers than the hinge loss.
- the exponential loss (used in AdaBoost) is very susceptible to outliers (due to its rapid increase when
- ). It is primarily used in AdaBoost since it results there in a simple and efficient boosting algorithm.
- the perceptron loss is basically a shifted version of the hinge loss. The hinge loss also penalizes points which are on the correct side of the boundary but very close to it (maximum-margin principle). The perceptron loss, on the other hand, is happy as long as a datapoint is on the correct side of the boundary, which leaves the boundary under-determined if the data is truly linearly separable and results in worse generalization than a maximum-margin boundary.
几种损失函数的可视化图像

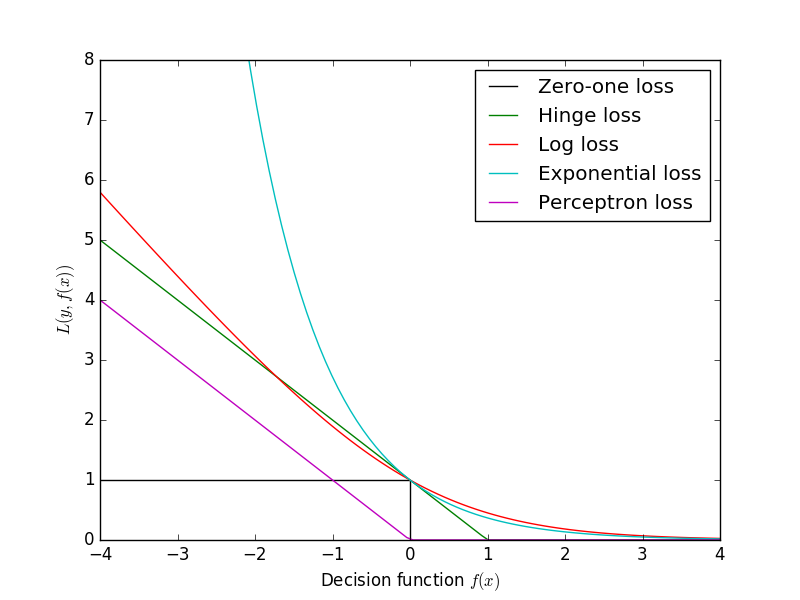
Note: 横轴表示函数间隔ty = t*(wx + b),纵轴表示损失。
| Loss | Function | Minimizer | Example usage |
|---|---|---|---|
| Squared | Expectation (mean) | Regression Expected return on stock | |
| Quantile | Median | Regression What is a typical price for a house? | |
| Logistic | Probability | Classification Probability of click on ad | |
| Hinge | 0-1 approximation | Classification Is the digit a 7? | |
| Poisson | Counts (Log Mean) | Regression Number of call events to call center | |
| Classic | Squared loss without importance weight aware updates | Expectation (mean) | Regression squared loss often performs better than classic. |
from: http://blog.csdn.net/pipisorry/article/details/23538535
ref: [library_design/losses]
[http://www.cs.cmu.edu/~yandongl/loss.html]
[《统计学习方法》 李航]
[机器学习的损失函数 ]
[机器学习-损失函数]*















 4041
4041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









