







Python 实现生产者消费者模式(多线程爬虫)
在多线程开发中,如果生产者生产数据的速度很快,而消费者消费数据的速度很慢,那么生产者就必须等待消费者消费完了数据才能够继续生产数据,因为生产那么多也没有地方放;同理如果消费者的速度大于生产者那么消费者就会经常处理等待状态,所以为了达到生产者和消费者生产数据和消费数据之间的平衡,那么就需要一个缓冲区用来存储生产者生产的数据,所以就引入了 生产者-消费者 模式。
1.多组件的 Pipeline 技术架构
复杂的事情一般都不会一下子做完,而是会分很多中间步骤一步步完成。
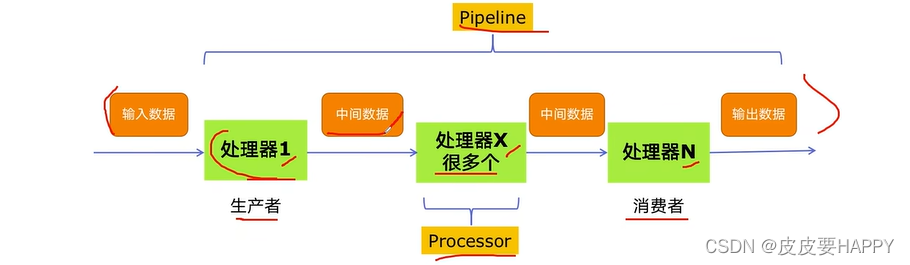
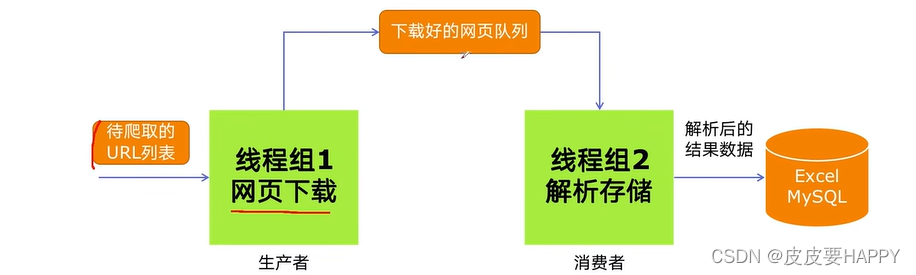
2.生产者消费者爬虫的架构
3.多线程数据通信的 queue.Queue
queue.Queue 可以用于多线程之间的、线程安全的数据通信。简单来说,线程安全指的是多个线程并发同时访问数据不会出现数据冲突。
# 导入
import queue
# 创建
q = queue.Queue()
# 添加元素
q.put(item)
# 获取元素
item = q.get()
# 查看元素的多少
q.qsize()
# 判空
q.empty()
# 判满
q.full()
4.代码编写实现生产者消费者爬虫
基础版:blog_spider.py
import requests
from bs4 import BeautifulSoup
urls = [f'https://www.cnblogs.com/#{page}' for page in range(1, 51)]
# 生产者
def craw(url):
r = requests.get(url)
return r.text
# 消费者
def parse(html):
soup = BeautifulSoup(html, "html.parser")
links = soup.find_all("a", class_="post-item-title")
return [(link["href"], link.get_text()) for link in links]
if __name__ == "__main__":
for result in parse(craw(urls[2])):
print(result)

开始多线程爬虫。
import queue
import blog_spider
import time
import random
import threading
生产者:将每一个连接获取的 html文本 存入 html_queue。
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
while True:
url = url_queue.get()
html = blog_spider.craw(url)
html_queue.put(html)
# 打印相关日志
print(threading.current_thread().name, f"craw {url}",
"url_queue.size=", url_queue.qsize())
time.sleep(random.randint(1, 2))
消费者:解析 html_queue 中的每一个 html文本,获取文章链接和标题,并存入文档中。
def do_parse(html_queue: queue.Queue, fout):
while True:
html = html_queue.get()
results = blog_spider.parse(html)
for result in results:
fout.write(str(result) + "\n")
# 打印当前线程名字
print(threading.current_thread().name, f"results.size", len(results),
"html_queue.size=", html_queue.qsize())
time.sleep(random.randint(1, 2))
生产-消费:设置 3 个生产者进程,2 个消费者进程。
if __name__ == "__main__":
url_queue = queue.Queue()
html_queue = queue.Queue()
for url in blog_spider.urls:
url_queue.put(url)
for idx in range(3):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f"craw{idx}")
t.start()
fout = open("02.data.txt", 'w')
for idx in range(2):
t = threading.Thread(target=do_parse, args=(html_queue, fout), name=f"parse{idx}")
t.start()
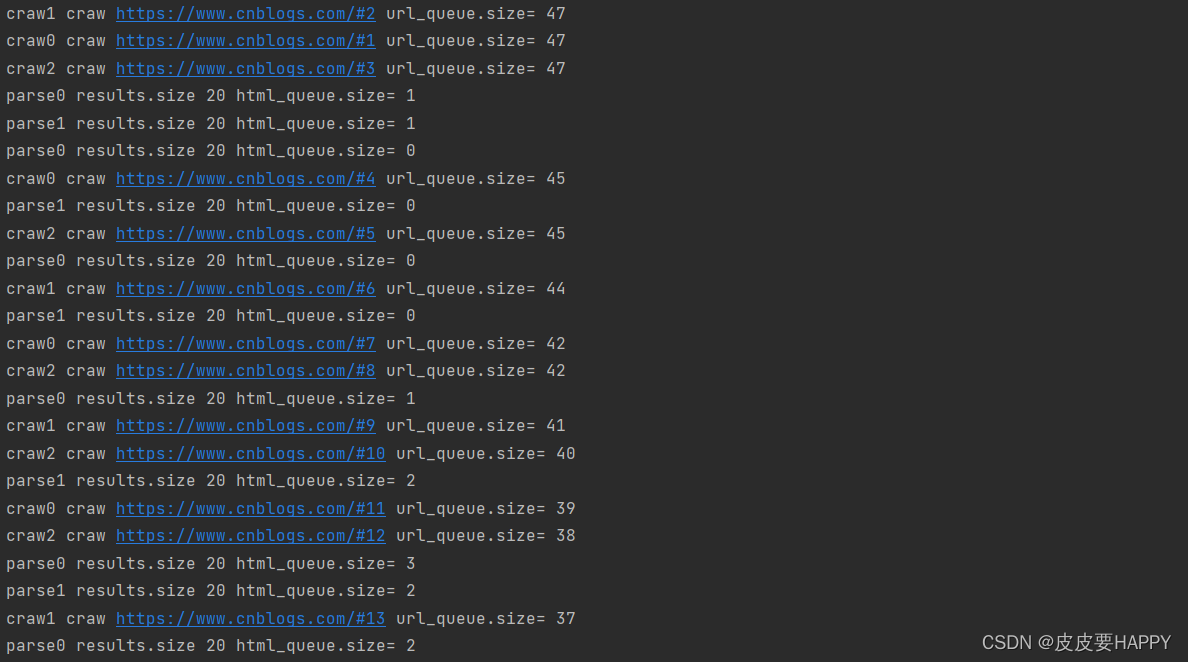
控制台上的打印信息。
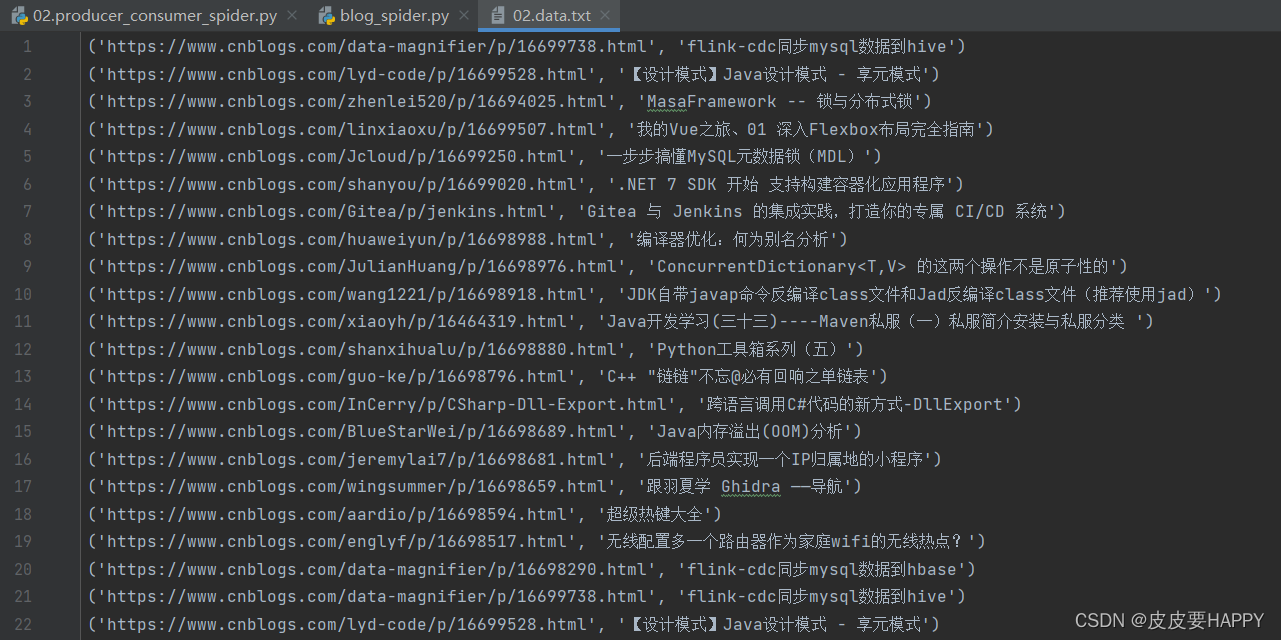
最后看一下写入到文本中的内容。
















 1933
1933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











