







Authors
Florian Schroff Dmitry Kalenichenko James Philbin

Florian Schroff
Abstract
本文提出了FaceNet system,直接从face images 学习到 compact Euclidean 欧几里德 space 从而得到face的相似程度。这样一来 face recognition, verification, clustering 就容易了。该方法使用深度卷积网络直接得到embedding,没有用传统的bottleneck层,训练时用到了online triplet mining method。 效率更高,每脸128bytes。
1 Introduction
verification:is this the same person (thresholding)
recognition: who is this person (K-NN classification)
clustering : find common people among these faces (k-means or agglomerative clustering)
本文直接使用squared L2 距离来判断脸部的similarity。
以往使用bottleneck layer 不直接而且representation size 非常大。本文使用triplet based loss function(参考下面的文献)仅128D。其中有两个matching face thumbnail,一个non-matching face thumbnail
K. Q.Weinberger, J. Blitzer, and L. K. Saul. Distance metric
learning for large margin nearest neighbor classification. In
NIPS. MIT Press, 2006. 2, 3tripletsd 的选择很重要,收到curriculum learning的启发,本文使用在线negative exemplar mining 策略,保证了训练过程中难度的增大
Y. Bengio, J. Louradour, R. Collobert, and J. Weston. Curriculum
learning. In Proc. of ICML, New York, NY, USA,
2009. 2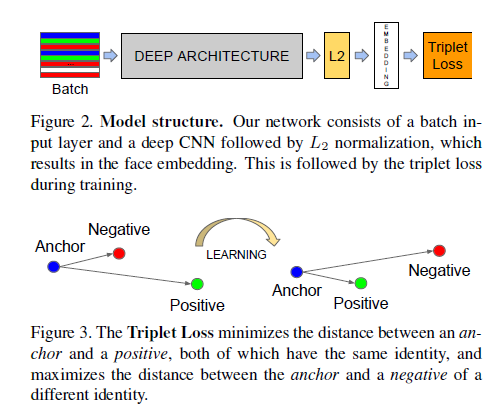
3 Method
3.1 Triplet Loss
通过L2之后得到的embedding是一个hypersphere,其约束方程为:
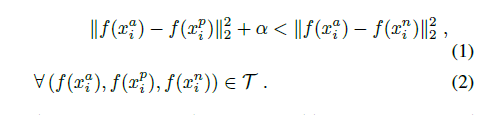
loss为:
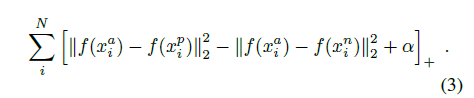
3.2 Triplet selection
如果随便选则
xp,xn
那么很多triplet会很容易就满足上式,对最终的收敛意义不大,我们需要选择与anchor最近的negative和最远的positive,如何选择呢?首先不能在全局选,因为这时数量巨大,而且个别点容易主导训练。以下是文章提出的两种方法:
1. 离线选择,每n步使用最近的网络再一个subset中选择所需要的样本;
2. 在线选择,mini-batch中选择
本文选择第二种,其中positive的选择时使用所有的正例,(这样会再开始的时候更加稳定收敛速度稍快)。hard negative的选择是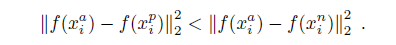
batch size 是1800左右。
3.3 deep convolutional networks
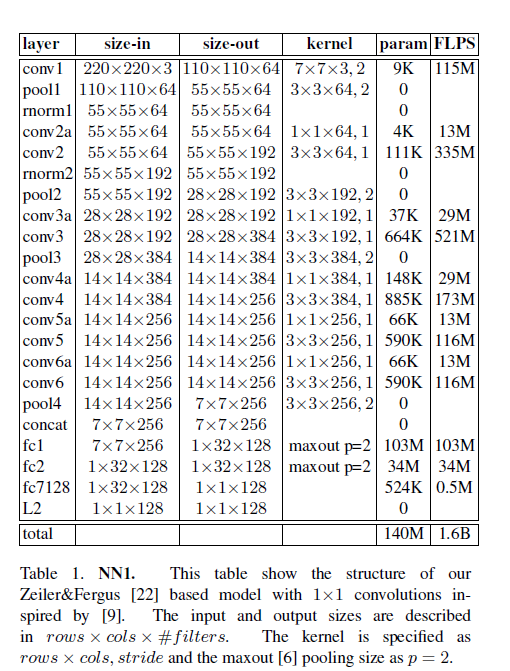
4 Datasets and evaluation
psame=i,j of the same identity
pdiff= different identities
true accepts :TA
false accept: FA
val:TA/psame
FAR:FA/pdiff
5 experiments
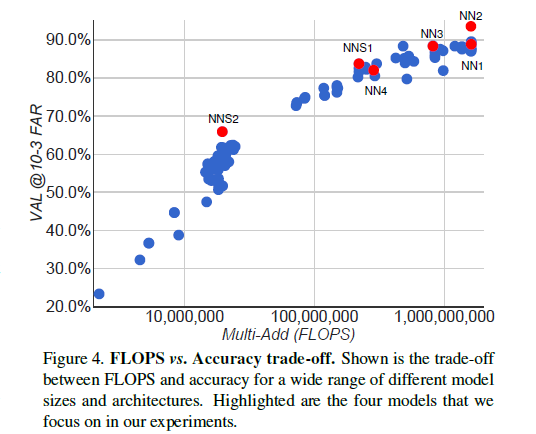
图片质量越好越好,Embedding Dimensionality 越大得到 结果应该越好但是需要更多的训练次数,小的dimensionality有利于嵌入移动设备。随着数据的增多结果会有提高但是增加到一定的程度起作用就会变小。















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









