







这是来自猎户星空的关于人脸识别的文章
作者 Chong Wang ;Xue Zhang ;Xipeng Lan
https://arxiv.org/abs/1709.02940
好久没有写博客了,水一篇。。。
一句话总结
对应triplet的训练,多采用OHNM的方式挖掘困难负样本,然而随着训练数据的增加,easy-triplet更多,困难样本的搜索空间增大,于是本文将训练数据分为若干小部分,每部分中的不同id的训练样本有着较高的相似性(个人感觉ohnm都是trick样的东西,但是大牛们还是可以写的很好)
1. Method
文章先回顾了OHNM和batch OHNM 然后提出subspace learning
1.1 OHNM
其loss 如下
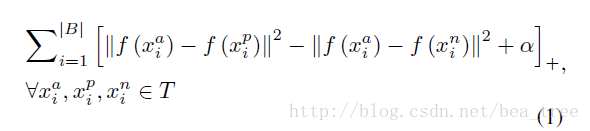
简言之就是只有负样本与anchor的距离大于正样本与anchor的距离一定值才可以算做loss

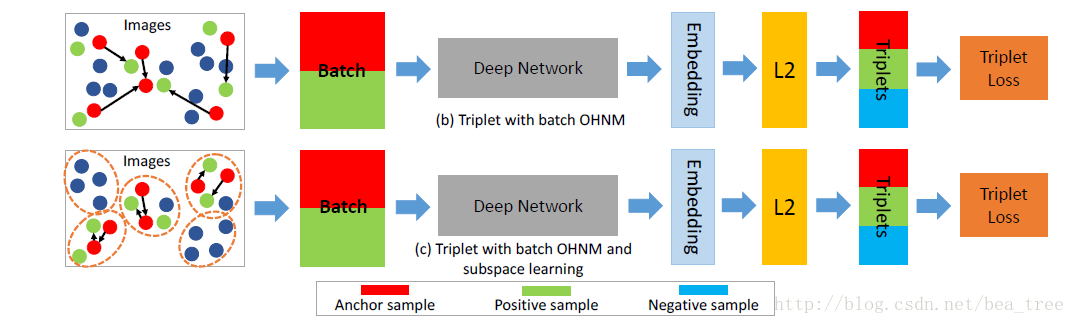
如上图,由于负样本是随机选择(浅蓝)的,很多更加困难的负样本(深蓝)没有被选择
1.2 Batch OHNM
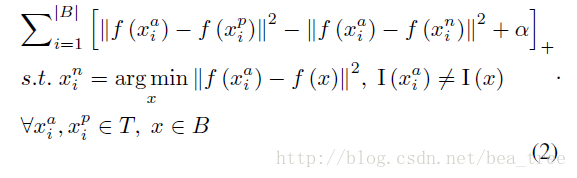
上式中,T代表整个Image Space
训练时,随机选择B个不同的id,然后负样本的选择是靠近anchor的若干个非同id的样本,这样做的 好处是负样本更加困难了,有效的训练样本更多了。
1.3 Subspace Learning
作者认为困难负样本选择有用,但是随着id数量的增多,困难负样本不能被以上两种很好的挖掘,那么就先生成一些困难的小子空间,从子空间中在做batch ohnm
其中他们做子空间的方法是:
1. 首先根据使用部分数据训练分类模型
2. 然后将一个id内的特征求均值,作为该id的特征,然后根据id的特征做k-means生成M个子空间,文中每个子空间大约包含10k个id
在子空间做ohnm的loss 如下:
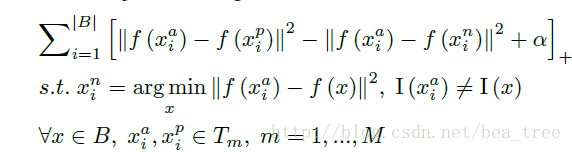
2 其他
2.1 数据清洗
作者认为cnn有一定抗干扰的能力,所以就先过拟合然后再去掉没有能过拟合的样本
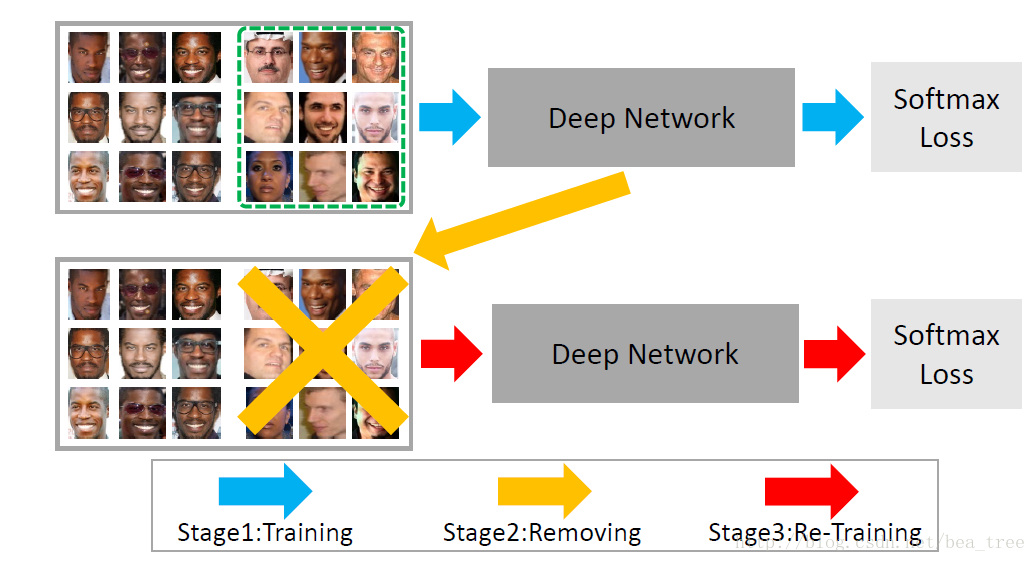
2.2 加快检索速度
分两步,先分id后在id内算距离
3 Experimental evaluation
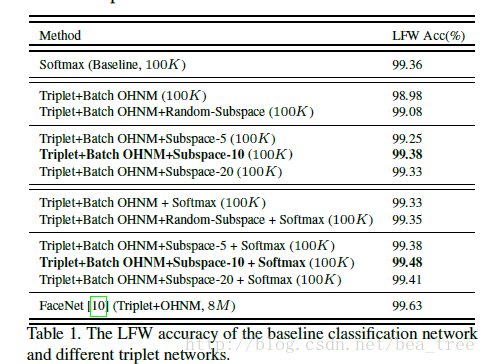
直接加ohem会变差,使用subspace learning的方法会有提高。文章思想比较简单,但是还是有一定的启发性的,和平时自己做的试验也有思想性。

















 2468
2468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









