







一、目标
microsoft的swin-transformer本身是进行单分类任务的,我们希望通过swin-transformer实现多分类的功能。
比如我们有分类任务:
(1)车辆类型type的分类,分car(轿车)和jeep(吉普车)两类
(2)车辆朝向direction的分类,分forward(朝前)和backward(朝后)两类
图片大致如下:


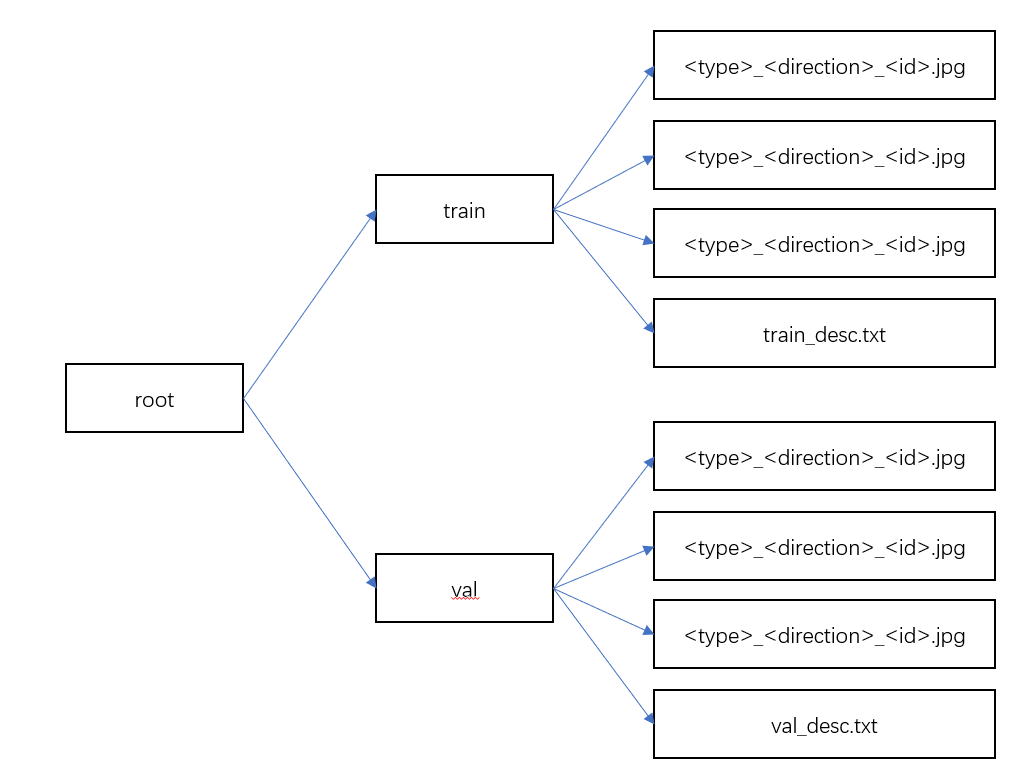
训练/验证数据目录结构如下:
二、改动内容
1、创建contants.py文件
该文件记录算法会用到的几个全局变量
# 图像转换时用到的均值和方差
IMG_DEFAULT_MEAN = (0.485, 0.456, 0.406)
IMG_DEFAULT_STD = (0.229, 0.224, 0.225)
# 目标名称到id的映射
target_type_dict = {'car': 0, 'jeep': 1}
target_direction_dict = {'forward': 0, 'backward': 1}
# 目标每类中的种数
target_dim_dict = {'type': 2, 'direction': 2}2、创建swin_dataloader.py文件
该文件用于训练时批量加载数据
import os
from torch.utils.data import DataLoader, Dataset, Sampler
from torchvision import datasets, transforms
from timm.data.transforms import str_to_pil_interp
from PIL import Image
import constants
class TrainDataset(Dataset):
def __init__(self, config):
train_data_path = os.path.join(config.DATA.DATA_PATH, 'train')
train_data_desc = os.path.join(train_data_path, 'train_desc.txt')
self.img_paths = []
self.types = []
self.directions = []
with open(train_data_desc, 'r') as f:
for line in f:
arr = line.split(",")
img_path, type, direction = arr[0], arr[1], arr[2].replace('\n', '')
self.img_paths.append(os.path.join(train_data_path, img_path))
self.types.append(int(constants.target_type_dict.get(type)))
self.directions.append(int(constants.target_direction_dict.get(direction)))
# transform
t = []
size = int((256 / 224) * config.DATA.IMG_SIZE)
t.append(transforms.Resize(size, interpolation=str_to_pil_interp(config.DATA.INTERPOLATION)))
t.append(transforms.CenterCrop(config.DATA.IMG_SIZE))
t.append(transforms.ToTensor())
t.append(transforms.Normalize(constants.IMG_DEFAULT_MEAN, constants.IMG_DEFAULT_STD))
self.transform = transforms.Compose(t)
def __len__(self):
return len(self.img_paths)
def __getitem__(self, index):
img_path = self.img_paths[index]
type = self.types[index]
direction = self.directions[index]
img = Image.open(img_path).convert('RGB')
img_tensor = self.transform(img)
return img_tensor, type, direction
class TestDataset(Dataset):
def __init__(self, config):
test_data_path = os.path.join(config.DATA.DATA_PATH, 'val')
test_data_desc = os.path.join(test_data_path, 'val_desc.txt')
self.img_paths = []
self.types = []
self.directions = []
with open(test_data_desc, 'r') as f:
for line in f:
arr = line.split(",")
img_path, type, direction = arr[0], arr[1], arr[2].replace('\n', '')
self.img_paths.append(os.path.join(test_data_path, img_path))
self.types.append(int(constants.target_type_dict.get(type)))
self.directions.append(int(constants.target_direction_dict.get(direction)))
# transform
t = []
size = int((256 / 224) * config.DATA.IMG_SIZE)
t.append(transforms.Resize(size, interpolation=str_to_pil_interp(config.DATA.INTERPOLATION)))
t.append(transforms.CenterCrop(config.DATA.IMG_SIZE))
t.append(transforms.ToTensor())
t.append(transforms.Normalize(constants.IMG_DEFAULT_MEAN, constants.IMG_DEFAULT_STD))
self.transform = transforms.Compose(t)
def __len__(self):
return len(self.img_paths)
def __getitem__(self, index):
img_path = self.img_paths[index]
type = self.types[index]
direction = self.directions[index]
img = Image.open(img_path).convert('RGB')
img_tensor = self.transform(img)
return img_tensor, type, direction
3、修改swin_transformer文件
(1)在SwinTransformer的__init__()初始化函数中做如下修改:
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
# self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
for idx, (k, v) in enumerate(constants.target_dim_dict.items()):
fc = nn.Linear(self.num_features, v)
setattr(self, f'fc_{k}', fc)(2)在SwinTransformer的forward()函数中做如下修改:
def forward(self, x):
x = self.forward_features(x)
# x = self.head(x)
# return x
outputs = {}
for k,v in constants.target_dim_dict.items():
out = getattr(self, f'fc_{k}')(x)
outputs[k] = out
return outputs4、修改main.py文件
对于模型输出后结果的解析做相应的调整,调整比较生硬,如果dataloader中把输出的type和direction放到一个对象里面,可能会稍微优雅一点。
def train_one_epoch(config, model, criterion, data_loader, optimizer, epoch, mixup_fn, lr_scheduler, loss_scaler):
model.train()
optimizer.zero_grad()
num_steps = len(data_loader)
batch_time = AverageMeter()
loss_meter = AverageMeter()
norm_meter = AverageMeter()
scaler_meter = AverageMeter()
start = time.time()
end = time.time()
for idx, (samples, type, direction) in enumerate(data_loader):
samples = samples.cuda(non_blocking=True)
type = type.cuda(non_blocking=True)
direction = direction.cuda(non_blocking=True)
# todo mix this bug
# if mixup_fn is not None:
# samples, person, country = mixup_fn(samples, person, country)
criterion = torch.nn.CrossEntropyLoss()
# with torch.cuda.amp.autocast(enabled=config.AMP_ENABLE):
outputs = model(samples)
loss = 0
loss += criterion(outputs['type'], type)
loss += criterion(outputs['direction'], direction)
loss = loss / config.TRAIN.ACCUMULATION_STEPS
# this attribute is added by timm on one optimizer (adahessian)
is_second_order = hasattr(optimizer, 'is_second_order') and optimizer.is_second_order
grad_norm = loss_scaler(loss, optimizer, clip_grad=config.TRAIN.CLIP_GRAD,
parameters=model.parameters(), create_graph=is_second_order,
update_grad=(idx + 1) % config.TRAIN.ACCUMULATION_STEPS == 0)
if (idx + 1) % config.TRAIN.ACCUMULATION_STEPS == 0:
optimizer.zero_grad()
lr_scheduler.step_update((epoch * num_steps + idx) // config.TRAIN.ACCUMULATION_STEPS)
loss_scale_value = loss_scaler.state_dict()["scale"]
torch.cuda.synchronize()
loss_meter.update(loss.item(), type.size(0))
if grad_norm is not None: # loss_scaler return None if not update
norm_meter.update(grad_norm)
scaler_meter.update(loss_scale_value)
batch_time.update(time.time() - end)
end = time.time()
if idx % config.PRINT_FREQ == 0:
lr = optimizer.param_groups[0]['lr']
wd = optimizer.param_groups[0]['weight_decay']
memory_used = torch.cuda.max_memory_allocated() / (1024.0 * 1024.0)
etas = batch_time.avg * (num_steps - idx)
logger.info(
f'Train: [{epoch}/{config.TRAIN.EPOCHS}][{idx}/{num_steps}]\t'
f'eta {datetime.timedelta(seconds=int(etas))} lr {lr:.6f}\t wd {wd:.4f}\t'
f'time {batch_time.val:.4f} ({batch_time.avg:.4f})\t'
f'loss {loss_meter.val:.4f} ({loss_meter.avg:.4f})\t'
f'grad_norm {norm_meter.val:.4f} ({norm_meter.avg:.4f})\t'
f'loss_scale {scaler_meter.val:.4f} ({scaler_meter.avg:.4f})\t'
f'mem {memory_used:.0f}MB')
epoch_time = time.time() - start
logger.info(f"EPOCH {epoch} training takes {datetime.timedelta(seconds=int(epoch_time))}")
@torch.no_grad()
def validate(config, data_loader, model):
criterion = torch.nn.CrossEntropyLoss()
model.eval()
batch_time = AverageMeter()
loss_meter = AverageMeter()
type_acc1_meter = AverageMeter()
direction_acc1_meter = AverageMeter()
end = time.time()
for idx, (images, type, direction) in enumerate(data_loader):
images = images.cuda(non_blocking=True)
type = type.cuda(non_blocking=True)
direction = direction.cuda(non_blocking=True)
# compute output
# with torch.cuda.amp.autocast(enabled=config.AMP_ENABLE):
# output = model(images)
outputs = model(images)
loss = 0
loss += criterion(outputs['type'], type)
loss += criterion(outputs['direction'], direction)
loss = loss / config.TRAIN.ACCUMULATION_STEPS
# measure accuracy and record loss
type_acc1 = accuracy(outputs['type'], type)
direction_acc1 = accuracy(outputs['direction'], direction)
type_acc1 = torch.tensor(type_acc1)
direction_acc1 = torch.tensor(direction_acc1)
loss = torch.tensor(loss)
loss_meter.update(loss.item(), type.size(0))
type_acc1_meter.update(type_acc1.item(), type.size(0))
direction_acc1_meter.update(direction_acc1.item(), type.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if idx % config.PRINT_FREQ == 0:
memory_used = torch.cuda.max_memory_allocated() / (1024.0 * 1024.0)
logger.info(
f'Test: [{idx}/{len(data_loader)}]\t'
f'Time {batch_time.val:.3f}\t'
f'Loss {loss_meter.val:.4f}\t'
f'type_Acc@1 {type_acc1_meter.val:.3f}\t'
f'direction_Acc@1 {direction_acc1_meter.val:.3f}\t'
f'Mem {memory_used:.0f}MB')
logger.info(f' * type_Acc@1 {type_acc1_meter.avg:.3f} * direction_Acc@1 {direction_acc1_meter.avg:.3f}')
return type_acc1_meter.avg, direction_acc1_meter.avg, loss_meter.avg5、修改build.py
# --------------------------------------------------------
# Swin Transformer
# Copyright (c) 2021 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu
# --------------------------------------------------------
import os
import torch
import numpy as np
import torch.distributed as dist
from torchvision import datasets, transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.data import Mixup
from timm.data import create_transform
from .cached_image_folder import CachedImageFolder
from .imagenet22k_dataset import IN22KDATASET
from .samplers import SubsetRandomSampler
from swin_dataloader import TrainDataset, TestDataset
try:
from torchvision.transforms import InterpolationMode
def _pil_interp(method):
if method == 'bicubic':
return InterpolationMode.BICUBIC
elif method == 'lanczos':
return InterpolationMode.LANCZOS
elif method == 'hamming':
return InterpolationMode.HAMMING
else:
# default bilinear, do we want to allow nearest?
return InterpolationMode.BILINEAR
import timm.data.transforms as timm_transforms
timm_transforms.str_to_pil_interp = _pil_interp
except:
from timm.data.transforms import str_to_pil_interp
def build_loader(config):
config.defrost()
# dataset_train, config.MODEL.NUM_CLASSES = build_dataset(is_train=True, config=config)
dataset_train = TrainDataset(config)
config.freeze()
print(f"local rank {config.LOCAL_RANK} / global rank {dist.get_rank()} successfully build train dataset")
# dataset_val, _ = build_dataset(is_train=False, config=config)
dataset_val = TestDataset(config)
print(f"local rank {config.LOCAL_RANK} / global rank {dist.get_rank()} successfully build val dataset")
num_tasks = dist.get_world_size()
global_rank = dist.get_rank()
if config.DATA.ZIP_MODE and config.DATA.CACHE_MODE == 'part':
indices = np.arange(dist.get_rank(), len(dataset_train), dist.get_world_size())
sampler_train = SubsetRandomSampler(indices)
else:
sampler_train = torch.utils.data.DistributedSampler(
dataset_train, num_replicas=num_tasks, rank=global_rank, shuffle=True
)
if config.TEST.SEQUENTIAL:
sampler_val = torch.utils.data.SequentialSampler(dataset_val)
else:
sampler_val = torch.utils.data.distributed.DistributedSampler(
dataset_val, shuffle=config.TEST.SHUFFLE
)
data_loader_train = torch.utils.data.DataLoader(
dataset_train, sampler=sampler_train,
batch_size=config.DATA.BATCH_SIZE,
num_workers=config.DATA.NUM_WORKERS,
pin_memory=config.DATA.PIN_MEMORY,
drop_last=True,
)
data_loader_val = torch.utils.data.DataLoader(
dataset_val, sampler=sampler_val,
batch_size=config.DATA.BATCH_SIZE,
shuffle=False,
num_workers=config.DATA.NUM_WORKERS,
pin_memory=config.DATA.PIN_MEMORY,
drop_last=False
)
# setup mixup / cutmix
mixup_fn = None
mixup_active = config.AUG.MIXUP > 0 or config.AUG.CUTMIX > 0. or config.AUG.CUTMIX_MINMAX is not None
if mixup_active:
mixup_fn = Mixup(
mixup_alpha=config.AUG.MIXUP, cutmix_alpha=config.AUG.CUTMIX, cutmix_minmax=config.AUG.CUTMIX_MINMAX,
prob=config.AUG.MIXUP_PROB, switch_prob=config.AUG.MIXUP_SWITCH_PROB, mode=config.AUG.MIXUP_MODE,
label_smoothing=config.MODEL.LABEL_SMOOTHING, num_classes=config.MODEL.NUM_CLASSES)
return dataset_train, dataset_val, data_loader_train, data_loader_val, mixup_fn
def build_dataset(is_train, config):
transform = build_transform(is_train, config)
if config.DATA.DATASET == 'imagenet':
prefix = 'train' if is_train else 'val'
if config.DATA.ZIP_MODE:
ann_file = prefix + "_map.txt"
prefix = prefix + ".zip@/"
dataset = CachedImageFolder(config.DATA.DATA_PATH, ann_file, prefix, transform,
cache_mode=config.DATA.CACHE_MODE if is_train else 'part')
else:
root = os.path.join(config.DATA.DATA_PATH, prefix)
dataset = datasets.ImageFolder(root, transform=transform)
nb_classes = config.MODEL.NUM_CLASSES
elif config.DATA.DATASET == 'imagenet22K':
prefix = 'ILSVRC2011fall_whole'
if is_train:
ann_file = prefix + "_map_train.txt"
else:
ann_file = prefix + "_map_val.txt"
dataset = IN22KDATASET(config.DATA.DATA_PATH, ann_file, transform)
nb_classes = 21841
else:
raise NotImplementedError("We only support ImageNet Now.")
return dataset, nb_classes
def build_transform(is_train, config):
resize_im = config.DATA.IMG_SIZE > 32
if is_train:
# this should always dispatch to transforms_imagenet_train
transform = create_transform(
input_size=config.DATA.IMG_SIZE,
is_training=True,
color_jitter=config.AUG.COLOR_JITTER if config.AUG.COLOR_JITTER > 0 else None,
auto_augment=config.AUG.AUTO_AUGMENT if config.AUG.AUTO_AUGMENT != 'none' else None,
re_prob=config.AUG.REPROB,
re_mode=config.AUG.REMODE,
re_count=config.AUG.RECOUNT,
interpolation=config.DATA.INTERPOLATION,
)
if not resize_im:
# replace RandomResizedCropAndInterpolation with
# RandomCrop
transform.transforms[0] = transforms.RandomCrop(config.DATA.IMG_SIZE, padding=4)
return transform
t = []
if resize_im:
if config.TEST.CROP:
size = int((256 / 224) * config.DATA.IMG_SIZE)
t.append(
transforms.Resize(size, interpolation=str_to_pil_interp(config.DATA.INTERPOLATION)),
# to maintain same ratio w.r.t. 224 images
)
t.append(transforms.CenterCrop(config.DATA.IMG_SIZE))
else:
t.append(
transforms.Resize((config.DATA.IMG_SIZE, config.DATA.IMG_SIZE),
interpolation=str_to_pil_interp(config.DATA.INTERPOLATION))
)
t.append(transforms.ToTensor())
t.append(transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD))
return transforms.Compose(t)
三、效果
经过117轮迭代后,type + direction的准确率可以达到167.5%,总分为100+100=200%。其中type的准确率为77.5%,direction的准确率为90%。
train的loss为0.0023,基本上训练集拟合的较为完善了。















 8964
8964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









