










文档切片
文档切片的五个层次(详细信息)
- 直接按字符数或者句子切;
- 按标点符号,由粗到细迭代切分;
- 基于文档的切分:例如遵循 Markdown 格式、Python 代码格式进行切分;
- 语义切分:合并高语义相似度的切分;
- Agent 辅助的切分:使用 Agent 来判断两个 chunk 是否需要进行合并的切分。
Basic RAG 与 Advanced RAG (详细信息)
Basic RAG 的一般流程
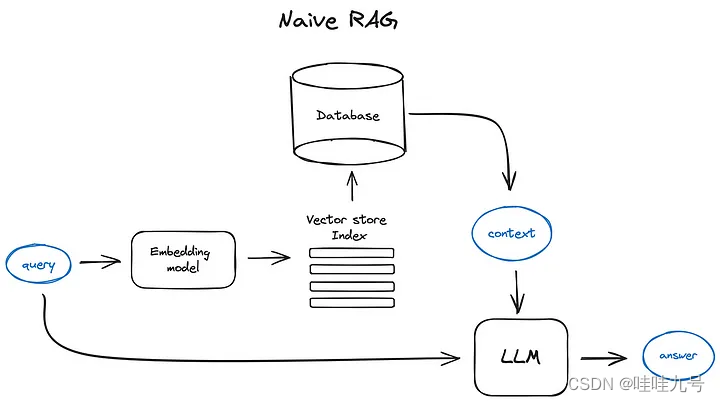
- Vanilla RAG case in brief looks the following way: you split your texts into chunks, then you embed these chunks into vectors with some Transformer Encoder model, you put all those vectors into an index and finally you create a prompt for an LLM that tells the model to answers user’s query given the context we found on the search step.
- In the runtime we vectorise user’s query with the same Encoder model and then execute search of this query vector against the index, find the top-k results, retrieve the corresponding text chunks from our database and feed them into the LLM prompt as context.
- prompt 设计:
def question_answering(context, query): prompt = f""" Give the answer to the user query delimited by triple backticks ```{query}```\ using the information given in context delimited by triple backticks ```{context}```.\ If there is no relevant information in the provided context, try to answer yourself, but tell user that you did not have any relevant context to base your answer on. Be concise and output the answer of size less than 80 tokens. """ response = get_completion(instruction, prompt, model="gpt-3.5-turbo") answer = response.choices[0].message["content"] return answer
Advanced RAG 的一般流程
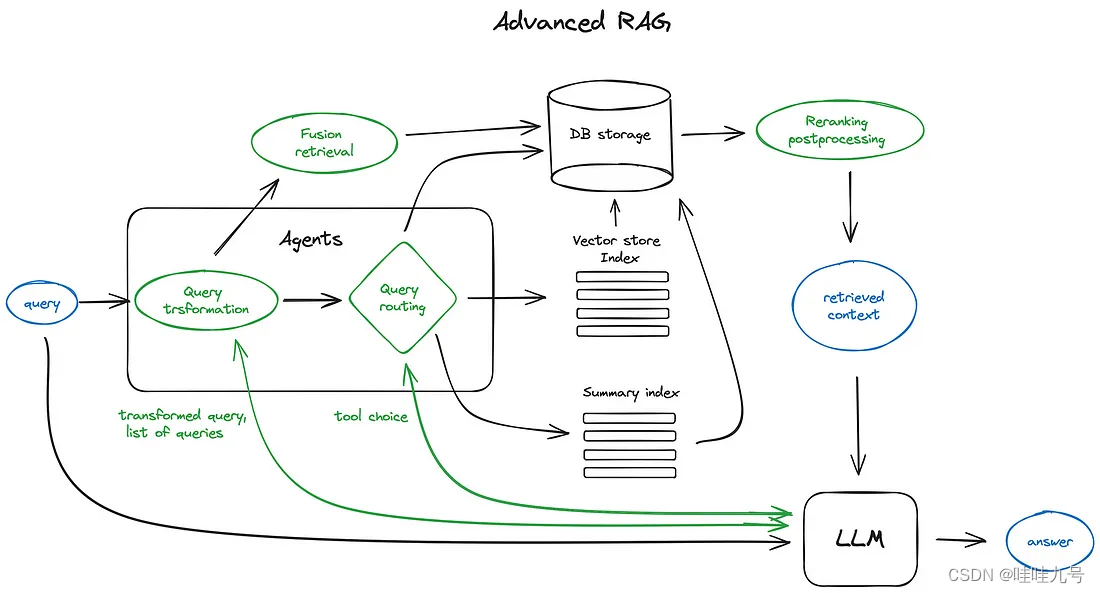
切分 chunk 以及向量化
-
Chunking and Vectorisation
- 切分见上面切分的 5 个层次;
- 向量化:Milvus、faiss 等;
-
检索(Search)
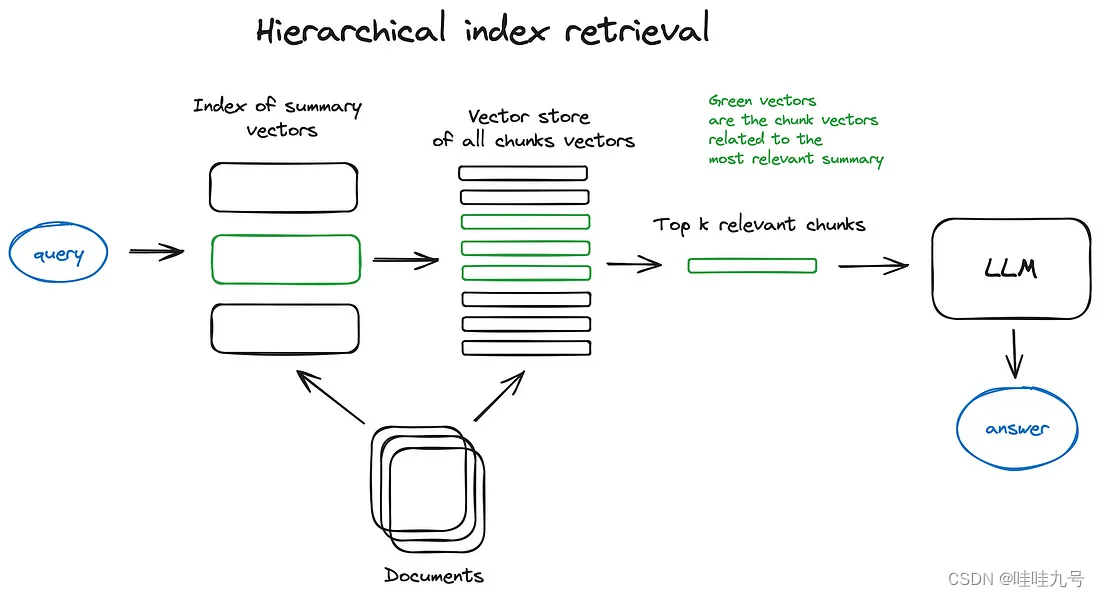
- 基础检索
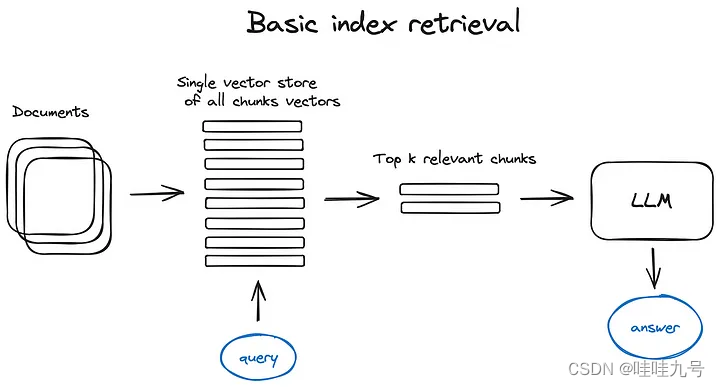
- 分层索引
先在 summary 中检索,然后根据 summary 的检索结果进行进一步检索。
- 问题假设
要求 LLM 对每个 chunk 都生成一个问题,然后对生成的问题也提取 embedding,检索的时候对问题进行检索。此外还有类似 HyDE 的方法:先要求 LLM 生成一个答案,然后将生成的答案和问题一去进行检索。 - 上下文窗口扩充
上下文窗口扩充的基本思想是:在检索时使用较小的 chunk 以提高检索准确率,但在回答问题时将检索的上下文也作为输入。这有两种方法:窗口扩充检索和父文档检索。

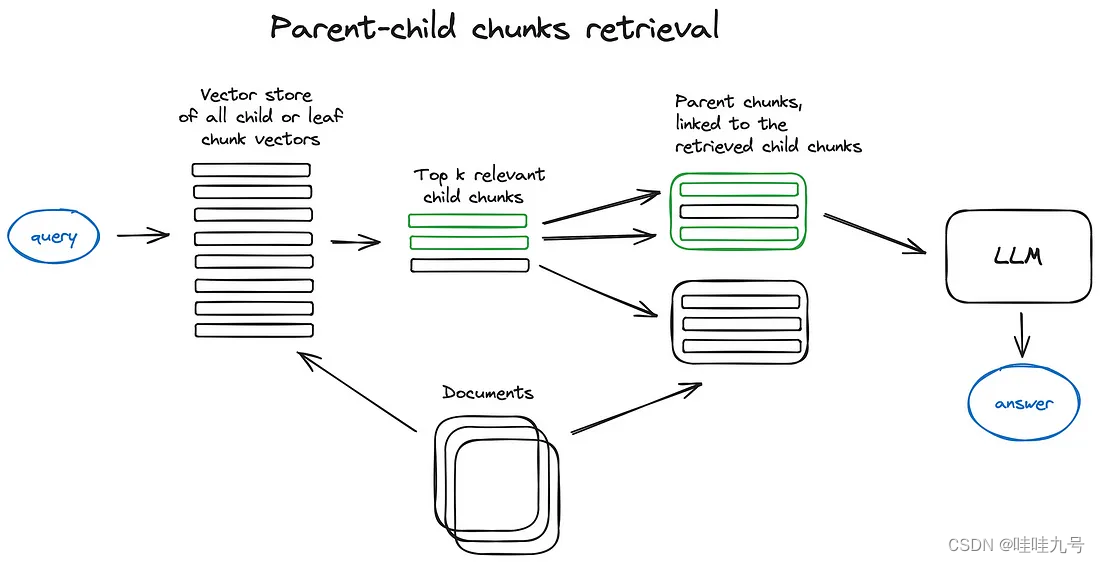
- 混合搜索
同时进行关键词搜索(ES)以及向量相似度检索(Milvus),并合并这两个检索结果。
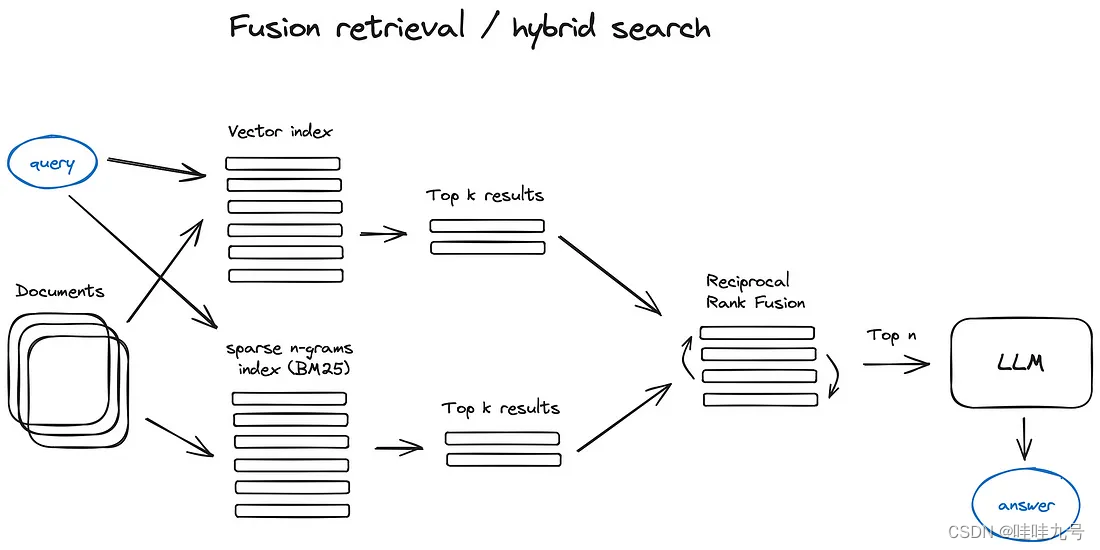
- 基础检索
-
结果重排和过滤
这是最后一步,随后检索到的上下文将被喂入大模型用来获取答案。
- 基于相似度得分、关键词、元数据对结果进行过滤;
- 用另一个模型(例如 LLM)对结果进行重新排序。
-
问题转换
问题转换使用 LLM 对用户问题进行修整,用来提升检索质量。这些方法包括:
- 问题拆解:将复杂问题拆解为多个子问题;
- step-back prompting:要求 LLM 生成一个更通用的问题(用来检索到更高层次的上下文),和原始问题一起进行搜索;
- 问题重写:使用 LLM 对问题进行重新表述。
- Reference citations
-
聊天引擎
考虑历史上下文的聊天引擎:
- ContextChatEngine
- CondensePlusContextMode
-
问题路由
在给定问题后,由大模型判断接下来需要进行什么步骤:例如进行概述、执行搜索,或者继续执行不同的路由。这需要大模型在几个选项中进行选择。
-
RAG 中的 Agents
使用 Agents 进行工具调用。
-
结果合成输出
所有 RAG 系统中的最后一步:根据检索到的上下文进行结果输出。
- 直接拼接问题和所有上下文作为 LLM 的输入;
- 先对检索上下文进行概述;
- 根据不同的上下文生成多个答案,然后对答案进行合并;
- 等等
-
Encoder and LLM fine-tuning
Encoder 微调、Ranker 微调、LLM 微调都可以对 RAG 系统性能有所提升。
-
RAG 性能评估
RAG 性能评估包含多个方面,例如:答案相关性、答案忠实度、检索的上下文相关性等。
Ragas 使用答案忠实度和相关性作为生成的答案的真实度评价,并使用传统的上下文精度和召回作为检索部分的评估标准。
此外评估框架 (Truelens)[https://github.com/truera/trulens/tree/main] 推荐 RAG triad:检索结果和问题的相关性、回答问题的真实性(LLM 是否遵循检索结果进行回答)、以及问题和答案的相关性。
所有的评价中,最重要的就是
检索的上下文相关性。


















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











