







序言
抽查是一种发现哪种算法在机器学习问题中表现良好的方法。我们无法提前知道哪种算法最适合。我们必须尝试多种方法,并关注那些表现出最大潜力的方法。通过本文后,我们将知道:
1. 如何抽查机器学习算法的回归问题。
2. 如何抽查四个线性回归算算法。
3. 如何抽查三个非线性回归算法。
算法概览
我们将查看七种可以在数据集上进行抽样检测的回归算法。从四个线性机器学习算法开始:
1. 线性回归(Linear Regression)
2. 岭回归(Ridge Regression)
3. LASSO线性回归(LASSO Linear Regression)
4. 弹性网回归(Elastic Net Regression)
然后,将查看三个非线性机器学习算法:
1. k近邻(k-Nearest Neighbors, KNN)
2. 分类与回归树(Classification and Regression Trees, CART)
3. 支持向量机(Support Vector Machines, SVM)
线性机器学习算法
将展示如何使用四种线性机器学习算法:线性回归、岭回归、LASSO线性回归和弹性网回归。
-
线性回归(Linear Regression):线性回归假设输入变量具有高斯分布。还假设输入变量与输出变量相关,并且它们之间不存在高度相关性(这种问题称为多重共线性)。我们可以使用LinearRegression类来构建线性回归模型。
-
岭回归(Ridge Regression):岭回归是线性回归的一种扩展,它通过修改损失函数来最小化模型的复杂度,这种复杂度是通过系数值的总平方和(也称为L2范数)来衡量的。我们可以使用Ridge类来构建岭回归模型。
-
LASSO线性回归(LASSO Linear Regression):最小绝对收缩和选择算子(简称LASSO)是线性回归的一种改进,类似于岭回归,它通过修改损失函数来最小化模型的复杂度,这种复杂度是通过系数值的绝对值之和(也称为L1范数)来衡量的。我们可以使用Lasso类来构建LASSO模型。
-
弹性网回归(Elastic Net Regression):ElasticNet是一种正则化回归方法,它结合了岭回归(Ridge Regression)和LASSO线性回归(LASSO Linear Regression)的特性。ElasticNet通过同时使用L2范数(系数值的平方和)和L1范数(系数值的绝对和),来最小化回归模型的复杂度(系数的大小和数量)。我们可以使用ElasticNet类来构建ElasticNet模型。
非线性机器学习算法
我们将展示如何使用三种非线性机器学习算法。
-
k-最近邻算法(k-Nearest Neighbors,简称KNN):它是一种基于实例的学习方法。对于新输入的数据实例,KNN算法在训练数据集中寻找与其最相似的k个实例。从这k个邻居中,计算输出变量的平均值或中位数作为预测结果。需要注意的是,用于计算距离的度量标准(metric argument)。默认使用Minkowski距离,这是一种欧几里得距离(当所有输入具有相同的规模时使用)和曼哈顿距离(当输入变量的规模不同时使用)的一般化。我们可以使用KNeighborsRegressor类来构建用于回归的KNN模型。
-
分类与回归树(Classification and Regression Trees,简称CART或决策树):它是一种决策树算法,它用于构造分类树(用于分类问题)和回归树(用于回归问题)。CART通过在训练数据上选择最佳的分割点来最小化一个成本度量,以构造树的结构。对于回归树,默认的成本度量是均方误差(Mean Squared Error),这在决策树的criterion参数中指定。我们可以使用DecisionTreeRegressor类来创建一个用于回归问题的CART模型。这个类提供了多种参数,允许调整树的增长策略,例如最大深度(max_depth)、最小分割样本数(min_samples_split)等。通过这些参数,进而可以控制模型的复杂度和过拟合的风险。通过使用训练数据来选择最佳的分割点,CART算法构建出一棵用于回归的树。每个节点代表数据的一个子集,而每个叶节点则给出了一个预测值,这个预测值可以是子集中所有数据的平均值或中位数。
-
支持向量机(Support Vector Machines,简称SVM):它最初是为二分类问题设计的。这种技术已经被扩展到预测实值问题的领域,称为支持向量回归(Support Vector Regression,简称SVR)。与分类问题类似,SVR也是基于LIBSVM库构建的。我们可以使用SVR类来创建一个用于回归问题的SVM模型。
-
在SVR中,目标是找到一个超平面,使得回归函数的误差尽可能小,同时确保不存在过拟合。SVR使用不同的核函数来实现这种映射,允许非线性回归。在scikit-learn库中,可以选择不同的核函数,如线性核、多项式核、径向基函数(RBF)核等。创建SVM回归模型时,还需要指定模型的参数,例如正则化参数C、核函数类型以及用于交叉验证的参数等。通过调整这些参数,可以优化模型的性能,以更好地适应回归问题。
案例源码分享
# coding: utf-8
"""
该脚本演示了使用七种不同的分类算法在数据集上进行分类的效果。这些算法包括四种线性方法:
(1)线性回归(Linear Regression)
(2)岭回归(Ridge Regression)
(3)LASSO线性回归(LASSO Linear Regression)
(4)弹性网回归(Elastic Net Regression)
以及三种非线性方法:
(1)K-近邻(k-Nearest Neighbors, KNN)
(2)分类和回归树(Classification and Regression Trees, CART)
(3)支持向量机(Support Vector Machines, SVM)
"""
# 导入必要的库和模块
from pathlib import Path # 用于处理文件路径的工具
import pandas as pd # 数据处理和分析库
from sklearn.preprocessing import StandardScaler # 数据标准化预处理工具
from sklearn.model_selection import KFold, cross_val_score # K折交叉验证和交叉验证得分工具
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet # 不同的线性回归模型
from sklearn.neighbors import KNeighborsRegressor # K近邻回归模型
from sklearn.tree import DecisionTreeRegressor # 决策树回归模型
from sklearn.svm import SVR # 支持向量回归模型
"""
该脚本读取波士顿房价数据集,进行预处理包括删除缺失值和特征标准化,并输出处理后的数据集概览。
"""
# 读取波士顿房价数据集
filename = Path(__file__).parent / 'data/boston_house_prices.csv'
column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
data = pd.read_csv(filename, header=1, names=column_names)
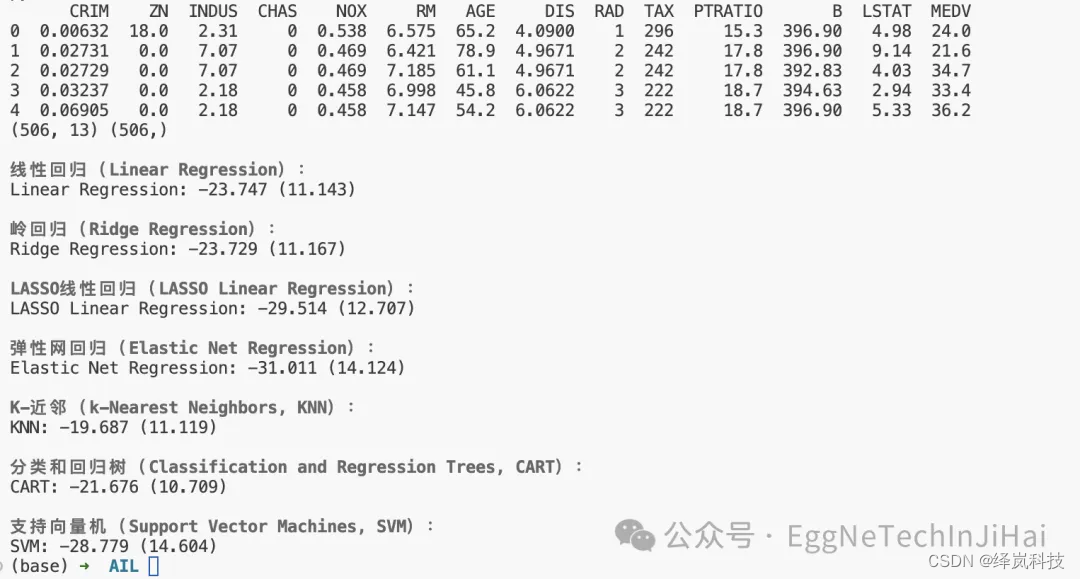
print(data.head())
# 删除含有缺失值的行
data.dropna(inplace=True)
# 对输入的特征数据进行标准化
scaler = StandardScaler()
X = scaler.fit_transform(data.iloc[:, :-1]) # 特征数据标准化
# 提取目标变量
Y = data.iloc[:, -1] # 提取房价作为目标变量
print(X.shape, Y.shape)
"""
###### 机器学习模型性能评估 ######
该代码块用于评估不同机器学习模型在给定数据集上的表现。通过使用交叉验证(KFold)和不同的评分指标(负均方误差),对以下模型进行了比较:
1. 线性回归(Linear Regression)
2. 岭回归(Ridge Regression)
3. LASSO线性回归(LASSO Linear Regression)
4. 弹性网回归(Elastic Net Regression)
5. K-近邻(k-Nearest Neighbors, KNN)
6. 分类和回归树(Classification and Regression Trees, CART)
7. 支持向量机(Support Vector Machines, SVM)
对于每个模型,代码执行以下步骤:
1. 初始化KFold交叉验证器;
2. 实例化选定的模型;
3. 指定评分指标为负均方误差;
4. 计算并记录模型在交叉验证中的表现;
5. 打印模型的平均得分和标准差。
该代码有助于选择在给定数据集上表现最佳的模型,并提供了一个简单的比较框架。
"""
###### 线性回归(Linear Regression)######
# 此部分为线性回归模型的交叉验证评分代码段
print("\n\033[1;30m线性回归(Linear Regression):\033[0m") # 打印标题
# 划分数据集为10个折叠的交叉验证
kfold = KFold(n_splits=10, random_state=7, shuffle=True)
# 创建线性回归模型
model = LinearRegression()
# 定义评分指标为负均方误差
scoring = 'neg_mean_squared_error'
# 计算模型在交叉验证集上的评分
results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
# 打印线性回归模型的平均评分和标准差
print("Linear Regression: %.3f (%.3f)" % (results.mean(), results.std()))
###### 岭回归(Ridge Regression)######
# 这一部分代码实现了岭回归的交叉验证过程,以评估模型性能。
print("\n\033[1;30m岭回归(Ridge Regression):\033[0m") # 打印岭回归的标题
# 划分数据集为训练集和测试集
kfold = KFold(n_splits=10, random_state=7, shuffle=True) # 使用10折交叉验证,设置随机种子为7,并随机打乱数据
model = Ridge() # 实例化岭回归模型
scoring = 'neg_mean_squared_error' # 定义评估模型性能的指标为负均方误差
# 在不同的数据子集上训练和评估模型
results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring) # 计算模型的交叉验证分数
# 打印岭回归模型的平均分数和标准差
print("Ridge Regression: %.3f (%.3f)" % (results.mean(), results.std()))
###### LASSO线性回归(LASSO Linear Regression)######
# 打印LASSO线性回归的标题
print("\n\033[1;30mLASSO线性回归(LASSO Linear Regression):\033[0m")
# 初始化KFold交叉验证,设置分割数为10,随机状态为7,以及打乱数据顺序
kfold = KFold(n_splits=10, random_state=7, shuffle=True)
# 实例化Lasso模型
model = Lasso()
# 设置评估指标为负均方误差
scoring = 'neg_mean_squared_error'
# 进行交叉验证,并存储结果
results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
# 打印LASSO线性回归的平均误差和标准差
print("LASSO Linear Regression: %.3f (%.3f)" % (results.mean(), results.std()))
###### 弹性网回归(Elastic Net Regression)######
# 此代码块实现了弹性网回归模型的交叉验证。
# 目的是评估弹性网回归在给定数据集上的表现。
# 使用KFold进行交叉验证,保证评估的准确性和泛化能力。
# 参数:
# X: 特征矩阵,用于训练弹性网回归模型。
# Y: 目标变量矩阵,对应于特征的标签。
print("\n\033[1;30m弹性网回归(Elastic Net Regression):\033[0m")
# 初始化KFold交叉验证器
kfold = KFold(n_splits=10, random_state=7, shuffle=True)
# 实例化弹性网回归模型
model = ElasticNet()
# 指定评估模型的指标为负均方误差
scoring = 'neg_mean_squared_error'
# 使用交叉验证评估模型性能
results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
# 打印弹性网回归模型的平均性能和标准差
print("Elastic Net Regression: %.3f (%.3f)" % (results.mean(), results.std()))
#### K-近邻(k-Nearest Neighbors, KNN)######
# 此部分为K-近邻算法(KNN)的模型评估
print("\n\033[1;30mK-近邻(k-Nearest Neighbors, KNN):\033[0m")
# 设置交叉验证为10折,随机种子为7,并随机打乱数据
kfold = KFold(n_splits=10, random_state=7, shuffle=True)
# 初始化K近邻回归模型
model = KNeighborsRegressor()
# 设置评估指标为负均方误差
scoring = 'neg_mean_squared_error'
# 进行交叉验证,并存储结果
results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
# 打印KNN模型的平均误差和标准差
print("KNN: %.3f (%.3f)" % (results.mean(), results.std()))
###### 分类和回归树(Classification and Regression Trees, CART)######
# 此部分代码用于展示和评估分类和回归树(CART)模型的性能。
# 使用K-Fold交叉验证(kfold)来评估模型,基于负均方误差(scoring)作为评分指标。
print("\n\033[1;30m分类和回归树(Classification and Regression Trees, CART):\033[0m")
# 设置K-Fold交叉验证为10折,并设置随机种子为7,确保结果可复现,同时设置shuffle为True以随机打乱数据。
kfold = KFold(n_splits=10, random_state=7, shuffle=True)
# 使用决策树回归器作为CART模型。
model = DecisionTreeRegressor()
# 设置评分指标为负均方误差,这在回归问题中是常用的评价指标。
scoring = 'neg_mean_squared_error'
# 使用交叉验证来评估模型的性能,返回每个折的评分结果。
results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
# 打印CART模型的平均性能和标准差,以了解其一般化性能。
print("CART: %.3f (%.3f)" % (results.mean(), results.std()))
###### 支持向量机(Support Vector Machines, SVM)######
# 此部分代码用于展示支持向量机(SVM)的性能。
# 使用K-Fold交叉验证(10折)来评估SVM模型在给定数据集上的表现。
# 模型评估指标为负均方误差(neg_mean_squared_error)。
print("\n\033[1;30m支持向量机(Support Vector Machines, SVM):\033[0m")
# 设置K-Fold交叉验证的参数
kfold = KFold(n_splits=10, random_state=7, shuffle=True)
# 创建SVR模型实例
model = SVR()
# 指定评估模型的指标为负均方误差
scoring = 'neg_mean_squared_error'
# 执行交叉验证,并存储结果
results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
# 打印SVM模型的平均性能和标准差
print("SVM: %.3f (%.3f)" % (results.mean(), results.std()))结果,如下:


















 6324
6324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











