






论文阅读 | PR 2025 | D3Fuse:基于三维特征的红外与可见光图像融合策略

题目:A three-dimensional feature-based fusion strategy for infrared and visible image fusion
会议:PATTERN RECOGNITION(PR)
论文:https://www.sciencedirect.com/science/article/abs/pii/S0031320324006368
代码:未公开
年份:2025
1.摘要&&引言
现有融合方法因缺乏对场景本质特征的关注,存在场景失真问题,且由于缺乏真实标签,关键信息表征不充分。
为此,提出了一种基于三维特征融合策略的新型红外与可见光图像融合网络(D3Fuse)。该方法考虑源图像中的场景语义信息,将两幅图像的共同内容作为第三维特征提取,扩展了融合任务的特征空间。
具体而言,设计了共同特征提取模块(CFEM)来提取场景共同特征,随后将场景共同特征与模态特征结合构建融合图像。
此外,为确保不同特征的独立性和多样性,采用基于多尺度 PCA 编码的对比学习策略,以无监督方式拉大特征距离,促使编码器提取更具判别性的信息,且不增加额外参数和计算成本。
同时,利用对比增强策略确保模态信息的充分表征。在三个数据集上的定性和定量评估结果表明,该方法具有更好的视觉性能和更高的客观指标,且计算成本更低。目标检测实验显示,我们的结果在高层语义任务上表现优异。
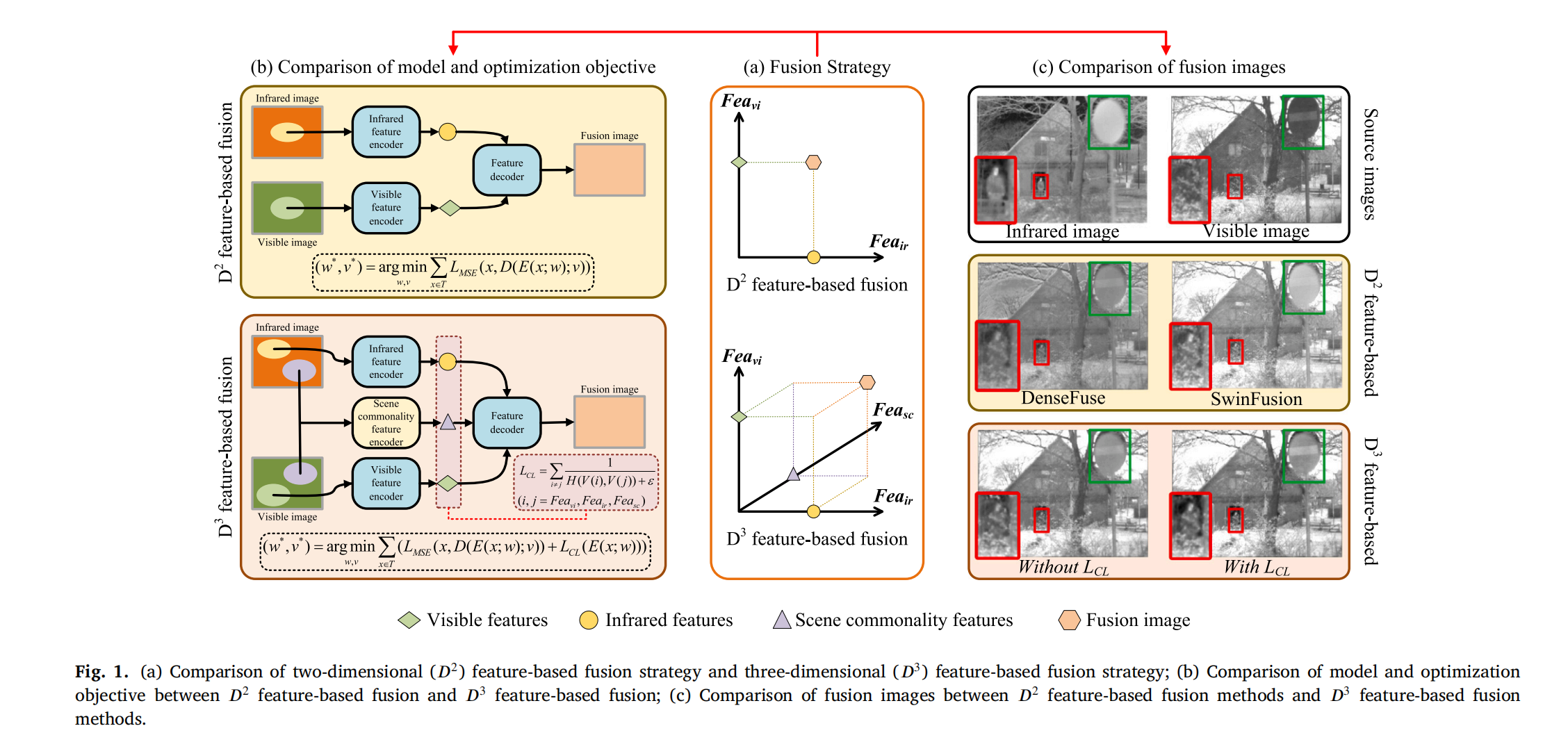
图1. (a) 基于二维( D 2 D^2 D2)特征的融合策略与基于三维( D 3 D^3 D3)特征的融合策略对比;(b) 基于 D 2 D^2 D2特征的融合与基于 D 3 D^3 D3特征的融合在模型及优化目标上的对比;© 基于 D 2 D^2 D2特征的融合方法与基于 D 3 D^3 D3特征的融合方法在融合图像上的对比。
如图 1(a)所示,D3Fuse 通过提升特征编码的维度,不同于现有融合方法的融合策略。融合图像由三组不同的特征合成:红外特征(Fea_ir)、可见光特征(Fea_vi)和场景共同特征(Fea_sc)。
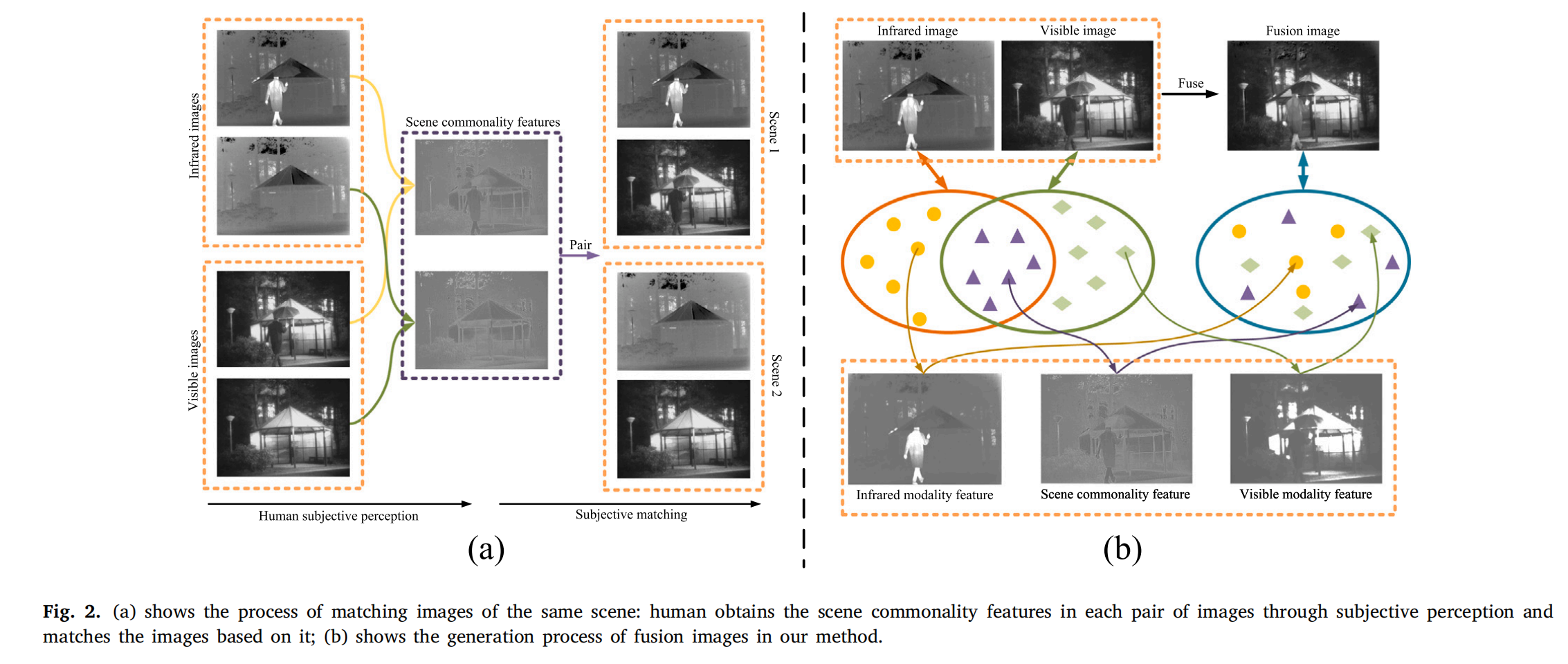
图2. (a) 展示了同一场景图像的匹配过程:人类通过主观感知获取每对图像中的场景共同特征,并基于该特征对图像进行匹配;(b) 展示了我们方法中融合图像的生成过程。
图 2(a)展示了人类通过主观感知关联不同图像模态下场景的过程,首先通过主观感知提取场景共同特征,然后利用共享信息促进图像匹配。利用这一现象,从红外和可见光图像中提取的场景共同特征封装了场景的内在属性,增强了人类视觉系统对场景的理解。为了提高融合结果的视觉和语义表示,采用了一种将场景共同特征融入融合结果的创新方法,如图 2(b)所示。
如图 1(b)所示,现有基于二维( D 2 D^2 D2)特征的融合策略使用两组编码器提取红外和可见光特征,然后通过解码器将这些特征集成并重建为融合图像。网络的优化目标如下:
( w ∗ , v ∗ ) = arg min w , v ∑ x ∈ T L M S E ( x , D ( E ( x ; w ) ; v ) ) (w^*, v^*) = \underset{w, v}{\arg \min} \sum_{x \in T} L_{MSE}(x, D(E(x; w); v)) (w∗,v∗)=w,vargminx∈T∑LMSE(x,D(E(x;w);v))
其中,x表示输入数据,T表示训练集,E和w分别对应编码器及其待优化参数,D和v分别表示解码器及其待优化参数, L M S E L_{MSE} LMSE表示均方误差损失, w ∗ w^* w∗、 v ∗ v^* v∗表示优化后的参数。通过引入场景共同特征 F e a s c Fea_{sc} Feasc,我们将编码空间扩展到三维。
如图 1(b)的网络架构所示,设计了一个共同特征提取模块(CFEM)来提取 F e a s c Fea_{sc} Feasc,并采用对比学习约束( L C L L_{CL} LCL)来扩展特征空间。网络的修正优化目标如下:
( w ∗ , v ∗ ) = arg min w , v ∑ x ∈ T L M S E ( x , D ( E ( x ; w ) ; v ) ) + L C L ( E ( x ; w ) ) (w^*, v^*) = \underset{w, v}{\arg \min} \sum_{x \in T} L_{MSE}(x, D(E(x; w); v)) + L_{CL}(E(x; w)) (w∗,v∗)=w,vargminx∈T∑LMSE(x,D(E(x;w);v))+LCL(E(x;w))
其中, L C L L_{CL} LCL表示对比学习约束,其计算如下: L C L = ∑ i ≠ j 1 H ( V ( i ) , V ( j ) ) + ε L_{CL} = \sum_{i \neq j} \frac{1}{H(V(i), V(j)) + \varepsilon} LCL=∑i=jH(V(i),V(j))+ε1
其中, ( i , j ) (i, j) (i,j)表示不同类别特征的组合,r表示基于对比学习模块的压缩编码向量, ε \varepsilon ε是一个常数项。
具体来说,为确保不同特征之间的独立性,设计了一个对比学习模块来优化编码网络的特征提取能力。该模块通过多尺度主成分分析(PCA)编码对特征进行压缩编码,并以无监督方式提高其独立性。
此外,我们采用对比增强策略来提高模型检索有效信息和重建像素的能力。
图 1(c)展示了基于 D 2 D^2 D2 特征和 D 3 D^3 D3 特征的融合策略在融合性能上的比较。基于 D 2 D^2 D2 特征的两种方法存在场景表示不完整的问题,例如,Densefuse 保留了大量红外冗余信息,而 SwinFusion 则丢失了部分可见背景信息。通过补充场景共同特征,基于 D 3 D^3 D3 特征的融合方法在没有 L C L L_{CL} LCL的情况下,场景表示得到了一定程度的改善。此外, L C L L_{CL} LCL的引入通过对比学习扩展特征空间,进一步优化了融合性能。
2. 方法
2.1场景共同特征的定义
图像传感器捕捉的场景信息用于构建特定模态的图像。我们将不同模态的信息视为独立集合,红外模态信息用 θ i r \theta_{ir} θir表示,可见光模态信息用 θ v i \theta_{vi} θvi表示。
在图 2(b)中,展示了一些相似场景的图像。我们可以通过主观感知轻松找到同一场景的图像对,这表明两种模态的图像都包含能够描述场景本质特征的深层特征。我们将这种深层特征定义为场景共同信息集
θ
s
c
\theta_{sc}
θsc,它是红外和可见光图像的交集,且独立于模态信息集。其数学描述如下:
{
e
s
c
∈
I
i
r
∩
I
v
i
θ
s
c
=
θ
i
r
∩
θ
v
i
θ
s
c
=
θ
s
c
∩
(
θ
i
r
∪
θ
v
i
)
\left\{ \begin{array}{l} e_{sc} \in I_{ir} \cap I_{vi} \\ \theta_{sc} = \theta_{ir} \cap \theta_{vi} \\ \theta_{sc} = \theta_{sc} \cap (\theta_{ir} \cup \theta_{vi}) \end{array} \right.
⎩
⎨
⎧esc∈Iir∩Iviθsc=θir∩θviθsc=θsc∩(θir∪θvi)
其中,
I
i
r
I_{ir}
Iir和
I
v
i
I_{vi}
Ivi分别表示红外和可见光图像,
e
s
c
e_{sc}
esc表示
θ
s
c
\theta_{sc}
θsc中的元素,
∅
\varnothing
∅表示空集。与模态特征相比,场景共同特征可以以高度简洁的方式概括现实场景。单一模态的图像可以视为特定模态与场景共同特征的共同作用。此外,红外和可见光融合图像
I
f
I_f
If可以视为两种模态和场景共同特征以合理方式的组合,其数学描述如下:
{
I
i
r
=
θ
i
r
∪
θ
s
c
I
v
i
=
θ
v
i
∪
θ
s
c
I
f
=
F
(
θ
i
r
,
θ
v
i
)
∪
θ
s
c
\left\{ \begin{array}{l} I_{ir} = \theta_{ir} \cup \theta_{sc} \\ I_{vi} = \theta_{vi} \cup \theta_{sc} \\ I_f = F(\theta_{ir}, \theta_{vi}) \cup \theta_{sc} \end{array} \right.
⎩
⎨
⎧Iir=θir∪θscIvi=θvi∪θscIf=F(θir,θvi)∪θsc
其中,F表示融合操作。
2.2框架概述
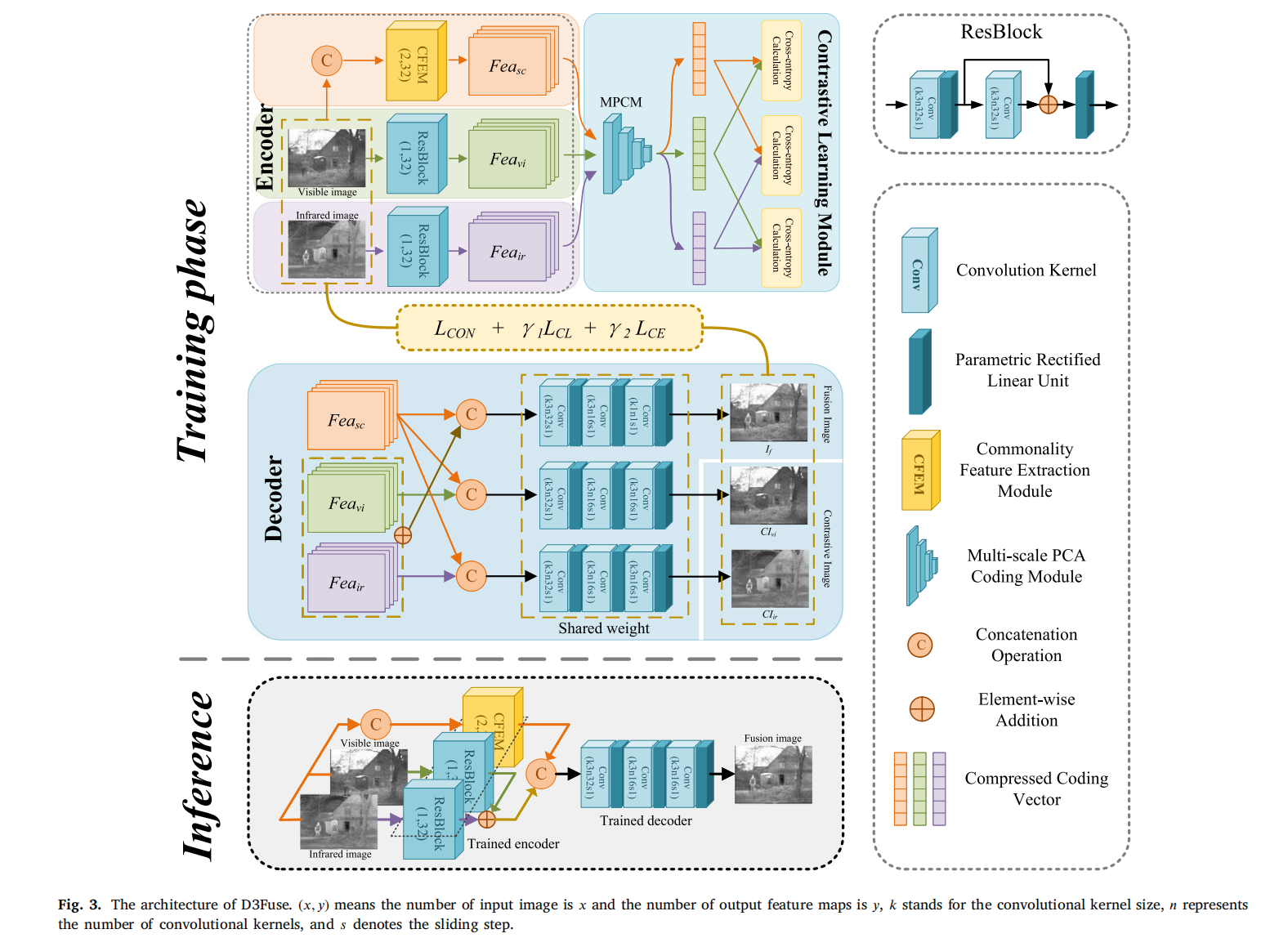
图3. D3Fuse的架构。(𝑥, 𝑦)表示输入图像的数量为𝑥且输出特征图的数量为𝑦,𝑘代表卷积核大小,𝑛表示卷积核的数量,𝑠表示滑动步长。
如图 3 所示,在训练阶段,我们的模型由编码器、对比学习模块和解码器组成。
为了缓解因信息丢失导致的场景失真,我们将场景共同特征( F e a s c Fea_{sc} Feasc)融入融合图像。编码器对源图像进行处理,以提取模态和场景共同信息。我们将场景共同信息定义为源图像的交集,并使用共同特征提取模块(CFEM)从红外和可见光图像中深入挖掘深层场景内容。
独立的残差块(ResBlocks)用于提取可见光( F e a v i Fea_{vi} Feavi)和红外( F e a i r Fea_{ir} Feair)模态特征,每个残差块由两个 3×3 卷积核和一个跳跃连接组成。
为了在优化过程中保持不同特征的独立性,我们采用对比学习模块来增大特征图之间的距离,该模块仅在训练期间运行。它通过多尺度 PCA 编码模块(MPCM)将输入特征图压缩为一维向量,并计算这些向量之间的交叉熵作为对比学习损失 L C L L_{CL} LCL,这一过程促使编码器专注于判别性信息并忽略冗余细节。
解码器使用提取的特征图通过两个 3×3 和一个 1×1 卷积核生成输出图像。为了最小化模态信息之间的冲突,我们实施对比增强策略,将场景共同特征与可见光 / 红外特征图融合以创建对比图像( C I v i CI_{vi} CIvi和 C I i r CI_{ir} CIir),这些对比图像与源图像进行比较以计算对比增强损失 L C E L_{CE} LCE,从而强化解码器准确选择和重建特征的能力。如图 3 所示,在推理阶段,D3Fuse 由训练好的编码器和解码器组成,以较少的参数生成融合图像。
2.3共同特征提取模块(CFEM)
为了有效提取场景共同信息,我们开发了共同特征提取模块(CFEM),其架构如图 4 所示。
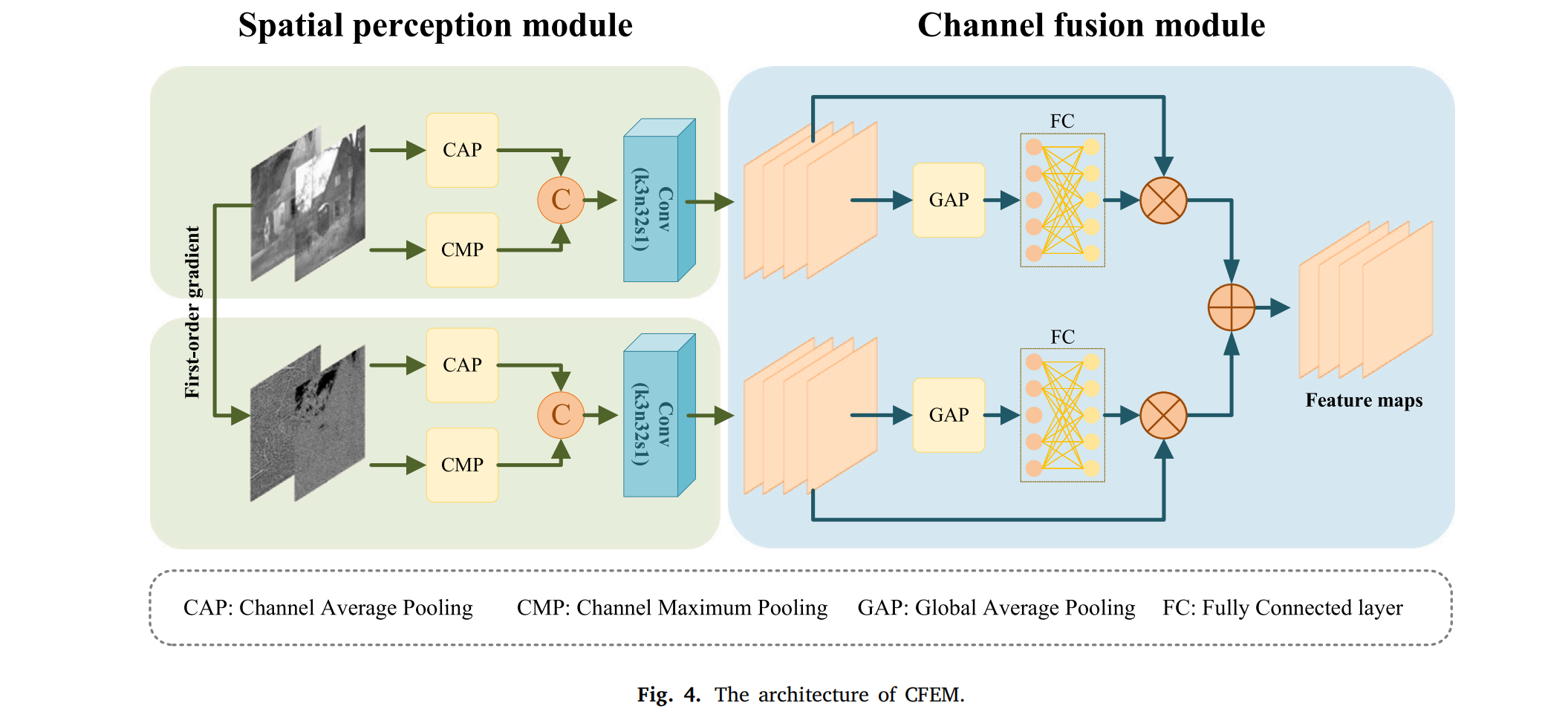
场景共同信息包含两种模态图像中的共享深层特征,包括像素分布和边缘细节。为了有效辨别场景边缘,对源图像应用一阶梯度计算以生成一组梯度图像,随后源图像和梯度图像通过最大池化和平均池化策略同时进行池化,所得特征通过 3×3 卷积操作进一步处理以提取深层特征。为了细化场景特征并减轻模态特定信息的影响,采用通道注意力机制,该机制专注于关键场景细节并最小化无关信息的影响。具体而言,特征图经过全局平均池化(GAP)和全连接层(FC)处理,然后与输入相乘得到加权结果,加权特征图通过元素相加组合,最终生成场景共同特征图。
2.4对比学习策略
由于缺乏真实标签,网络的优化方向存在一定偏差,可能导致信息冗余和关键特征丢失。为了优化有效信息的提取,实施对比学习策略以引导编码器。
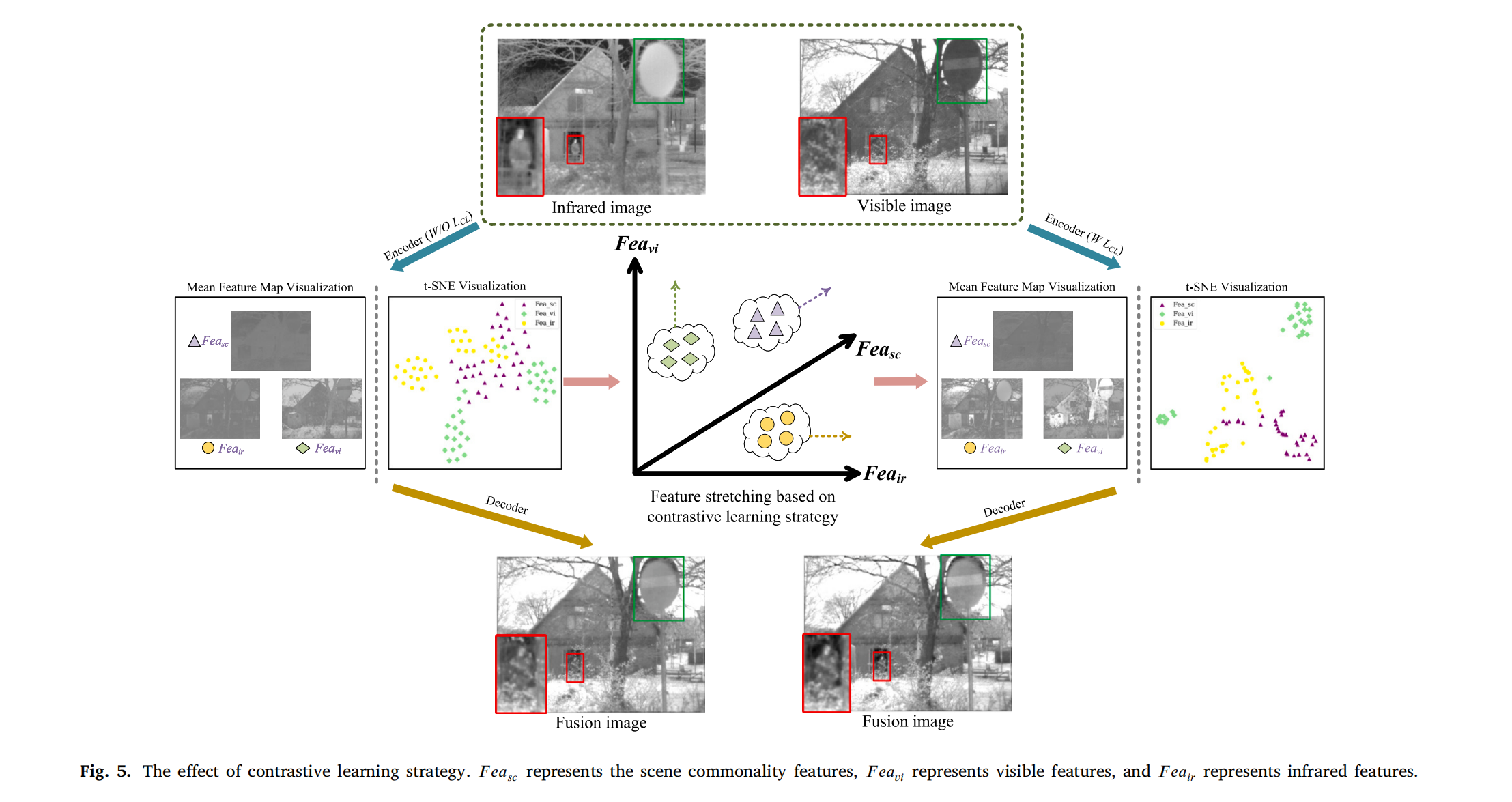
图5. 对比学习策略的效果。(Fea_{sc})表示场景共同特征,(Fea_{vi})表示可见光特征,(Fea_{ir})表示红外特征。
图 5 展示了特征均值图和 t 分布随机邻域嵌入(t-SNE)可视化结果。
特征均值图通过对编码器提取的每种类型特征的特征图求平均得到,t-SNE 利用非线性降维有效表示特征图之间的相似性。在没有 L C L L_{CL} LCL约束的情况下,特征图存在信息不足的问题,例如红外特征均值图中的前景目标不突出,可见光特征均值图中的纹理细节不足,场景共同特征未能聚焦关键场景内容。此外,t-SNE 可视化显示,仅依赖端到端损失约束会导致不同类型特征之间的高相似性和差独立性。
所提出的对比学习策略有效拉大了不同类型特征之间的距离,如图 5 所示,在 L C L L_{CL} LCL约束下,同类特征聚集在一起,不同类特征分散开来,表明 L C L L_{CL} LCL有效增强了特征之间的独立性并扩展了特征空间。特征均值图的可视化还表明,在 L C L L_{CL} LCL约束下,三种类型特征的有效信息更加全面,且具有 L C L L_{CL} LCL约束的融合图像相比无约束的融合结果具有更优的视觉质量。
在对比学习策略的具体过程中,编码器提取的特征图被压缩为具有语义代表性的一维向量,然后计算向量之间的交叉熵。
压缩编码需要保留原始特征的主要信息,因此设计了基于多尺度 PCA 的编码模块(MPCM),利用 PCA 保留特征图的主要和简化信息,MPCM 的架构如图 6 所示。
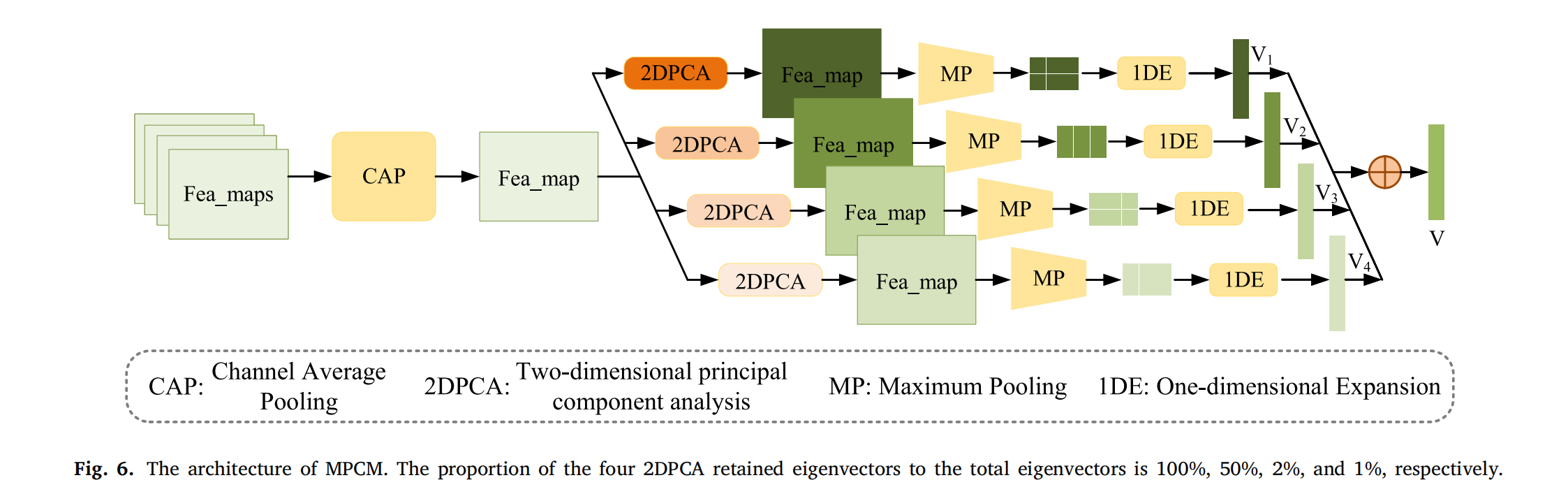
图6. 多尺度主成分分析编码模块(MPCM)的架构。四个二维主成分分析(2DPCA)模块保留的特征向量占总特征向量的比例分别为100%、50%、2%和1%。
输入特征图首先通过通道平均池化在通道维度上进行压缩,有效降低维度同时保留关键信息,随后通道平均池化的输出通过一系列具有不同衰减率的二维 PCA 模块处理,这些衰减率决定了 PCA 压缩期间保留的特征向量数量,从而能够提取多尺度成分。具体而言,第一个二维 PCA 模块保留 100% 的特征向量,第二个保留 50%,第三个保留 2%,第四个保留 1%。每个二维 PCA 模块之后应用最大池化操作,以在空间维度上进一步压缩输出,最终将所有二维 PCA 模块的一维编码向量聚合以生成最终特征码。
2.5损失函数
总损失函数由三部分组成,即内容损失(
L
C
O
N
L_{CON}
LCON)、对比学习损失(
L
C
L
L_{CL}
LCL)和对比增强损失(
L
C
E
L_{CE}
LCE),其数学公式如下:
L
=
L
C
O
N
+
γ
1
L
C
L
+
γ
2
L
C
E
L = L_{CON} + \gamma_1 L_{CL} + \gamma_2 L_{CE}
L=LCON+γ1LCL+γ2LCE
其中,
γ
1
\gamma_1
γ1和
γ
2
\gamma_2
γ2为固定权重。
内容损失:
我们旨在获得具有详细背景和清晰目标的红外与可见光融合图像,背景来自可见光图像,目标由红外特征表征。为确保全面的模态信息提取,我们采用强度损失。为识别场景中的目标区域,使用滑动窗口方法,在这些区域中,当红外像素值超过可见光像素值时,对融合图像与红外内容之间的距离施加
l
2
l_2
l2范数约束,通过使用
l
1
l_1
l1范数约束控制融合图像与可见光图像之间的距离来保持完整的可见背景,其数学公式如下:
L
C
O
N
=
∥
I
f
−
I
v
i
∥
1
+
∑
i
=
1
n
α
i
∥
I
f
∣
W
i
−
I
i
r
∣
W
i
∥
2
2
L_{CON} = \left\| I_f - I_{vi} \right\|_1 + \sum_{i=1}^{n} \alpha_i \left\| I_f|_{W_i} - I_{ir}|_{W_i} \right\|_2^2
LCON=∥If−Ivi∥1+i=1∑nαi∥If∣Wi−Iir∣Wi∥22
其中,
W
i
W_i
Wi表示滑动窗口(窗口大小设置为
10
×
10
10×10
10×10),
i
i
i为当前窗口位置,
α
i
\alpha_i
αi仅为 0 或 1,表示当前窗口是否为目标区域,
α
i
\alpha_i
αi的计算如下:
α
i
=
{
1
,
如果
M
(
I
i
r
∣
W
i
)
≥
M
(
I
v
i
∣
W
i
)
0
,
如果
M
(
I
i
r
∣
W
i
)
<
M
(
I
v
i
∣
W
i
)
,
i
=
(
1
,
…
,
n
)
\alpha_i = \begin{cases} 1, & \text{如果 } M(I_{ir}|_{W_i}) \geq M(I_{vi}|_{W_i}) \\ 0, & \text{如果 } M(I_{ir}|_{W_i}) < M(I_{vi}|_{W_i}) \end{cases}, \quad i = (1, \dots, n)
αi={1,0,如果 M(Iir∣Wi)≥M(Ivi∣Wi)如果 M(Iir∣Wi)<M(Ivi∣Wi),i=(1,…,n)
其中,
M
M
M表示均值计算。
对比学习损失:
基于场景共同特征和模态特征的性质,利用对比学习策略拉大不同特征之间的距离。具体而言,首先将编码器提取的编码特征压缩为一维向量,计算所有类型向量之间的交叉熵作为对比学习损失
L
C
L
L_{CL}
LCL。在
L
C
L
L_{CL}
LCL的约束下,引导编码器在训练期间提取足够的模态和场景共同特征,
L
C
L
L_{CL}
LCL的公式如下:
L
C
L
=
1
H
(
V
c
o
m
,
V
i
r
)
+
1
H
(
V
c
o
m
,
V
v
i
)
+
1
H
(
V
v
i
,
V
i
r
)
L_{CL} = \frac{1}{H(V_{com}, V_{ir})} + \frac{1}{H(V_{com}, V_{vi})} + \frac{1}{H(V_{vi}, V_{ir})}
LCL=H(Vcom,Vir)1+H(Vcom,Vvi)1+H(Vvi,Vir)1
其中,
V
i
r
V_{ir}
Vir、
V
v
i
V_{vi}
Vvi和
V
c
o
m
V_{com}
Vcom分别表示红外模态、可见光模态和场景共同特征的一维向量,
H
H
H表示交叉熵计算,其公式如下:
H
(
p
,
q
)
=
−
∑
i
=
1
n
p
(
i
)
log
2
q
(
i
)
H(p, q) = -\sum_{i=1}^{n} p(i) \log_2 q(i)
H(p,q)=−i=1∑np(i)log2q(i)
其中,
p
p
p和
q
q
q表示向量,
n
n
n为元素总数。
对比增强损失:
为了提高模态信息的表征能力,在训练阶段采用对比增强策略。在解码过程中,模态和场景共同信息被集成到融合结果中,但由于红外和可见光模态之间的冲突,解码器可能会丢失一些有价值的特征。为了保留完整的模态内容,我们提取单模态特征并通过与场景共同特征融合来重建单模态图像,这些重建图像被称为红外对比图像
C
I
i
r
CI_{ir}
CIir和可见光对比图像
C
I
v
i
CI_{vi}
CIvi,所有这些过程都使用权重共享的解码器进行。然后通过将对比图像与源图像进行比较来计算对比增强损失
L
C
E
L_{CE}
LCE,其公式如下:
L
C
E
=
∥
C
I
i
r
−
I
i
r
∥
2
2
+
∥
C
I
v
i
−
I
v
i
∥
2
2
L_{CE} = \left\| CI_{ir} - I_{ir} \right\|_2^2 + \left\| CI_{vi} - I_{vi} \right\|_2^2
LCE=∥CIir−Iir∥22+∥CIvi−Ivi∥22
L
C
E
L_{CE}
LCE可以约束解码器保留更多的模态信息。
3. 实验验证
3.1 实验细节
实验数据集:
我们在实验中使用了三个数据集,即 TNO、RoadScene 和 M3FD 数据集。TNO 数据集主要描述多样化的军事场景,我们从中选取 35 对图像用于模型训练。为了扩展训练数据,我们将这些图像裁剪为 128×128 的补丁,步长设置为 35,得到 5780 对子图像。RoadScene 数据集包含 221 对红外和可见光图像,主要描述复杂的交通场景。M3FD 数据集有 300 对红外和可见光图像,涵盖四种主要场景,具有不同的环境、光照、季节和天气,像素变化范围广泛。我们采用 TNO、RoadScene 和 M3FD 数据集进行测试实验。
实验配置:
我们使用内容损失
L
C
O
N
L_{CON}
LCON、对比学习损失
L
C
L
L_{CL}
LCL和对比增强损失
L
C
E
L_{CE}
LCE来引导网络的优化,总损失如下:
L
=
L
C
O
N
+
γ
1
L
C
L
+
γ
2
L
C
E
L = L_{CON} + \gamma_1 L_{CL} + \gamma_2 L_{CE}
L=LCON+γ1LCL+γ2LCE
其中,
γ
1
\gamma_1
γ1和
γ
2
\gamma_2
γ2均设置为 1。批量大小设置为 20,学习率初始化为
2
×
1
0
−
5
2×10^{-5}
2×10−5。所有训练和测试均在配备 22GB 内存的 NVIDIA GeForce RTX 2080 Ti 和 1.80GHz 的 AMD Ryzen 7 4800U 上进行。
测试细节:
采用定性和定量方式评估我们方法的有效性。
• 定性评估:依赖于人类对融合图像的主观评价。为了增强定性比较,我们在 RoadScene 和 M3FD 数据集的融合结果中引入颜色信息,这涉及将 RGB 可见光图像转换为 YCbCr 颜色空间,将 Y 通道与红外图像融合以创建灰度融合图像,然后组合 Cb 和 Cr 通道以返回 RGB 格式。
• 定量分析:涉及六个指标:互信息(MI)、熵(EN)、标准差(SD)、结构相似性(SSIM)、融合视觉信息保真度(VIFF)和差异相关性之和(SCD)。
• MI 衡量融合图像中包含的源图像信息量
• EN 评估融合图像中的信息丰富度
• SD 表征灰度级分布
• SSIM 评估融合图像与源图像之间的结构相似性
• VIFF 量化融合图像的视觉性能
• SCD 表示融合图像与源图像之间的相关性(更高的值表示更好的图像质量)
此外,进行目标检测实验以验证红外和可见光融合图像在高级视觉任务中的有效性。目标检测涉及基于高层语义信息识别和分类对象,YOLOv5 是用于此目的的流行模型,我们利用 YOLOv5 评估我们的方法和对比方法的目标检测性能。
已按要求将LaTeX公式转换为Markdown格式,原文其他内容保持不变:
3.2 消融实验
我们进行了四个消融实验来证明我们工作的有效性,包括场景共同特征、对比学习策略、共同特征提取模块和对比增强策略。所有实验均遵循控制变量原则,并在相同的硬件条件下进行。
3.2.1 场景共同特征的有效性
为了增强视觉表示,我们将场景共同特征融入融合图像和对比图像,因为这些特征描述了红外和可见光图像中一致的场景本质特征。进行消融实验以验证场景共同特征的影响,在该实验中,我们从解码过程中排除场景共同特征,仅依赖模态特征来构建融合和对比图像,所有其他训练方面与 D3Fuse 一致。

图7. 场景共同特征的消融实验结果。消融结果:(IR1) 红外对比图像;(VI1) 可见光对比图像;(F1) 融合图像。我们的结果:(IR2) 红外对比图像;(VI2) 可见光对比图像;(F2) 融合图像。图中选取了一个基于可见光的场景区域(绿色框)和一个基于红外的场景区域(红色框)。(关于图注中颜色引用的解释,读者可参考本文的网络版本。)
实验结果如图 7 所示,没有场景共同特征时,消融结果表明红外对比图像(IR1)和融合图像(F1)缺乏完整的目标细节,此外,可见光对比图像(VI1)和融合图像(F1)中的背景细节模糊。相比之下,我们的方法结果与消融结果相比,完全恢复了目标和可见背景细节,这证明了场景共同特征在增强视觉表示方面的有效性。
3.2.2 对比学习策略的有效性
在图像融合中,无效信息的冗余会削弱融合性能,有效信息的丢失会导致融合结果失真。为解决无效信息干扰和信息提取不足的问题,我们设计了对比学习策略来引导编码器的进一步优化。
具体而言,我们通过多尺度 PCA 编码模块获得三种类型特征的隐性标签,并使用对比学习损失来增强标签之间的独立性。在训练期间,编码器被优化以专注于有效信息并排除冗余信息。
为了证明对比学习策略的有效性,进行了两组消融实验:(a)消融对比学习策略(在训练期间去除对比学习模块对编码器的引导),(b)消融多尺度 PCA 编码(去除对比学习模块中 PCA 用于提取多尺度成分的作用),两组消融实验的其他训练细节与 D3Fuse 一致,三种方法的训练细节如图 8 所示。
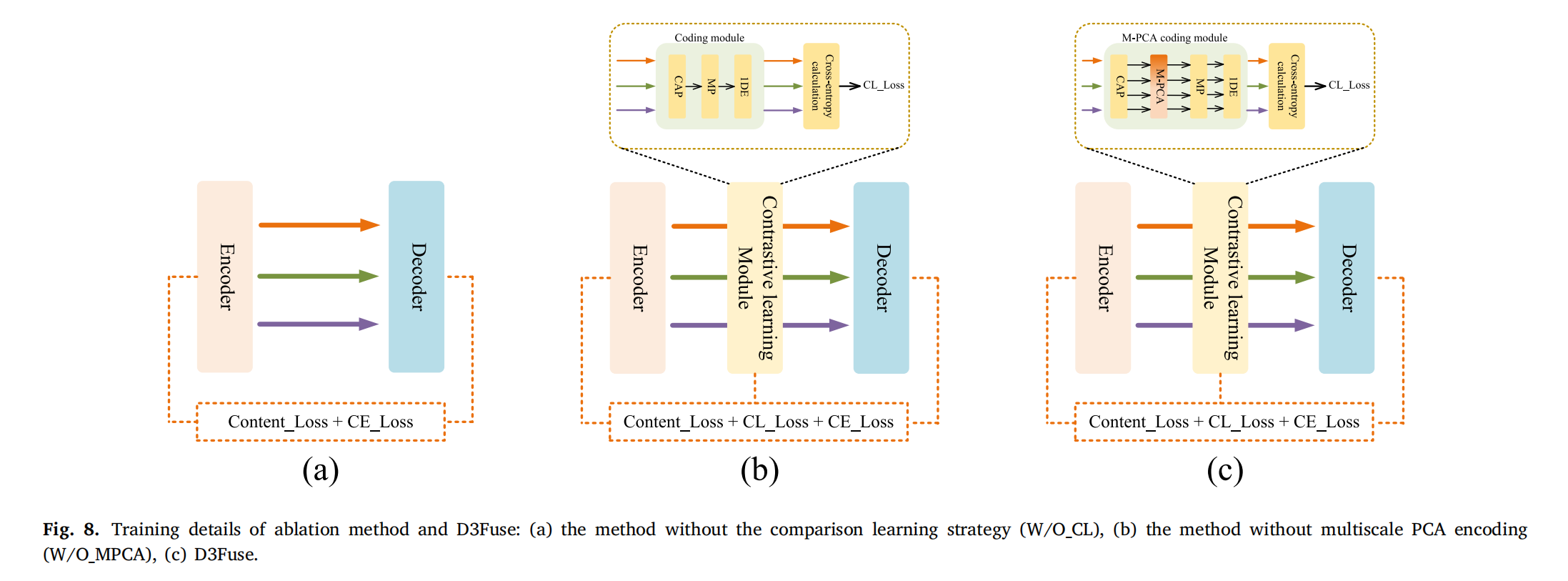
图8. 消融方法与D3Fuse的训练细节:(a) 无对比学习策略的方法(W/O_CL),(b) 无多尺度PCA编码的方法(W/O_MPCA),© D3Fuse。
消融结果如图 9 所示,图 9(A1)可视化了三种方法的特征均值图和融合结果,其中特征均值图通过计算编码特征图的算术平均值得到,例如红外模态特征均值图通过平均所有红外模态特征图得到。没有对比学习策略时,融合图像的天空失去了某些红外特征,地面细节被削弱,原因是三种类型的特征图之间存在大量交叉信息,导致信息冗余。同时,没有多尺度 PCA 编码时,某些红外信息和可见细节丢失,融合图像出现场景失真。相比之下,D3Fuse 的特征图和融合图像完全保留了每个组件的特征。
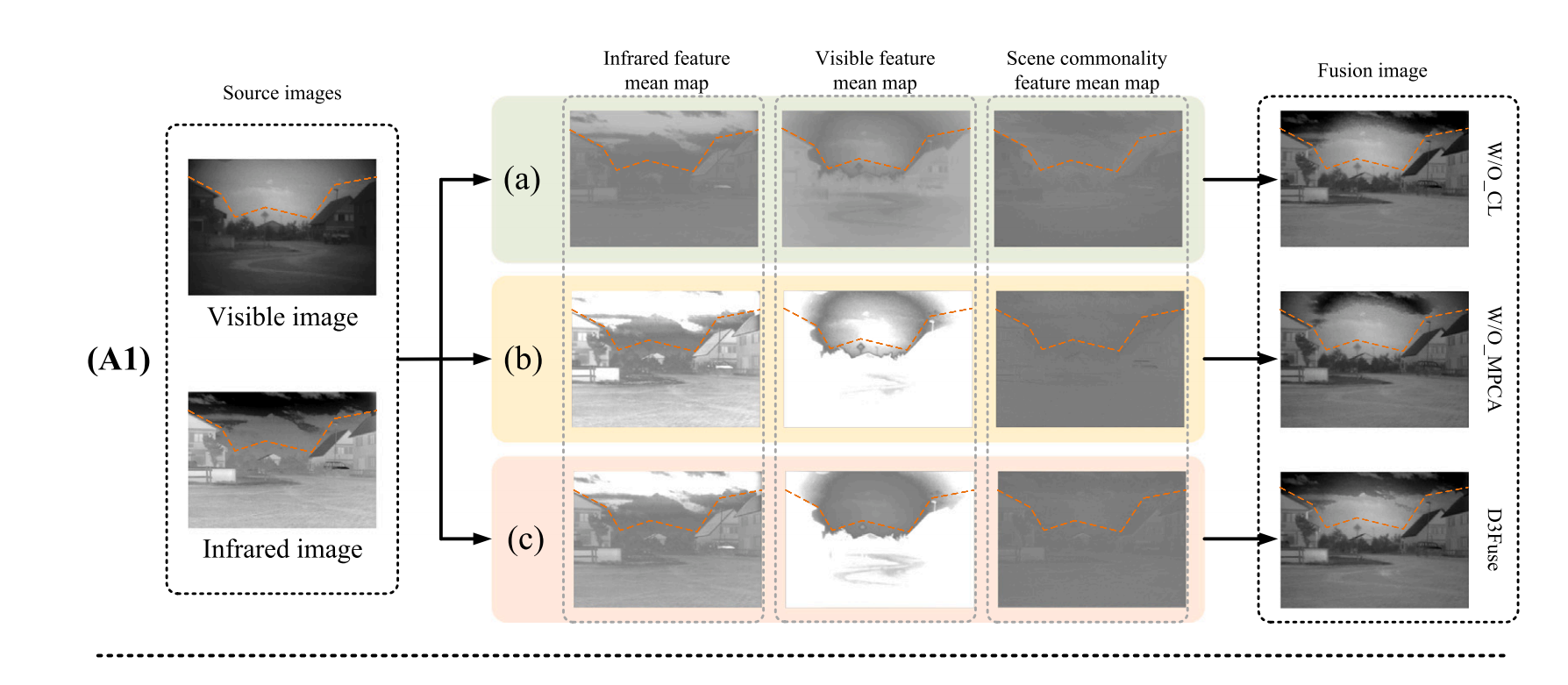
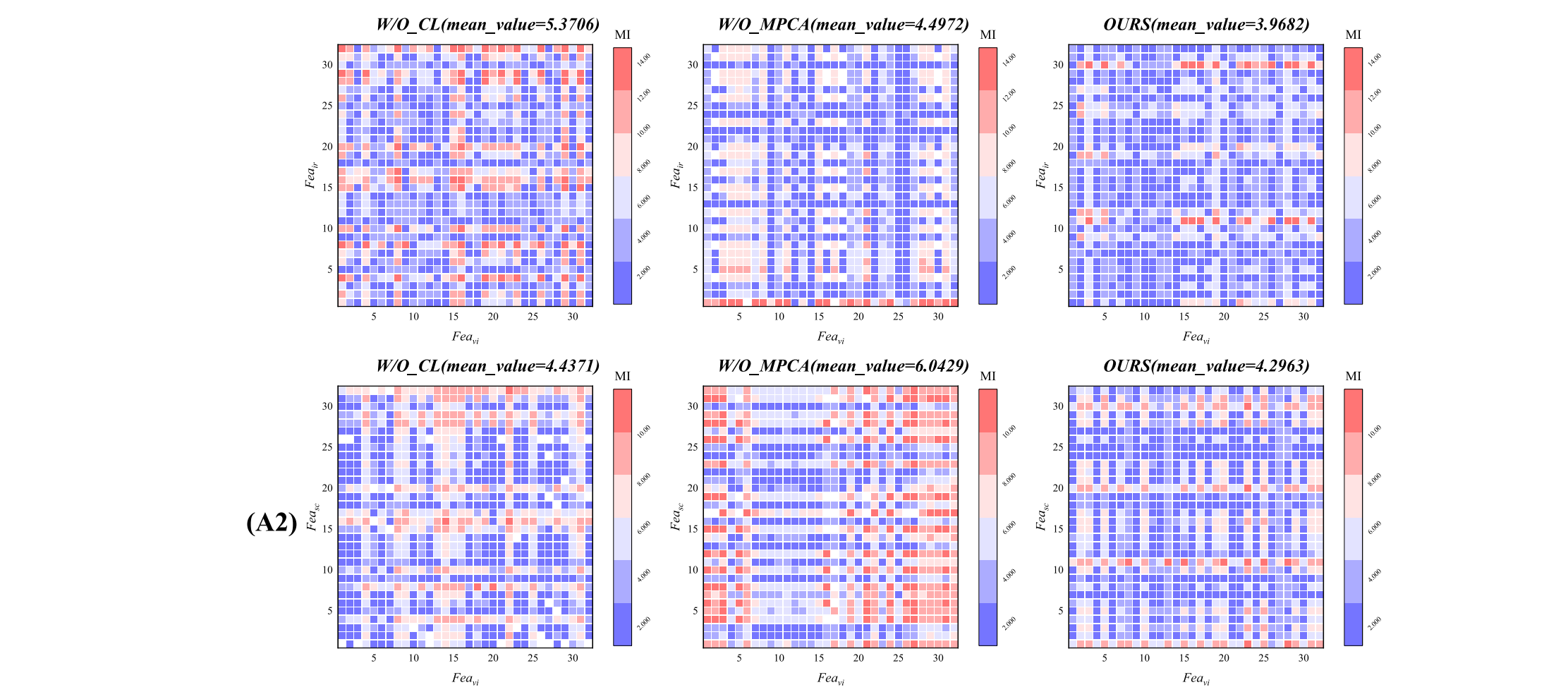
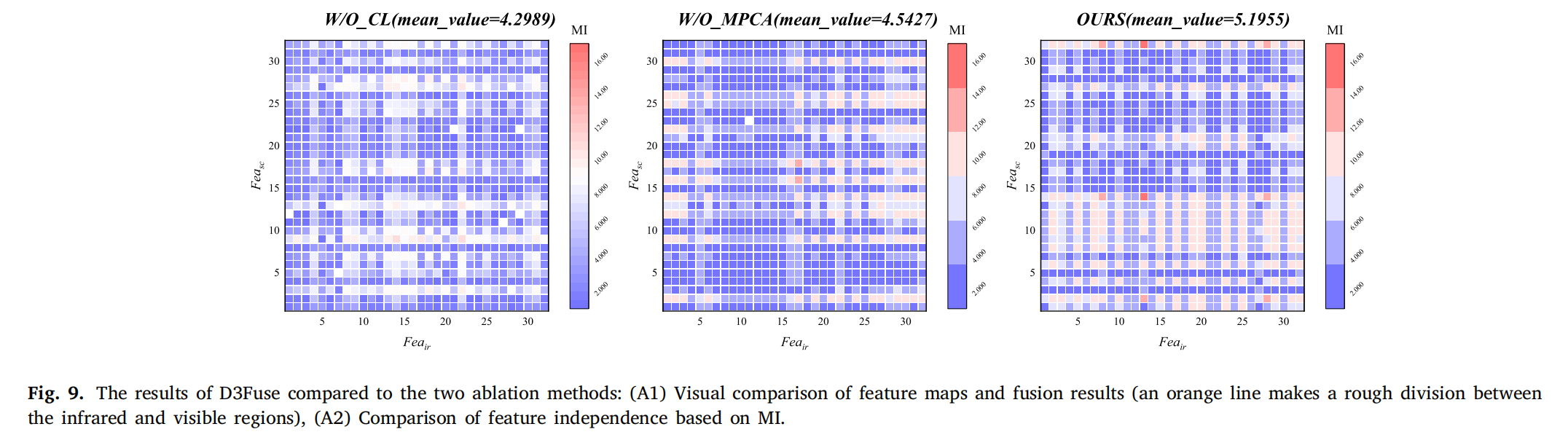
图9. D3Fuse与两种消融方法的结果对比:(A1) 特征图和融合结果的视觉对比(橙色线条大致划分了红外和可见光区域),(A2) 基于互信息(MI)的特征独立性对比。
为了进一步说明对比学习策略对排除冗余信息的效果,图 9(A2)显示了基于不同聚类特征图之间互信息(MI)的热点图。MI 是信息论中的一个指标,用于衡量两个变量之间的依赖关系,其数学描述如下:
M
I
(
A
,
B
)
=
H
(
A
)
+
H
(
B
)
−
H
(
A
,
B
)
MI(A, B) = H(A) + H(B) - H(A, B)
MI(A,B)=H(A)+H(B)−H(A,B)
其中,
H
(
A
)
H(A)
H(A) 和
H
(
B
)
H(B)
H(B) 分别表示特征图 A 和特征图 B 的信息熵,
H
(
A
,
B
)
H(A, B)
H(A,B) 表示 A 和 B 的联合熵,其数学描述如下:
H
(
X
)
=
−
∑
x
=
0
N
−
1
p
X
(
x
)
log
p
X
(
x
)
H(X) = -\sum_{x=0}^{N-1} p_X(x) \log p_X(x)
H(X)=−x=0∑N−1pX(x)logpX(x)
H
(
A
,
B
)
=
−
∑
a
=
0
N
−
1
∑
b
=
0
N
−
1
p
A
/
B
(
a
,
b
)
log
p
A
/
B
(
a
,
b
)
H(A, B) = -\sum_{a=0}^{N-1} \sum_{b=0}^{N-1} p_{A/B}(a, b) \log p_{A/B}(a, b)
H(A,B)=−a=0∑N−1b=0∑N−1pA/B(a,b)logpA/B(a,b)
其中,N 为灰度级数量(值为 255),
p
X
(
x
)
p_X(x)
pX(x) 是灰度级 x 出现在特征图 X 中的概率,
p
A
/
B
(
a
,
b
)
p_{A/B}(a, b)
pA/B(a,b) 是同一位置像素在 A 中为 a 且在 B 中为 b 的概率。热点图中的每个点是不同聚类特征图之间的 MI 值,其计算如下:
H
M
F
1
/
F
2
(
i
,
j
)
=
M
I
(
F
1
i
,
F
2
j
)
HM_{F1/F2}(i, j) = MI(F1^i, F2^j)
HMF1/F2(i,j)=MI(F1i,F2j)
其中,
H
M
(
i
,
j
)
HM(i, j)
HM(i,j) 是热点矩阵的值,
F
1
/
F
2
F1/F2
F1/F2 是不同聚类特征图的组合(即红外特征图
F
e
a
i
r
Fea_{ir}
Feair、可见光特征图
F
e
a
v
i
Fea_{vi}
Feavi 和场景共同特征图
F
e
a
s
c
Fea_{sc}
Feasc),i 和 j 是特征图的数量(值均为 32)。分析表明,对比学习策略通过拉大特征图之间的距离,有效降低了不同聚类特征之间的相关性,从而减少了冗余信息对融合结果的干扰。
3.2.3 CFEM 的有效性
为了有效提取场景共同信息,我们设计了共同特征提取模块(CFEM),它从像素和梯度角度提取源图像的交集,此外,CFEM 可以通过空间和通道感知深化关键信息。通过消融实验,我们用 ResBlock 替换 CFEM 来验证 CFEM 的有效性。实验结果如图 10 所示,ResBlock 提取的场景共同特征未能聚焦场景信息,包含许多可见光和红外模态信息,一些场景信息被削弱(例如(A1)和(A2)中的树枝)。CFEM 提取的场景共同特征包含足够的场景纹理,并显著排除了模态信息的干扰。通过比较融合结果,使用 CFEM 的结果具有更好的场景细节。
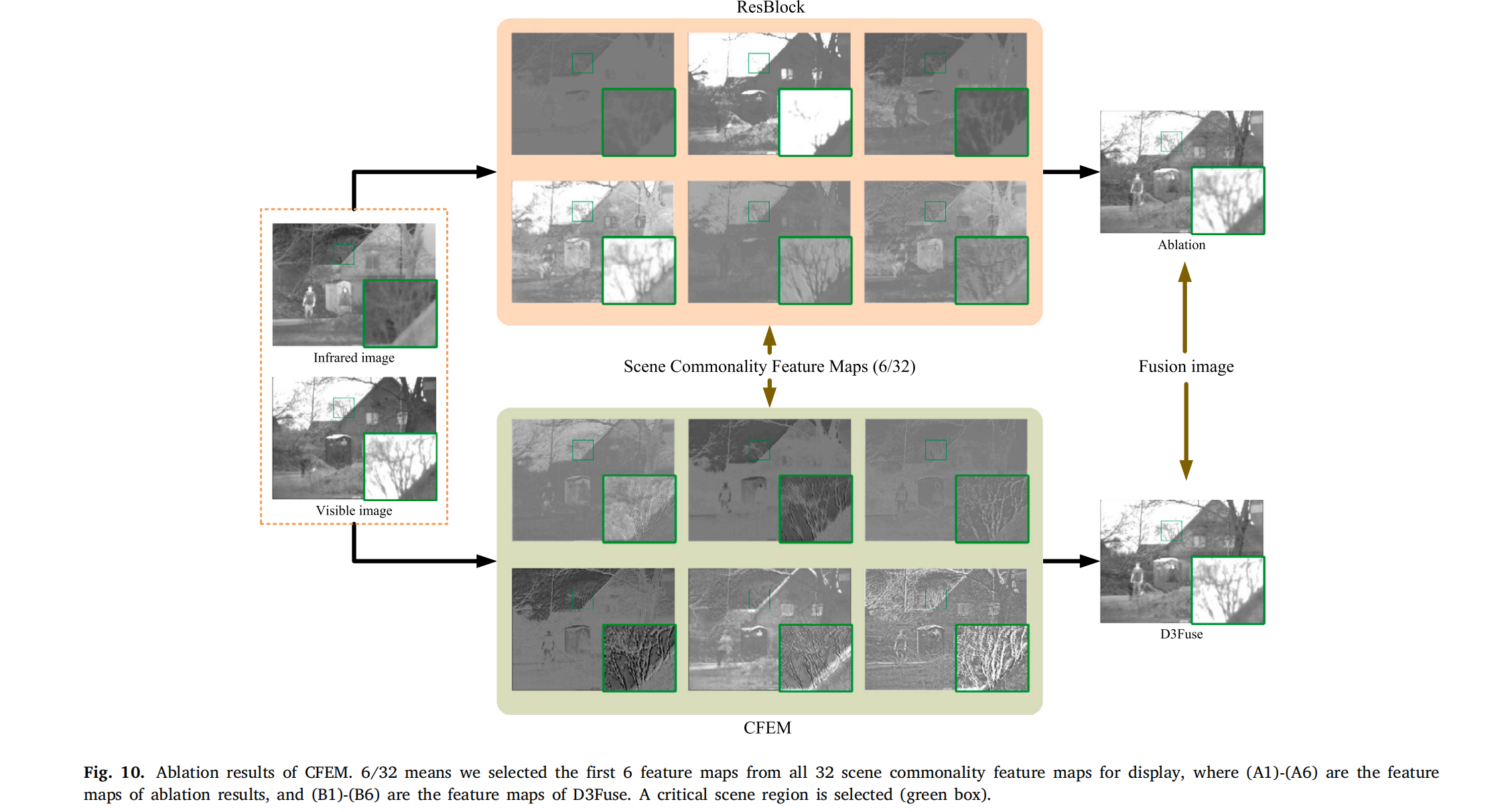
图10. 共同特征提取模块(CFEM)的消融实验结果。6/32表示我们从所有32个场景共同特征图中选取前6个特征图进行展示,其中(A1)-(A6)为消融结果的特征图,(B1)-(B6)为D3Fuse的特征图。图中选取了一个关键场景区域(绿色框)。
3.2.4 对比增强策略的有效性
融合图像可以被视为所有有效信息的串联,在解码过程中,不同模态信息之间的对抗会导致有效信息的丢失。为此,设计了对比增强策略来提高解码器的特征集成能力,通过融合单模态信息和场景共同信息,获得对比图像,我们计算对比图像与源图像之间的对比增强损失。在对比增强损失的引导下,解码器被约束同时保留两种模态的信息。设计消融实验以验证对比增强策略的有效性,实验结果如图 11 所示,没有对比增强损失的约束时,消融结果的红外信息受到可见光信息的干扰。相比之下,我们的结果可以完全保留两种模态的有效信息。

图11. 对比增强损失的消融实验结果。
3.3 对比实验与分析
为全面展示 D3Fuse 的性能,我们将其与九种先进方法进行了定性和定量比较,这些方法包括:ADF 、FPDE 、TSIFVS 、Densefuse 、SwinFusion 、IFCNN 、FusionGAN 、MgAN-Fuse 和 GANMcC 。作为我们方法的训练数据,首先使用 TNO 数据集测试所有方法的性能。为验证 D3Fuse 的泛化能力,我们还选择 RoadScene 和 M3FD 数据集作为测试数据,对所有融合方法进行比较。
3.3.1 TNO 数据集对比实验
我们在 TNO 数据集上对我们的方法与九种现有方法进行了评估,结果如图 12 所示。

图12. D3Fuse与9种先进算法在TNO数据集的两个场景上的结果对比。为清晰比较,每个场景中选取了一个背景区域(绿色框)和一个目标区域(红色框)。(关于图注中颜色引用的解释,读者可参考本文的网络版本。)
选择两个场景进行定性分析,以说明 D3Fuse 的优越性。为了更清晰的视觉比较,在每个场景中选择了一个背景区域(绿色框)和一个目标区域(红色框)。在场景 1 中,对比方法表现出场景细节的丢失,尤其是在标牌处,而我们的方法保留了完整的场景纹理。此外,ADF、FPDE 和 Densefuse 降低了红外目标的像素强度。在场景 2 中,Densefuse、FusionGAN 和 GANMcC 在树枝处表现出较差的纹理,SwinFusion 和 IFCNN 的背景表现不佳,例如场景左下角的灌木丛被错误的红外信息干扰。此外,ADF、FPED 和 Densefuse 的目标区域受到可见光的干扰。我们的方法有效地保留了背景纹理并清晰地呈现了红外目标。D3Fuse 的有效性源于场景共同特征的提取和专用 CFEM 从源图像中提取交集内容,增强了场景的清晰度和准确性。
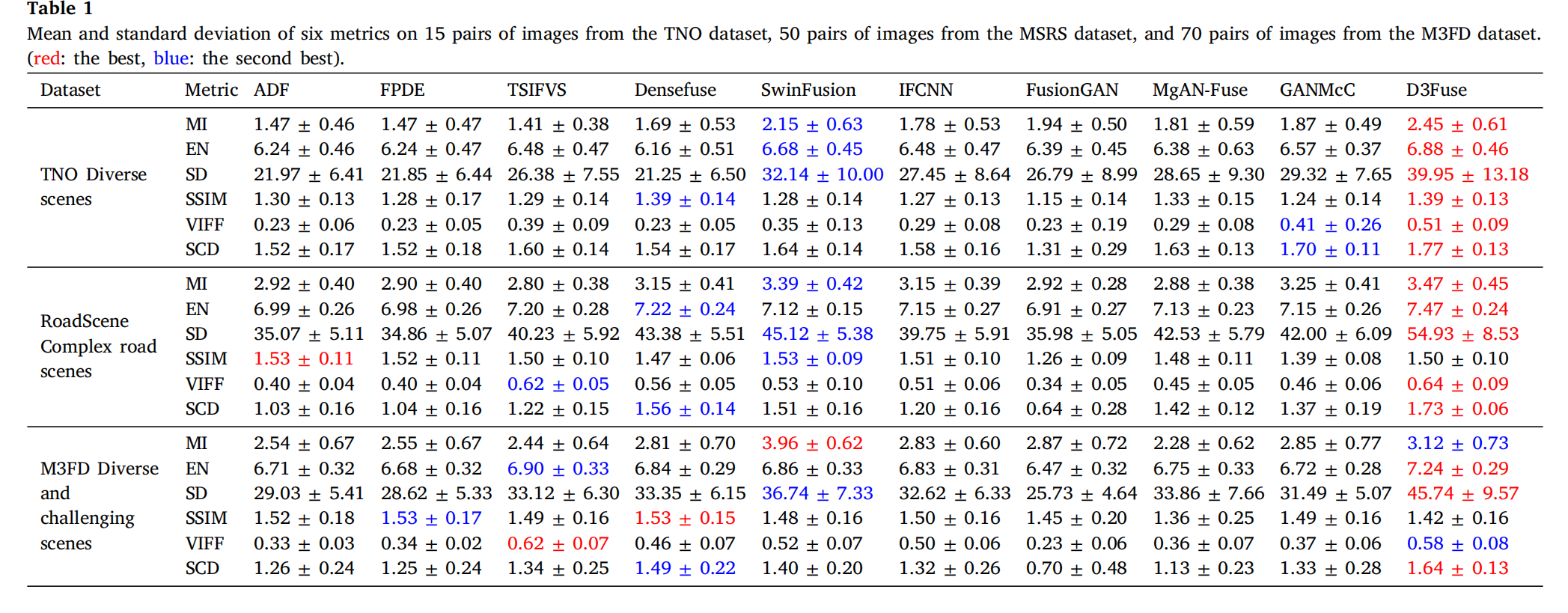
表1 TNO数据集15对图像、MSRS数据集50对图像和M3FD数据集70对图像的六个指标的平均值和标准差。(红色:最佳,蓝色:次佳)。
表 1 展示了 TNO 数据集上不同场景的定量结果,突出显示了 D3Fuse 在所有指标上的优势。MI 和 EN 的优异表现表明我们的方法能够保留模态特征和有价值的信息。最高的 SD 分数表明我们的融合图像具有最佳的对比度和视觉质量。SSIM 证实了 D3Fuse 在保留结构细节方面的优越性。最高的 SCD 分数进一步证实了 D3Fuse 最大化不同信息类型互补性的能力。
3.3.2 RoadScene 数据集对比实验
我们在具有复杂交通场景的 RoadScene 数据集上对我们的方法与九种现有方法进行了比较,以评估我们方法的泛化能力。定性结果如图 13 所示。

图13. D3Fuse与9种先进算法在RoadScene数据集的两个场景上的结果对比。为清晰比较,每个场景中选取了一个背景区域(绿色框)和一个目标区域(红色框)。(关于图注中颜色引用的解释,读者可参考本文的网络版本。)
在场景 1 中,只有 D3Fuse 和 SwinFusion 保留了完整的场景细节,而其他方法表现出不同程度的失真,包括墙上的文字模糊或扭曲。在场景 2 中,ADF 和 FPDE 丢失了文字细节,TSIFVS、Densefuse、FusionGAN 和 GANMcC 由于冗余的红外信息而使其可见背景受到干扰。我们的方法之所以优越,是因为三维特征融合策略丰富了编码信息,并引入了对比学习策略来扩展特征空间,从而更好地适应信息更丰富的成像场景。
表 1 呈现了复杂道路场景下 RoadScene 数据集的定量结果。我们将我们的方法与其他方法在 MI、EN、SD、SSIM、VIFF 和 SCD 方面进行了比较。D3Fuse 在 MI、EN、SD、VIFF 和 SCD 上表现出明显优势,展示了其在保留有效信息和场景表示方面的优越性。在 SSIM 上,我们的方法略落后于 ADF、FPDE、SwinFusion 和 IFCNN,但仍保持中等以上的性能,表明在泛化方面结构信息保留水平中等。
3.3.3 M3FD 数据集对比实验
我们在具有挑战性和多样化环境的 M3FD 数据集上对我们的方法与九种现有方法进行了评估,以验证其泛化能力。定性结果如图 14 所示。在场景 1 中,强光条件使传统方法和大多数深度学习方法的背景细节模糊。在场景 2 中,我们的方法保留了真实的场景表示,而其他方法受到红外信息冗余的影响,导致路灯细节模糊。

图14. D3Fuse与9种先进算法在M3FD数据集的两个场景上的结果对比。为清晰比较,每个场景中选取了一个背景区域(绿色框)和一个目标区域(红色框)。(关于图注中颜色引用的解释,读者可参考本文的网络版本。)
表 1 展示了多样化和挑战性场景下 M3FD 数据集的定量结果。我们在 EN、SD 和 SCD 上领先,仅在 MI 上仅次于 SwinFusion,在 VIFF 上仅次于 TSIFVS,但在 SSIM 上落后。TNO 数据集在分辨率和场景方面较为简单,仅提供 35 对图像用于训练,这限制了我们的模型在内容更丰富、分辨率更高的 M3FD 数据集上保留结构信息的泛化能力。尽管如此,我们的 M3FD 融合结果表现出优越的视觉性能和模态信息,根据主观比较和其他指标,总体优于其他方法。
3.4 目标检测实验
为了更好地说明红外和可见光融合图像在高级视觉任务中的有效性,我们进行了基于目标检测的对比实验。将源图像和融合图像分别输入预训练的 YOLOv5 模型进行关键目标检测,比较结果如图 15 所示。

图15. D3Fuse与9种先进算法在三个场景上的目标检测结果。不同检测到的目标用不同颜色的框标记,框上方的数字表示置信度。
场景 1 来自 TNO 数据集,场景 2 来自 RoadScene 数据集,场景 3 来自 M3FD 数据集。在场景 1 中,所有融合结果都有效识别了红外目标,但只有我们的融合结果包含 “汽车” 标签。场景 2 包括三辆自行车,只有 FPDE、SwinFusion 和 D3Fuse 正确识别了它们。场景 3 中有三个人,只有 IFCNN 和 D3Fuse 完全识别了他们。由于场景失真,还存在误识别的情况,例如 SwinFusion 在场景 2 中将行人误识别为 “手提包”,FusionGAN 将树木误识别为 “猫”,MgAN-Fuse 在场景 3 中将汽车误识别为 “卡车”。总之,对比结果在目标检测中表现不佳,原因是有效信息的丢失和场景失真。相比之下,我们的融合结果保留了完整的背景信息并有效地呈现了红外目标,更好地满足了高级视觉任务的语义要求。
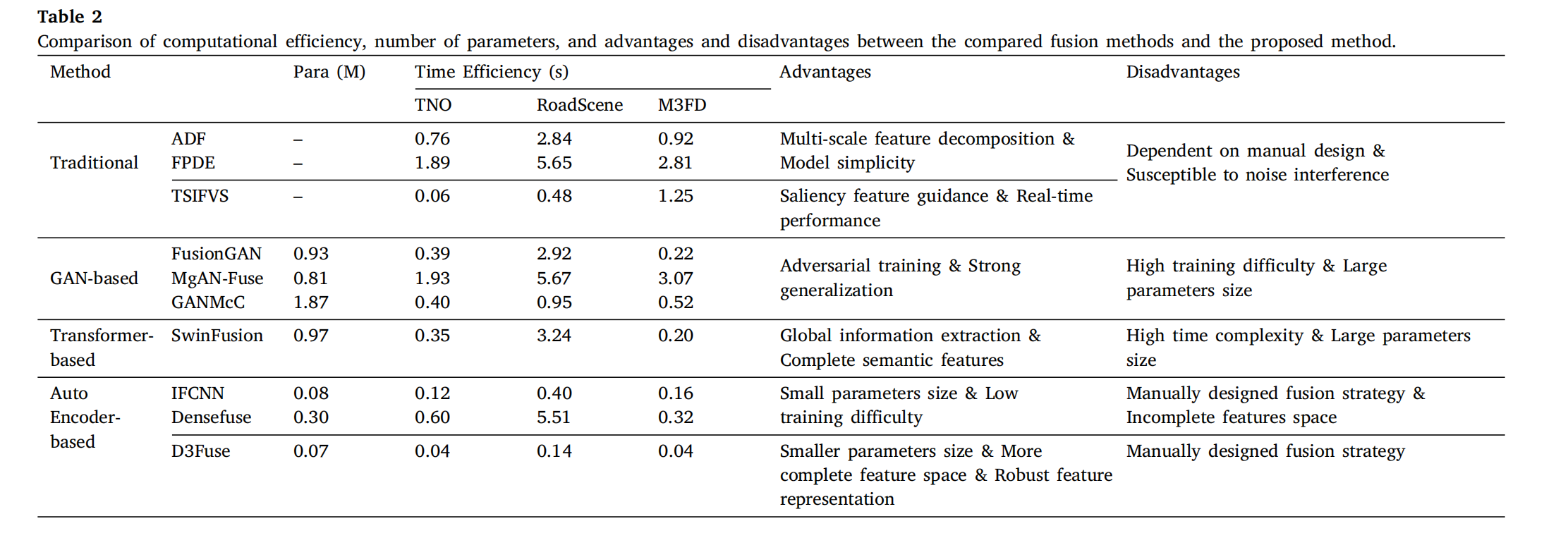
3.4.1 计算复杂度分析
我们总结了对比方法和 D3Fuse 的参数数量(para)、计算效率以及优缺点,这些比较列于表 2 中。我们的方法显示出更少的参数数量,优于对比方法。此外,我们测量了三个数据集(TNO、RoadScene、M3FD)上的单位融合时间,以评估融合效率。总体而言,我们的方法排名最高,展示了卓越的推理速度。与其他方法相比,D3Fuse 具有更少的参数、更完整的特征空间和鲁棒的特征表示,非常适合实际应用。
4. 结论
在本文中,我们提出了 D3Fuse,一种基于三维特征融合策略的新型红外和可见光图像融合方法。受人类主观场景匹配的启发,我们整合了场景共同特征以增强场景的可见性,这是通过专用的共同特征提取模块(CFEM)实现的,该模块通过深度集成空间和通道维度的信息来提取源图像中的重叠内容。为了增强特征独立性和编码器的信息感知能力,我们使用了基于多尺度 PCA 编码的对比学习策略。采用对比增强策略来提高解码器在融合过程中保留有效信息的能力。消融研究证实了我们的方法在特征提取、场景还原和信息保留方面的有效性。与九种先进方法的对比实验证明了我们方法的优越性。目标检测实验验证了我们的融合图像对高级视觉任务的适用性。
实际应用前景:D3Fuse 在实际应用中具有广阔前景。其优越的融合结果提供了更清晰的目标表示,这对于安全应用中的准确跟踪和识别至关重要。在医学成像中,D3Fuse 可以将红外组织温度数据与可见解剖细节相结合,提供全面的诊断信息,有助于早期疾病检测和表征。对于自动驾驶车辆,D3Fuse 可以增强环境感知能力,改善障碍物检测和场景理解,以实现更安全的导航和决策。
局限性和未来工作:我们的方法仍有很大的改进空间。消融研究表明,尽管 CFEM 在对比学习策略下专注于重叠信息,但提取的场景共同特征图仍包含一些模态信息。一个潜在的解决方案是使用具有更强约束能力的判别器来引导编码器提取更纯净的场景共同信息。未来的工作将侧重于简化场景共同特征并将其应用于其他多模态图像融合任务。此外,我们还期望基于语义驱动方法考虑进一步的研究方向。在后续工作中,我们将进一步探索高级视觉任务与融合任务之间的相互促进,构建多任务学习框架,增强融合图像的语义信息,提高融合图像的质量和实用性。

















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









