









x,y 坐标除以宽高
目的是为了满足cnn的尺度不变性,便于进行参数的学习。边框回归学习的是回归函数,然而你的目标却不满足函数定义,当然学习不到什么。
宽高坐标Log形式
我们想要得到一个放缩的尺度,也就是说这里限制尺度必须大于0。我们学习的tw,thtw,th怎么保证满足大于0呢?直观的想法就是EXP函数,如公式(3), (4)所示,那么反过来推导就是Log函数的来源了。
为什么IoU较大,认为是线性变换?
当输入的 Proposal 与 Ground Truth 相差较小时(RCNN 设置的是 IoU>0.6), 可以认为这种变换是一种线性变换, 那么我们就可以用线性回归来建模对窗口进行微调, 否则会导致训练的回归模型不 work(当 Proposal跟 GT 离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理)。这里我来解释:
Log函数明显不满足线性函数,但是为什么当Proposal 和Ground Truth相差较小的时候,就可以认为是一种线性变换呢?大家还记得这个公式不?参看高数1。
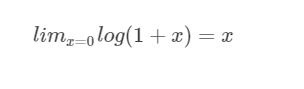
现在回过来看公式(8):
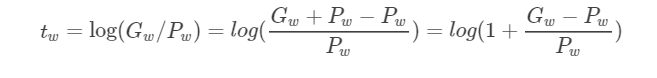
当且仅当Gw−Pw=0的时候,才会是线性函数,也就是宽度和高度必须近似相等。
对于IoU大于指定值这块,我并不认同作者的说法。我个人理解,只保证Region Proposal和Ground Truth的宽高相差不多就能满足回归条件。
参考:
https://blog.csdn.net/zijin0802034/article/details/77685438/















 1473
1473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









