






所谓“幻觉”,指的是人工智能模型生成的内容,不是基于任何现实世界的数据,而是大模型自己想象的产物。例如,面对用户的提问,ChatGPT以及谷歌的Bard等工具会杜撰出一些看上去像是权威正确的虚假信息。这些虚假信息以文本、图像、音频、视频等形式存在,创造出不存在的书籍和研究报告,假的学术论文,假的法律援引等。
大模型的遗忘问题,也被称为灾难性遗忘,主要指的是神经网络在学习新任务的过程中,会忘记之前学习过的任务。
在大语言模型的应用过程中,微调和对齐是至关重要的步骤,它们确保模型不仅能理解和生成人类语言,还能在执行任务时表现出与人类价值观相符的行为。模型微调是将预训练的语言模型应用于特定任务的关键过程。通过微调,可以将在广泛语料上学到的通用语言表示调整为更适合特定任务的需求。这一步骤是实现高性能应用的决定性因素。在微调过程中,预训练模型在特定任务的数据集上进行额外训练。大模型通过以下步骤能极大程度上缓解大模型的遗忘和幻觉问题:
1.指令微调
指令微调是指在预训练的大语言模型上施加额外的训练步骤,使其更好地理解和执行特定的指令。这一过程涉及到对模型进行再训练,以适应具体的任务需求,如回答问题、撰写文章或生成代码等。
2.InContentLearning
In-Content Learning是一种更深层次的模型训练方法,通过让模型在处理内容时进行实时学习,以增强其对特定内容的理解能力。In-Content Learning的关键在于模型能够利用当前正在处理的内容来调整其行为。这通常涉及到以下几点:
(1)上下文感知模型通过分析当前的任务和可用的数据环境,实时调整其预测策略。
(2)动态适应:模型在处理类似内容时,能够记住以前的处理结果和学习经验,实现动态适应和优化。
3.PROMPT技术
PROMPT技术(Prompt-based Learning)是近年来在自然语言处理领域快速发展的一种新兴技术。它通过在输入给模型的数据中加入特定的提示(prompts),以引导模型生成预期的输出。这种方法尤其适用于那些已经经过广泛预训练的大型语言模型,如GPT系列和BERT系列。
PROMPT技术的核心思想是,通过精心设计的提示语句,激活模型中的相关知识,使其在特定任务上表现更佳。这些提示可以是一系列预设的问题、任务特定的关键词或者是特定格式的指令。
(1)模板填充:在这种方法中,预定义的模板(如“填空题”格式)用来激发模型在给定上下文中填充合适的信息。
(2)手工提示与自动提示:提示可以手工设计,也可以通过算法自动生成。自动生成的提示通过优化过程适应特定的任务需求。
4. RAG 技术
(1)检索增强生成(RAG)
这一技术旨在通过信息检索系统从外部知识库中获取相关信息,容纳广泛的最新和长尾知识,为大语言模型提供时效性强、领域相关的外部知识,以提升大语言模型生成内容中的准确性和丰富度,从而生成更加可靠的回复。其逻辑是针对用户的问题先进行数据库查找以找到和问题相关的文档,然后再使用大模型基于相关文档生成相应的回答。该机制能最大程度缓解大模型的幻觉问题,同时也能较容易地将用户的私有数据进行导入,避免在大模型上进行语料增量训练,减少使用成本。此外对于用户的异变数据或者动态数据也能较快进行适应,避免在用户的数据进行修改后整体模型进行微调和重训练,难以合理地对新知识学习和旧知识遗忘之间进行平衡,使得模型整体效果受到动态数据的影响,甚至有的动态数据变化太快以致于不能在有效的时效范围内对数据集进行训练和微调,在这种情况下只能使用检索增强的开卷考试的方法进行知识的输出。
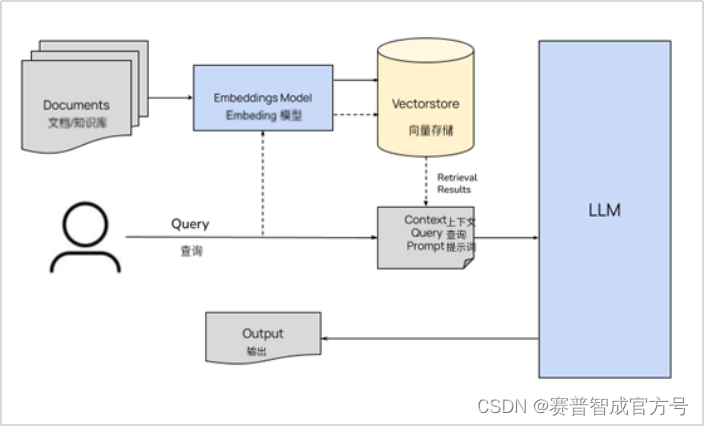
(2)向量数据库
向量知识库是一种采用向量空间模型来存储和管理知识的数据库。在这种知识库中,每个知识项(如文档、事实、概念等)都被转化为一个向量,这些向量在多维空间中的位置能够反映出各个知识项之间的相似度和关联性。通过向量化,知识库可以更加高效地进行语义搜索、相似度比较和模式识别等操作。向量知识库背后的核心技术通常包括自然语言处理(NLP)、机器学习(ML)以及深度学习(DL),这些技术能够帮助解析和理解存储在知识库中的复杂信息。向量知识库的应用场景极其广泛,从智能问答系统、推荐系统到自然语言理解和机器翻译等,都可以看到其身影。
在构建和查询向量知识库时,常见的算法包括但不限于词嵌入(Word Embeddings)、句子嵌入(Sentence Embeddings)、以及深度学习模型如BERT和GPT系列。这些算法能够将文本转化为高维空间中的向量表示。为了加速向量的检索和匹配过程,通常会采用一些近似最近邻(Approximate Nearest Neighbor, ANN)算法,如Faiss、Annoy、HNSW等。这些算法通过构建特定的索引结构,能够在巨大的向量集合中快速找到最相似的项,大幅度提高查询的效率,同时保持较高的准确率。
RAG(Retrieval-Augmented Generation)是一种结合了检索和生成的自然语言处理技术。在RAG模型中,向量知识库的优势尤为明显。它能够通过向量化的知识库快速检索到相关的背景信息或事实,然后将这些信息融入到生成过程中,以生成更加丰富、准确和相关的文本。这种方法不仅提高了文本生成的质量,也扩展了模型处理复杂问题的能力。向量知识库在RAG模型中的应用,极大地提升了信息检索的速度和质量,使得生成的内容更加贴近真实世界的知识,为提升机器理解和生成能力开辟了新的路径。















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









