







JUST读论文 大模型相关
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
哈哈,标题党了一把,每天都能在公众号上看到什么什么模型被打败的这种文章,AI圈变得像娱乐圈一样通过拉踩来蹭热度了。
这里将更新一些关于大语言模型的发展论文阅读,感觉像是翻译,但其实是我的阅读笔记,读的时候挖的比较深,看的时候就会提出问题,必要的时候会查看附录和源码。
看论文的顺序是按照吴恩达大师推荐的顺序:标题 abstract figure intro conclusion …
一、DS-Agent: Automated Data Science by Empowering Large Language Models with Case-Based Reasoning 2024
吉林大学、上海交通大学和伦敦大学学院汪军团队合作提出了的DS-Agent
代码:https://github.com/guosyjlu/DS-Agent
文章链接:https://arxiv.org/abs/2402.17453
本文调研了基于大语言模型agent在自动完成数据科学任务上的潜能,首先agent需要理解任务要求,然后创建和训练最佳拟合的机器学习模型。尽管现有LLM agent获得了广泛的成功,但是在数据科学任务上由于生成不合理的实验计划而受挫。因此,本文提出DS-Agent,一个将大语言模型智能体和基于案例推理(CBR)连接在一起的新奇自动框架。在开发阶段,DS-Agent沿着CBR框架(框架,前任工作)构建自动迭代流水线*(后面会详细介绍)*,这样能够灵活地利用来自Kaggle的专家知识(数据),并通过反馈机制促进连续的性能优化。而且,DS-Agent用简化的CBR范式实施了低资源部署,能够重现开发阶段的成功解决方案,从而直接生成代码,显著减少了对大模型基本能力的要求。实验来看,DS-Agent结合GPT-4在开发阶段实现了史无前例的100%成功率。并在部署阶段替换模型中获得平均one pass分数36%的增益。在开发和部署阶段,都在性能上达到了最高分数,分别在GPT4上单次调用开销为$1.6和$0.13.
intro
第一段就是说大模型基本能力使自动语言agent在很多任务上都有效解决了,本文则关注自动进行数据科学任务,旨在最小化人们进行数据科学时需要的具备专业知识。
第二段**当前困境:**尽管LLM Agents获得了广泛的成功,有工作声明现存agents,包括AutoGPT(2023),LangChain(2022),以及SOTA ResearchAgent(2023),都难以在数据科学任务上获得高的任务分数,尽管已经加持了最有力的GPT4。这是由于大语言模型生成推理计划的缺陷以及幻觉问题。为了环节这个问题,就是进一步微调对齐有监督数据科学场景。然而,收集数据集很难,特别是自动数据科学的反馈需要先完成代码执行。特别是LLM有数十亿参数,微调时的反向传播和优化将消耗大量计算资源。
在这个背景下,Kaggle成为重要的资源。作为世界上最大的数据科学竞赛平台,它有大量专业报告和代码。为了使大模型使用这些专家知识,采用AI问题解决范式——CBR(casebased reasoning)。CBR通过检索过去相似的问题,将其解决方案复用于当前的问题,评估有效性并修改方案,再次评估修改,最后将新解决方案保存。使用CBR能够使LLM agent分析、提取和复用人类专家的知识,并基于执行效果迭代修正解决方案获得性能的持续增长。将CBR整合到大语言智能体不仅提高了它们在数据科学任务上的问题解决能力,也高效使用了样本资源和计算资源。
本文提出DS-Agent,使用大语言模型智能体和CBR的全新框架,以实现以模型为中心的自动数据科学。如下图可以看到有两个阶段:标准开发阶段和低资源部署阶段。在开发阶段,DS-Agent构建在CBR框架之上来使用Kaggle上的专家知识,构建自动迭代流水线。当给定一个新任务,DS-Agent检索并复用Kaggele上的相关专家知识并开发一个实验计划,随后迭代采用检索到的案例并根据执行反馈修改实验计划。得益于CBR框架,DS-Agent能够Kaggle的专家知识,并通过保存成功解决方案到case bank提供灵活的学习机制,而不是通过反向传播更新(资源密集型)参数。而且,CBR的反馈机制使DS-Agent迭代检索有用的案例,并修改实验计划,实现可持续增长,如下图b。(注意这个rank应该是排名类指标)
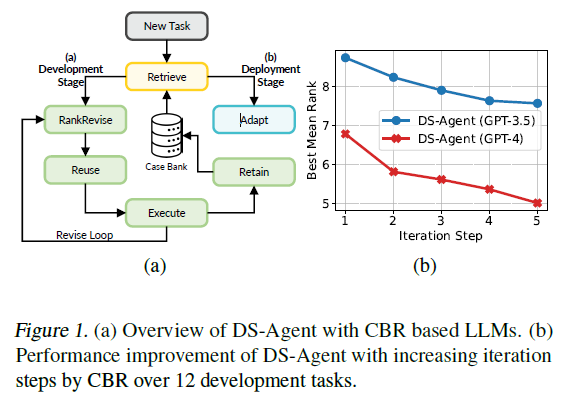
在部署阶段,DS-Agent采用简化的CBR框架应对低资源场景,将直接根据用户的任务需求进行代码生成而不再迭代修改。DS-Agent检索复用过去的成功解决方案,因此用于解决未见过的在同一任务分布下的任务。有了相似的解决案例,DS-Agent只需要进行较小的修改,因此大大减少对大语言模型基础能力的要求。
本文在两个阶段共讨论了30个数据科学任务以体现DS-Agent的卓越性。在开发阶段,DS-Agent+GPT4在12个任务上达到了空前100%的成功。在部署阶段,DS+GPT3.5/GPT4分别在18个部署任务上达到了85%和99%的一次通过率。值得注意的是,DS-Agent将开源大语言模型Mixtral-8x7b-Instruct的一次通过率从6%提升到了31%。在两个阶段DS-Agent和GPT4/3.5都是第一第二的排名。DS-Agent将标准场景下的调用每次$ 0.06/GPT3.5 $1.6/GPT4 ,进一步减少为$0.0045和$0.135 在低资源场景下,使得DS-Agent便于在现实世界部署。
Preliminary 前置知识
基于CBR的大语言模型
CBR(1992 1994)是经典的AI范式,通过检索相似问题,复用解决方案、评估有效性,迭代修改解决方案来解决新问题。有最好评估性能的解决方案保存在数据库中用于未来使用。本文将CBR框架和大语言模型整合在一起来提高问题解决能力。如下图b,基于CBR的大语言模型由三个组件构成:1. 检索器 p R pR pR根据任务 τ \tau τ和反馈 l l l返回数据库分布 2. 一个大语言模型 p L L M p_{LLM} pLLM根据任务 t t t,反馈 l l l和检索到的案例 c c c生成解决方案 y y y 3.一个评估器 p E p_{E} pE 生成对解决方案 y y y的反馈 l l l
每次迭代的公式如下:就是对上一个解决方案下的反馈,再次获得相关的
解释一下:每次迭代基于上一次的反馈和这一次检索到的所有的案例进行计算,并生成特定案例下的最后的方案。随后这些最后的方案构成第 t t t次解决方案,CBR运行后由评估器给出反馈信号。
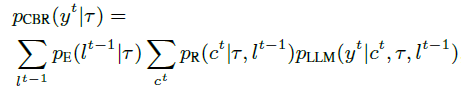
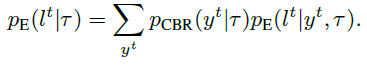
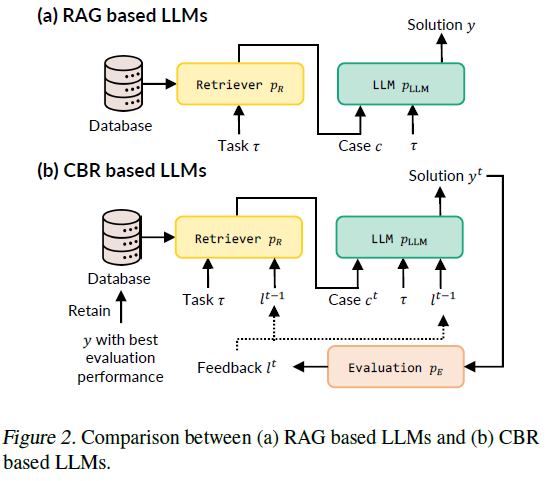
RAG VS. CBR (RAG Retrieval-Augmented Generation.)
CBR和RAG展现出很大的相似性,两者都包含检索和复用。如上图a,RAG仅包含检索器和大预言模型
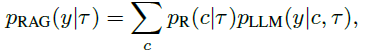
可以直观看出尽管两者都能检索和复用,但是CBR额外调整检索到的案例并基于评估反馈修改解决方案。更多地,保存解决方案使得CBR实现灵活的学习机制,因此获得连续的性能提升。
真正的结构看这个会比较清楚:
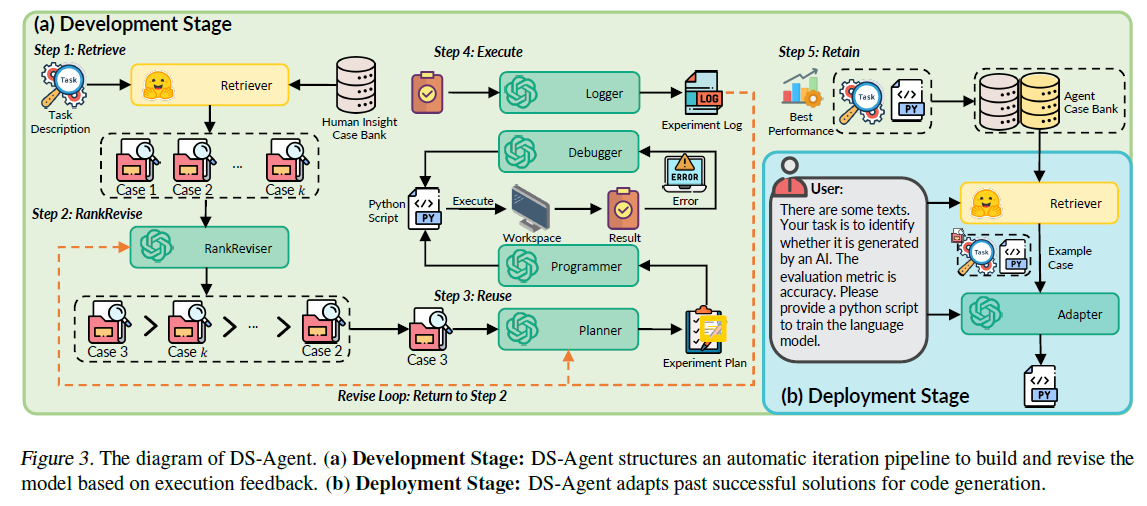
conclusion
本文提出了DS-Agent,将大语言模型智能体和CBR连接在一起解决数据科学任务。在开发阶段,DS-Agent基于CBR构建自动迭代流水线,旨在检索和复用Kaggle的相关专家知识来开发实验计划,并且根据反馈迭代调整检索到的案例并修改计划。部署阶段,DS-Agent使用简化的CBR框架以应对低资源场景,通过检索和复用开发阶段积累的成功案例。大量实验证明了DS-Agent在数据科学任务上的有效性。
Related Work
LLM Agent
大预言模型表现出许多强大的基本能力,比如语言理解、复杂推理、工具使用和代码生成,这促使许多自动语言智能体被设计出来解决多种任务。在数据科学领域,有讨论大语言模型在数据科学工作流的潜力,最近也涌现出研究大预言模型智能体在特征工程、超参数调整、使用机器学习库、协助人工智能研究、数据操作等领域的应用。本文则关注构建和训练机器学习模型,开发自动数据科学领域的应用。
CBR 基于案例的推理
提出于几十年前的CBR是一种经典的AI框架,旨在利用相关案例分析和推理调整视角,从而解决问题。将CBR整合进LLM和RAG在步骤上有很大的相似性,特别是检索和复用。然而,CBR最显著的特征是它的反馈机制,即迭代修正案例排序并以此为根据修改方案。另外。CBR通过保存和复用成功案例提高未来解决问题的能力。
方法与架构
3. The DS-Agent
开发阶段的任务: τ d e v e l o p \tau_{develop} τdevelop
部署阶段的任务: τ d e p l o y \tau _{deploy} τdeploy
任务被描述为一个元素 ( τ , D t r a i n , D v a l i d , D t e s t , M ) (\tau ,D_{train},D_{valid},D_{test},M) (τ,Dtrain,Dvalid,Dtest,M)
在两个阶段,DS-Agent都需要理解任务描述 τ \tau τ,生成在训练数据集 D t r a i n D_{train} Dtrain上训练的机器学习模型代码,并使用评估指标$\mathcal{M} 在验证集 在验证集 在验证集D_{valid} 上评估性能,然后以在测试集 上评估性能,然后以在测试集 上评估性能,然后以在测试集D_{test}$上的表现为最终性能。
Development Stage: Automatic Iteration Pipeline开发阶段:自动迭代流水线
开发阶段,本文根据数据科学家通常执行数据任务的步骤构建DS-Agent的工作流,即构建、训练、验证。由于大模型不是天然针对数据科学训练的,缺乏先验知识生成设计机器学习模型合理的计划,因而性能不佳。而Kaggle有丰富的专业知识,通过将Kaggle的知识整合到大模型智能体,能够显著提升解决复杂科学任务的能力。因此,将CBR整合到自动迭代流水线中,
Human Insight Case Collection 专家案例收集
收集了近期完成的Kaggel比赛,以获得先进的机器学习技术,主要聚焦文本、时间序列和表格数据,爬取最高分团队的技术报告和代码。技术报告被清洗,代码则通过GPT3.5转变为文本描述,然后存储在案例银行中。
Step 1: Retrieve. 第一步:检索
DS-Agent从案例银行 C C C检索和当前任务相关的案例,检索器计算任务描述 τ \tau τ和案例 c ∈ C c\in C c∈C的cosine 相似度,即: s i m ( τ , c ) = c o s ( E ( τ ) , E ( c ) ) sim(\tau,c)=cos(E(\tau),E(c)) sim(τ,c)=cos(E(τ),E(c)),其中 E ( ⋅ ) E(·) E(⋅)是预训练的embedding model。随后选出前 k k k个最相似的案例。
Step 2: ReviseRank 第二步 重修案例排名
需要让检索器(Retriever)根据反馈动态更新案例的相似度排名(旨在从相关案例中选出更好用的),一种方式就是根据反馈微调检索器。但是,自动数据科学任务提出一个独特的挑战,就是需要运行代码才能获得反馈,这会消耗大量的时间和计算资源。为了解决这个问题,本文提出使用大语言模型的能力来估计检索出的案例的有效性,通过分析运行反馈,然后修正案例排名。
受某一工作 【Is ChatGPT good at search?】进行相关性排名的启发,将前 k k k个案例用相同的标识符作为prompt 格式,即 { c 1 , c 2 , . . . , c k } \{c_1,c_2,...,c_k\} {c1,c2,...,ck}—>[1], [2],etc,随后提示大语言模型根据对当前数据科学任务有效性的估计以及上一轮反馈生成这些案例的降序排列。排序结果为如:[2]>[1]>[3]。在每个迭代步骤 t t t,每个案例的有效性 p R R ( c ∣ τ , l t − 1 ) = p L L M ( c ∣ c 1 , c 2 , . . . c k , τ , l t − 1 ) p_{RR}(c|\tau,l^{t-1})=p_LLM(c|c_1,c_2,...c_k,\tau,l^{t-1}) pRR(c∣τ,lt−1)=pLLM(c∣c1,c2,...ck,τ,lt−1),最高分案例将被用于下一步
Step 3: Reuse 第三步 复用
DS-Agent使用planner复用检索到的案例构建实验计划。在迭代步骤 t t t,planner根据任务描述 τ \tau τ和先前的执行反馈 l t − 1 l^{t-1} lt−1来理解当前上下文。然后分析最高分案例 c t c^t ct,复用案例到当前任务,最终开发新的实验计划 y t y^t yt。
Step 4: Execute. 第四步 执行
随后,DS-Agent用python脚本执行实验计划,并生成反馈。其中Programmer浏览任务描述和实验计划来生成相应的python代码。生成代码后,执行脚本以观察输出。如果有bug,Debugger将辨别和解决bug。受Reflexion(Reflexion: Language agents with verbal reinforcement learning,2023)启发,Debugger首先根据执行反馈思考潜在bug,然后生成并重新执行正确的代码,这个过程循环之没有错误出现或者以及超过最大debug次数。最后Logger输出自然语言格式的实验过程的全面总结,保存该实验日志为DS-Agent提供了执行反馈,使得DS-Agent进一步修正实验计划从而设计更好的机器学习模型。
Step 5: Retain 第五步 保存
每次迭代完毕,使用训练好的机器学习模型在测试集上预测,如果性能改进了,就将任务描述和相应的python代码存入案例银行,人工案例银行( C C C)和智能体案例银行( B B B)。
Revise Loop: Return to Step 2. 修正循环:回到第二步
在保存之后,工作流回到重排序步骤。使得DS-Agent能进一步根据当前步 l t l^t lt的执行反馈修改实验计划。该修正循环会一直持续,直到达到最大迭代次数。
和前面的步骤一直,DS-Agent使用CBR框架迭代检索和复用相关有效的案例来修正实验计划,进而提高解决当前数据科学任务的能力。CBR框架的公式如下:
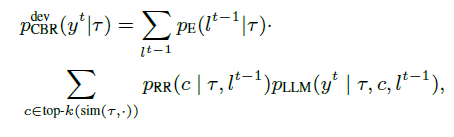
这里附录还提供了伪代码。总的来说CBR 给DS-Agent带来的好处有两个方面。首先,整合人类案例英航,使得DS-Agent能够产生合理的实验计划。而且,CBR通过保存成功案例至案例银行,这是一种灵活的学习机制,尤其是和微调大语言模型这种方式比起来。比如说,当模型遇到未曾见过的数据模态时,比如图表数据,能够简单和最新的人类案例银行结合起来就可以了。其次,使用反馈信号进行检索和修改实验计划。
Deployment Stage: Learning from Past Cases 部署阶段:从过去的案例中学习
DS-Agent先检索相关案例并复用。给定一个部署任务 τ \tau τ,DS-Agent先从智能体案例银行检索有相似任务描述的案例对 ( τ 0 , s 0 ) (\tau_0,s_0) (τ0,s0),即 ( τ 0 , s 0 ) = a r g m a x ( τ 0 , s 0 ) ∈ B s i m ( τ , τ 0 ) (\tau_0,s_0)=argmax_{(\tau_0,s_0)\in B}sim(\tau,\tau_0) (τ0,s0)=argmax(τ0,s0)∈Bsim(τ,τ0).( s 0 s_0 s0应该是代码)。随后DS-Agent使用调整器(Adapter)复用检索到的案例对并适应性地解决当前任务,生成训练机器学习模型的代码。简化的CBR框架公式为:
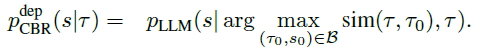
通过给出一个相似的解决方案,DS-Agent能顾快速解决同一任务分布下新的任务,大大减少了对模型推理和编码能力的要求。
experiment
Experiment Setting 实验设置
Task Selection 任务选择
三个模态(文本、时间序列喝表格)下的30个数据科学任务,其实是回归和分类两个基本任务。实验中的数据集是是多种多样的,评估指标也是多种多样的。在30个任务中,12个用于部署,其余开发。每个数据集,作者体哦那个自然语言任务描述,并将它们分为训练集、验证集和测试集。并且,作者提供初始随即猜测Python脚本作为Baseline,也作为初始化脚本。
Evaluation Metric 评估指标
主要从三个方面评估智能体能力:
- 构建机器学习模型的完成情况。开发阶段:能否在给定步数情况下完整构建机器学习模型。部署阶段:能否一次通过。
- 构建的机器学习性能。两个阶段都使用平均排名和最佳排名作为评估指标。
- 资源消耗。花费的金额。
Results for Development Stage 开发阶段的结果
MAIN RESULTS 主要结果
Baselines: 在开发阶段,进行DS-Agent和ResearchAgent(解决机器学习相关任务的SOTA 2023)的对比学习,两个智能体都在GT3.5/4上进行。
**成功比例的对比:**首先在开发阶段分布两个智能体在6个不同类型数据科学任务上的成功率。如下图,DS-Agent with GPT-4 实现最高成功率为100%,特别是DS-Agent with GPT-3.5在所有任务上超过了ResearchAgent with GPT-4。证明了有效性。并且ResearchAgent with GPT-3.5几乎在所有类型的任务上都失败了,可能是因为它需要模型具备很强的推理和编码能力。而在所有类型的任务中,表格数据的任务完成的最好,这可能是因为表格任务通常只需要简单调用sklearn的函数,相对而言,不那么需要模型的推理和编码能力。
**特定任务的对比:**如下图在12个开发任务上,DS-Agent with GPT-4在其中九个上都是最高排名,DS-Agent with GPT-3.5则在平均排名和最高排名上都表现第二好,在大多数任务上超过了ResearchAgent with GPT-4。

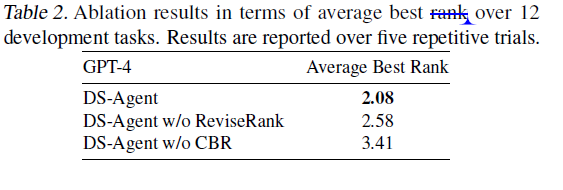
消融实验
为了验证CBR在开发阶段的有效性,进行两个消融实验。
首先,研究没有重排位,而是直接使用高得分(最高相似度)的案例,即不根据反馈型号调整案例顺序,可以简单视为RAG LLM agent。如预期,性能下降,证明根据反馈重排位案例顺序是有效的。
其次,评估没有CBR的情况,没有人类案例而直接prompt 大模型。这个变体产生了最坏的性能,因为大语言模型没有被训练对齐数据科学场景,因此不能自动形成合理的实验计划。将CBR整合进来成功解决了这一限制,是LLM能够吸收Kaggle的专家知识来解决数据科学任务。
Results for Deployment Stage 部署阶段的结果
主要结果
**Baseline:**有两个,,一个是0样本直接prompt LLM去生成代码,另一个是从智能体案例银行中随机选择一个案例作为上下文prompt LLM。这也可以视为对检索过程的消融学习(检验检索器的有效性)。所有的智能体都在GPT3.5/4和开源模型Mixtral-8x7b-Instruct(Mixtral of experts.,2024)上进行。
**一次通过率对比:**如下图,研究9个智能体在6种不同类型部署任务上的成功率。DS-Agent表现出卓越性,尤其是DS-Agent with GPT-4,几乎接近100%的成功率。特别是,DS-Agent with GPT-3.5是85%的成功率,位于第二。而DS-Agent with Mixtral-8x7b-Instruct 则为开源模型带来25%的增幅。(一个prompt就增幅很多哎,感觉多几个随机的样例,进步应该也会很明显)。以上结果进一步说明了CBR能够提高模型生成无Bug代码的能力。可以看出提供一个样例能给模型带来能力增幅,然而GPT3.5却是例外,可能由于它相对较差的推理性能。另外DS-Agent超过1-shot,进一步说明检索器的有用性。

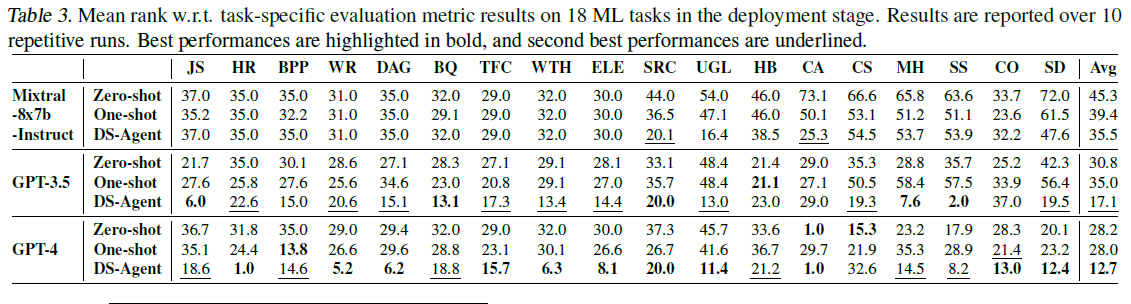
**特定任务对比:**如下表,DS-Agent with GPT-4在九个智能体种达到最高平均排名,DS-Agent with GPT-3.5则稳坐第二,甚至超过bseline+GPT-4.然而,DS-Agent with 开源模型性能仍旧差于GPT3.5/4,由于其相对而言较差的基本大语言模型能力,但是加入了DS-Agent后性能还是优于0-shot和1-shot。
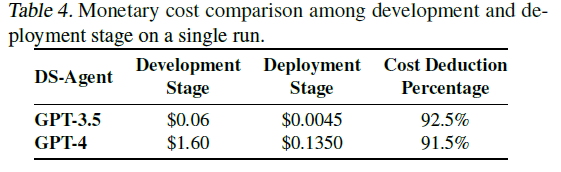
**资源消耗对比:**DS-Agent的关键设计在于两个不同的阶段。开发阶段关注探索有效模型设计,需要相对较高的资源消耗,部署阶段要求用少量资源快速有效地解决数据科学任务。如下表,部署阶段于开发阶段相比,减少了超过90%的开销。
消融实验
开发阶段,DS-Agent调整过去成功的案例来解决新的数据科学任务,一种想法是将开发阶段的文本的人类知识直接进大语言模型上下文来提高数据科学能力。因此研究DS-Agent的变体,学习相关的文本的人类知识进行代码生成,即从kaggle人类专家数据银行检索案例而非智能体案例银行种检索案例。这表明,从同质案例(即示例任务及其解决方案之一)中学习比从异质案例(即文本解决方案见解)中学习性能更好。
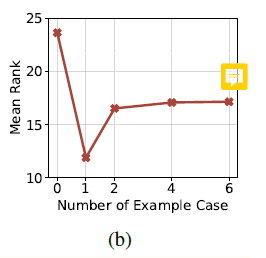
选中案例数量的超参数
没有案例0-shot最差,看到随着样例增加,有一个明显降幅,即从一个案例到两个案例时,这是因为需要调整单个样例以适应当前任务,因此,当超过一个样例时,引入了更多干扰信息,阻碍了生成当前任务所需代码的能力。
总结
本文也是一种大模型的检索增强技术,大模型能够自动不断调整生成的答案,最后实现结果(感觉可以再给一个强化信号,引导大模型生成内容往这个地方走,比如推理时间减少、降低模型大小等等)
除了通过















 41
41











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









