






【消除多模态模态学习不均衡的问题】 Enhancing Multimodal Cooperation via Sample-level Modality Valuation 通过样本级模态评估提高多模态协作
文章目录
前言
本文主要是改善多模态学习中单一模态偏向学习的问题。
提出了一个数据集水平上无差异的数据集,提出了一个模态贡献指标,并根据这个指标重采样,改善低贡献模态学习,使得模态学习均衡。
本文阅读顺序还是 标题 abstract figure intro conclusion …,希望大家快速甄别信息,提高阅读和筛选效率,本文没有解读公式,主要是难敲。(主要也是为了记录自己的阅读过程)
另外感谢批评,还请大家多多交流。
abstract
多模态学习的一个最初的观点是联合学习不同模态的同质信息。然而,大多数模型常常无法很好地进行多模态写作,不能很好地联合使用所有模态。有人提出了一些方法来识别和增强学习较差的模态,但它们往往难以在样本水平上提供对多模态合作的细粒度观察和理论支持。因此,合理观察和改进模态间的细粒度协作至关重要,特别是现实世界中不同样本间的模态差异千奇百怪。本文提出了样本水平上的模态评估指标来评估每个模态对每个样本的贡献。通过模态评估,我们发现模态差异在样本水平上确实不同,超过了数据集水平的全局贡献差异。我们进一步分析这个问题,并以有针对性的方式增强低贡献模态的辨别能力,使得样本水平上的不同模态之间加强合作。总的来说,我们的方法合理观测了细粒度的联合模态贡献并实现了相当的改进。
Discussion
本文提出了样本水平的模态评估指标,借助博弈论理论观察单一模态的贡献程度。两个方法用于恢复低贡献率的模态贡献,改进多模态合作。
- 不同模态的天然差异。比如,对于声音-视觉样本——画画来说,视觉比声音更易辨别,因此本文方法能够恢复低贡献模态的贡献率,但不能单一模态的贡献率相等。因此,在改进多模态协作时需要考虑这种天然差异。
- 多模态大语言模型的不平衡贡献。GPT4V很容易被文本模态误导。
intro
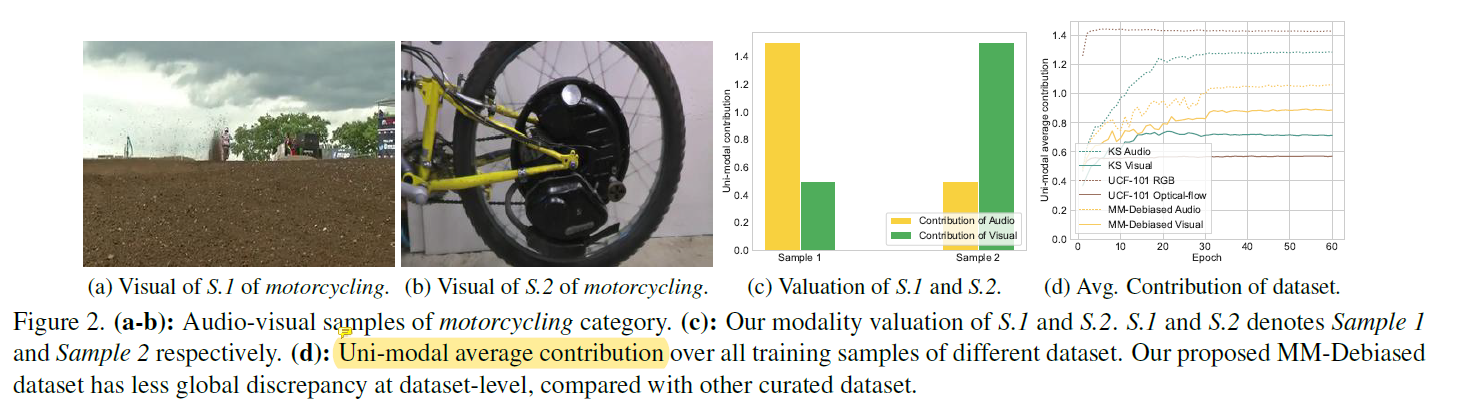
现在大多数模型都有不平衡多模态学习问题,使得多模态协作能力不强。并且由于模型缺乏可解释性,因此无法观察每个模态在最终预测中的作用,以及如何据此促进单一模态训练。一些方法用于分辨并改进没有很好地学习到的模态,这些方法通常使用输出的logits[1]或者梯度规模[2]。然而这些经验性策略只考虑数据集水平上的全局模态差异,并且只在当前常用数据集上改进性能(比如Kinetics Sounds dataset)。现实中,不同样本的模态差异巨大,如下图a和b,样本1中的很难看到摩托车(a),而样本2的摩托车却很清晰(b),这使得声音和视觉两个模态总有一个贡献更多。这种细粒度的模态差异难以用现有手段区分。因此,如何在样本水平上合理观察并改进多模态合作这个问题需要解决。
本文提出样本水平模态评估指标,来观察样本预测时每个模态的贡献率。博弈论中的沙普利价值[3]根据参与者贡献分配收益,为本文评估提供理论支撑。首先,从下图d,对于如Kinetics Sounds and UCF-101的数据集,某一模态在数据集水平上全局碾压其他模态。更重要的是如图c,本文样本水平的模态评估,发现模态差异实际上在样本之间就有不同,而不仅仅是数据集水平上的不同。本文提出了全局平衡的MM-Debiased 数据集,数据集级别模态差异不再明显。
[1] “output logits” 通常指的是模型输出的未经 softmax 或 sigmoid 等激活函数处理的原始输出值。这些值通常用来表示模型对各个类别的预测得分或概率。
[2] 度的规模,即梯度的大小或幅度,梯度的规模可以影响参数更新的步长和方向,从而影响模型的收敛速度和稳定性。
[3] 沙普利价值。在博弈论中,沙普利价值(Shapley value)是一种用来衡量合作博弈中每个参与者对于整个博弈结果的贡献的方法。这个概念由Lloyd Shapley在20世纪50年代提出。它的核心思想是,对于一个合作博弈,每个参与者的贡献应该由他们对于所有可能联盟的贡献的平均值来确定。具体来说,一个参与者对于一个联盟的贡献被定义为当他加入这个联盟时,他能够为联盟带来的收益与联盟中其他成员带来的收益之间的差值。
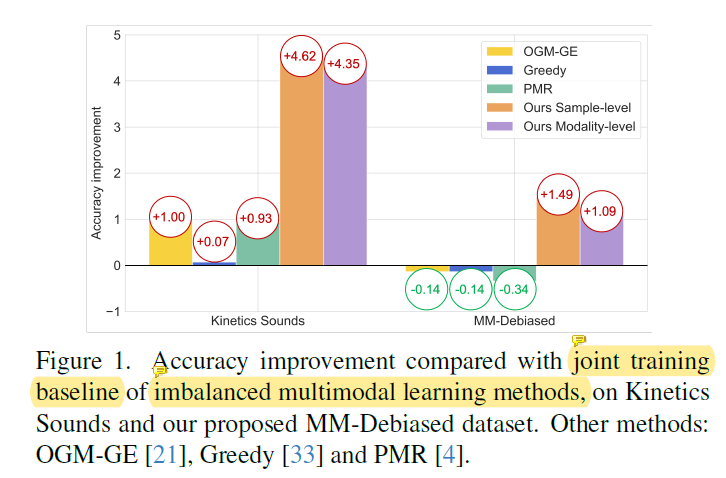
本文提出样本水平模态评估指标,来观察样本预测时每个模态的贡献率。博弈论中的沙普利价值[3]根据参与者贡献分配收益,为本文评估提供理论支撑。首先,从上图d,对于如Kinetics Sounds and UCF-101的数据集,某一模态在数据集水平上全局碾压其他模态。更重要的是如上图c,本文样本水平的模态评估,发现模态差异实际上在样本之间就有不同,而不仅仅是数据集水平上的不同。本文提出了全局平衡的MM-Debiased 数据集,数据集级别模态差异不再明显。而现存的不平衡多模态学习方法(只考虑数据集级别的差异)无法在MM-Debiased 保持性能,如下图。
基于上述实证结果,首先分析在一个样本中明显低贡献的模态,并且发现它的贡献将潜在地使得多模态模型倾向某一种模态。因此,恢复地贡献模态很关键。为了缓解上述问题,进一步分析了单一模态区分能力和其贡献的相关性,发现在训练时提高低贡献模态的区分能力能够直接在单一样本中改善贡献,并因此提高多模态协作。因此,本文提出基于模态间贡献差异,以有针对性的方式训练单个样本中的低贡献模态。
- 首先基于本文的沙普利模态贡献值评估样本水平的单一模态贡献率。
- 低贡献模态的输入以动态频率重采样,这个动态频率由提取的贡献差异决定,以提高区分能力。
- 考虑到样本水平模态评估的算力消耗,本文提出了一种高效的模态水平的方法。
如上图,本文考虑到样本水平模态差异的方法实现了很大的性能提升,不论是现存数据集还是本文提出的全局平衡数据集。
contribution
- 提出样本水平的模态评估指标并进一步分析低贡献模态问题,低贡献问题可能到低的模态协作能力
- 提出强化低贡献模态的方法,合理增强多模态协作
- 提出MM-Debiased数据集,该数据集由细粒度多模态差异,和现实世界更加接近。
related work
不平衡多模态学习
近期研究发现多模态模型偏向某一特定模态,有几个方法提出来解决这一问题来优化较差学习的模型。这些方法通过估计训练阶段的模态差异或者模态性能,控制单一模态的优化。然而,他们的估计难以在样本水平观察模态差异,也很难适应现实世界的变化。本文,根据沙普利价值合理评估样本水平的单一模态贡献,这一细粒度模态评估指标也将指引本文解决不平衡多模态学习的问题。
机器学习中的博弈论
博弈论的理论以及被用于规划和解决机器学习问题,如博弈论用于解释AdaBoost的算法有效性。和本文相似,有人用沙普利价值评估单一模态对整个数据集的贡献。但是它们不能获得样本水平上的贡献。本文不仅因此样本水平的模态评估,还进一步分析并减轻低贡献模态的问题。
method
3.1. Model formulation
主要就是最终预测是模型根据输入的所有模态做出的.
3.2. Fine-grained modality valuation 细粒度模态评估
对于每一个样本 x x x,
3.3 Low-contributing modality phenomenon 低贡献模态现象
- Remark 2.
由于模态的边际贡献是非负的,一种模态的边际贡献的数值收益遵循离散均匀分布。提高低贡献模态的区分能力能够提高这一模态的贡献。
3.4 Re-sample enhancement strategy 重采样增强策略
基于上面的remark2,本文提出一种方法在训练时有针对性地重采样,来提高区分能力。
- 为了确保模型具备基本的辨别能力,首先warm up几个epoch。
- 然后在每个epoch,评估每个样本的单一模态贡献。
- 然后,通过重采样改进低贡献模态的学习。
本文提出细粒度、样本级重采样方法和高效但粗粒度的模态级重采样方法。
3.4.1 Sample-level method
-
模态评估后,发现低贡献模态 i , ϕ i < 1 i,\phi^i<1 i,ϕi<1。
-
重采样频率通过在训练时提取 ϕ i \phi^i ϕi的值来决定。对于特定样本 x x x的 i i i模态的重采样频率 s ( x i ) s(x^i) s(xi)公式如下:
s ( x i ) = { f s ( 1 − ϕ i ) } , ϕ i < 1 否则为 0 s(x^i)=\left\{f_s(1-\phi^i)\right\} ,\phi^i<1 否则为0 s(xi)={fs(1−ϕi)},ϕi<1否则为0
f s ( ⋅ ) f_s(·) fs(⋅)是单调增函数。使用这种样本级重采样策略,样本 x x x的低贡献模态 i i i以重采样频率重新训练,重采样频率与其贡献成反比。
重采样的时候只采样低贡献模态,其他模态被遮掩为0,来确保针对性学习。
3.4.2 Modality-level method 模态级别重采样、
尽管样本级模态评估能提供细粒度单一模态贡献,但是算力消耗也很高。因此,更搞笑的模态级方法用来缓解算力需求。图2d,低贡献现象由数据集级别的偏向。比如UCF-101数据集中,RGB的贡献远高于光流。因此本文通过只进行模态级别的评估(平均单一模态贡献)来减少额外计算开销。
-
具体地,随机抽取训练集中包含 Z Z Z个样本的子数据集。因此可以发现全局低贡献模态 i i i
-
其他模态保持不变,样本 x x x的 i i i模态在训练阶段以特定的概率 p ( i ) p(i) p(i)动态重采样。
p ( i ) = f m ( N o r m ( d ) ) p(i)=f_m(Norm(d)) p(i)=fm(Norm(d))
d d d为其它模态和最低模态的差值的平均,先01正则化,然后输入函数 f m ( ⋅ ) f_m(·) fm(⋅),同样是单调递增函数,终值在0-1之间。重采样概率和低贡献模态与其他模态的平均差值成正比。
四 Experiment 实验
4.1. Dataset and experimental settings 数据集和实验设置
数据集
| 数据集 | 数据集类型 | 模态 | 类别 | 其它 |
|---|---|---|---|---|
| Kinetic Sounds (KS) | 动作识别数据集 | 声音和视频 | 31种人类行动类别 | 从Kinetics数据集中抽取出来。包含19k 个10秒钟的视频片段 |
| UCF-101 | 动作识别数据集 | RGB和光流两个模态 | 101种人类行动类别 | 整个数据集分为9537个样本的训练集和3783个样本的测试集 |
| MM-Debiased(本文提出的) | 声音和视频 | 10个类别。 | 数据集级别的模态差异不明显。包含11368个样本的训练样本和1472个测试集的训练样本。 |
实验设置
ResNet-18作为饰演的backbone。
- 用于UCF-101的编码器实在ImageNet上面预训练的。其它数据集的编码器从0开始训练。
- 训练期间,使用SGD(动量为0.9),学习率为1e-3
- 取训练样本的20%的子集,通过模态级方法分割。
- 模态评估时,对于输入模态集合 C C C,不在 C C C中的输入模态被清除。
- 测试期间,所有的模态被用于模型输入。
4.2. Comparison with multimodal fusion methods 对比不同的多模态融合方法
参与对比方法:Concatenation,Summation,Decision fusion,FiLM,Gated,还有早期的贝叶斯网络和多核学习(MKL)。公平起见,贝叶斯网络的单一模态编码器是ResNet-18,输入MKL的特征是通过预训练的单一模态器获得的。本文的样本级和模态级方法基于Concatenation。
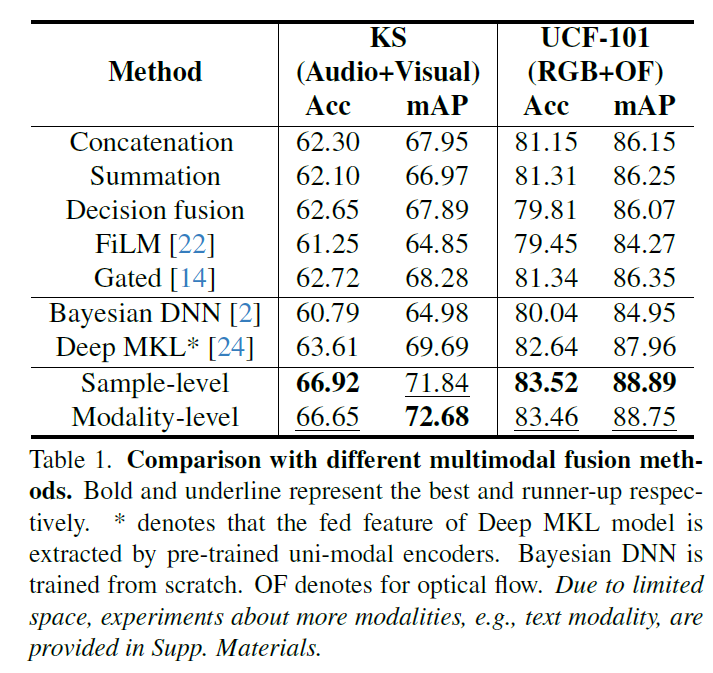
根据上表可得到如下结论:
- 早期的多模态融合方法能够在配备深度特征抽取后非常有效,特别是MKL甚至超过了Concatenation。但是,这有赖于输入的特征质量。
- 本文提出的样本级和模态级方法通过细粒度模态评估改进了多模态协作,实现了更好的模型性能。细粒度样本级方法要更好。但是模态级更加高效,有时几乎和样本级相当。
4.3. Comparison with imbalanced multimodal learning methods 不平衡多模态学习方法的对比
由于研究发现多模态模型通常不能很好地联合学习所有模态,因此一些不平衡模态学习方法被提出。这些方法通过估计训练阶段的差异或者模态间的表现,来控制单一模态优化。
惯例
-
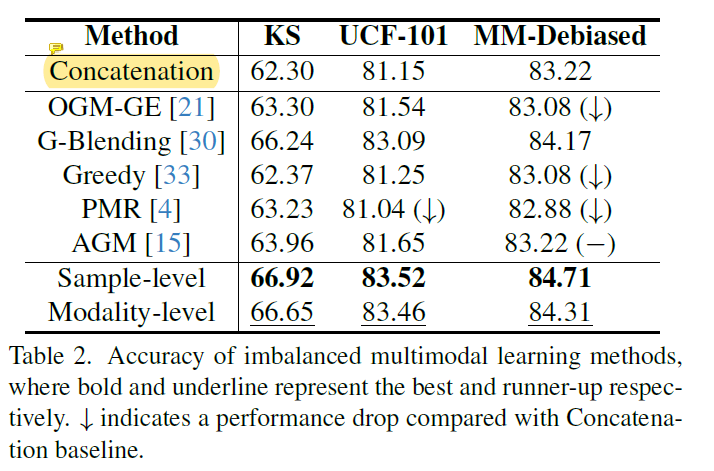
在很多数据集中比如Kinetics Sounds 和UCF-101,存在数据集级别的偏向,参与对比的方法在这些数据集上都有改进。而本文的方法为最好。尽管G-blending获得了相当好的性能,仍需训练额外的单一模态分类器。本文的样本级方法相比G-blending减少1/4 FLOPs,模态级1/2.
-
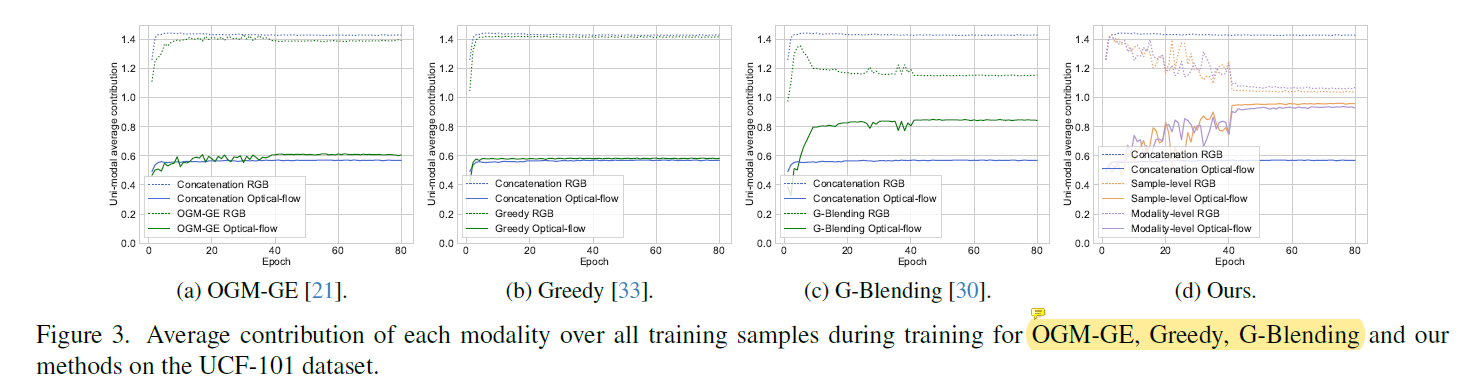
由于本文的模态评估并没有局限于特定方法,其它方法的单一模态贡献也能被评价观察。如下图3,本文大大减轻了不平衡的单一模态贡献。
更平衡的数据集
数据集级别的差异不明显,但是样本的差异依然显著,本文因此构建了MM-Debiased dataset。如上表2,大多不平衡多模态学习方法比baseline都要差,无法适应样本级的模态差异。本文方法能够合理评估细粒度模态贡献,并有针对性地增强低贡献模态的学习。
4.4. Comparison of sample-level modality valuation 样本级模态评估的对比
进一步对比不平衡多模态学习方法关于样本级模态的评估。这些方法为了控制单一模态优化,也会评估特定模态的贡献。比如G-Blending和Greedy监测单一模态训练过程。AGM评估模态贡献并用于控制梯度。但是他们不能评估样本级的模态偏向。OGM-GE使用的单一模态置信得分能被用于评估样本级的模态偏好,但是难以用于现实环境,比如同一类别下的不同样本间的支配性模态不同,导致产生不准确的结果。
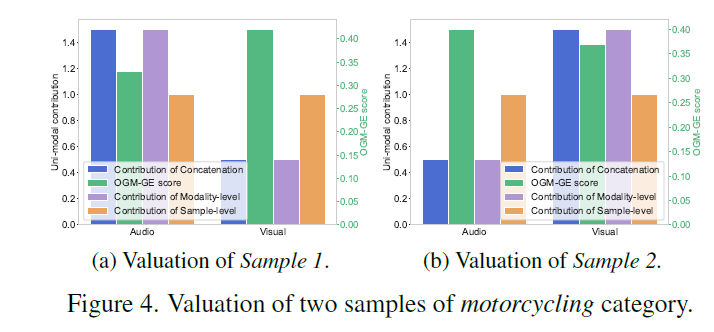
对于图2a,2b中的摩托车类别声音-视频样本来说,a很难观察到样本1中的摩托车,而样本2中的摩托车轮子就很容易看到。两个样本分别依赖声音和视觉模态。下图4评估不同方法对于这两个样本的模态评估。本文的方法明显且正确地发现了两者的贡献差异。
另外,本文的细粒度样本级方法据此调整单一模态学习,平衡细粒度模态差异。尽管模态级方法没能缓解这种差异,但在效率上获益。也证明样本级方法有其独特的优势和应用场景。
4.5. Complex cross-modal interaction scenarios 复杂的跨模态交互场景
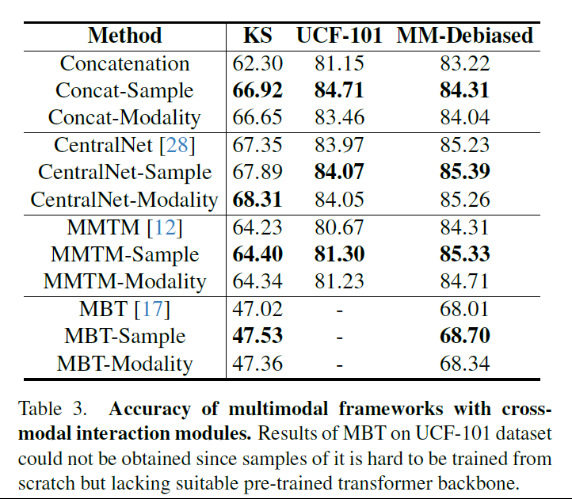
本文方法不局限于简单的融合策略,这里首先将样本级和模态级方法与CentralNet、MMTM两个融合方法结合起来,来评估跨模态交互场景下的有效性。如下表3,相比concatenation,这两个方法都改进了性能,说明跨模态交互可以隐式地加深模态协作。
另外,本文方法能够和跨模态交互一起很好地适应复杂场景。用本文方法改进后的concatenation有和其余两个模态交互方法相当的性能,说明本文方法简单又有效。而且,为了量化单一模态表征的质量,可视化了Kinetics Sounds dataset上低贡献模态变卖的特征分布。如下图5,根据运动类别下的特征分布在配备了本文方法后更加明显。(同色系点更加聚集)

除了这些CNN backbone的模态,transformer也有跨模态交互。将本文方法和MBT结合,结果如上表3。模型从0开始训练,注意到MBT的性能较差,因为数据不够它从0训练,但是本文的样本级和模态级方法仍能进一步改进性能。
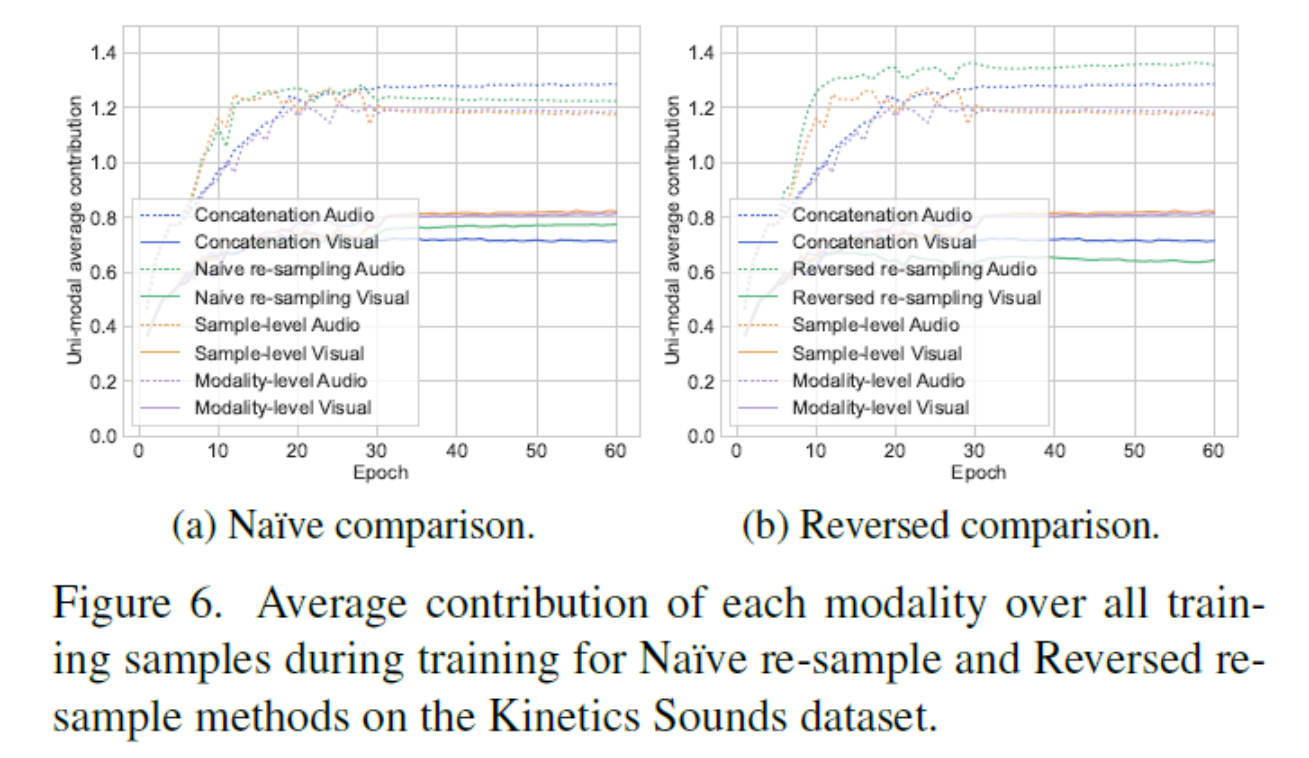
4.6. Comparison with other re-sample strategies 重采样策略对比
- 朴素重采样,以和本文相同的频率随机重采样每个模态的输入
- 逆向重采样,和本文相反,仅对具有较高贡献的模态的数据进行重新采样。
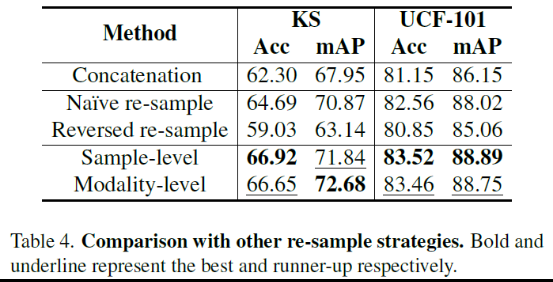
基于下表4,朴素重采样也能提高性能,可能是因为潜在地使每个模态单独训练,改进了区分低贡献模态的能力。如下图6a,朴素重采样方法实际减轻了低贡献的问题。本文更有针对性的重采样方法,在样本级模态评估的指导下,进一步优化了性能。逆向重采样则降低了性能。
总结
还是很有参考性的一篇文章,本文主要是两个模态,尝试沿用多个模态,并在算法上做突破
另外本文由假设新模态不会带来负作用,这个假设是否成立,有待研究

















 6319
6319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









