







JUST读论文 一些不偏视觉的CLIP相关工作
提示:当前可能文章内容不全,但是读论文还是主要有一个自己筛选信息的过程,这里算是我的读论文笔记,也可以说是翻译
目录
- JUST读论文 一些不偏视觉的CLIP相关工作
- 前言
- 一、Improving CLIP Fine-tuning Performance 2023 ICCV
- 二、SoftCLIP: Softer Cross-modal Alignment Makes CLIP Stronger 2024 AAAI
- 三、S-CLIP: Semi-supervised Vision-Language Pre-training using Few Specialist Captions 2023NeurIPS
- 四、Filip: Fine-grained interactive language-image pre-training 2022 ICLR
- 总结与思考
前言
这次主要看这几篇CCF A会论文,顺序是按照吴恩达大师推荐的顺序:标题 abstract figure intro conclusion …
- **Improving CLIP Fine-tuning Performance ** 2023 ICCV
核心思想:作者认为MIM比CLIP在下游任务微调发挥的作用好,其中token级是MIM的关键,因此通过蒸馏将图像级变成token级别
当前进度:读完table1我持怀疑,目前读完abstract intro
代码:https://github.com/SwinTransformer/Feature-Distillation - SoftCLIP: Softer Cross-modal Alignment Makes CLIP Stronger 2024 AAAI
核心思想:加入了自监督信号,不至于CLIP硬性 0 1。CLIP是硬性的0-1配比,给负对一些值能够防止灾难性失误,同时有效利用样本数据,充分使用了模态内的监督信息
代码:无 - S-CLIP: Semi-supervised Vision-Language Pre-training using Few Specialist Captions 2023NeurIPS
核心思想:利用伪标签填补特定领域数据少的问题 - Filip: Fine-grained interactive language-image pre-training 2022 ICLR
核心思想:patch和单词匹配的细粒度CLIP
代码:https://github.com/lucidrains/x-clip
一、Improving CLIP Fine-tuning Performance 2023 ICCV
改进CLIP微调性能
abstarct
CLIP模型有很好的0-shot识别准确性,然而他们在下游任务的微调性能却不那么好。相反,掩图像建模这个目标函数在下游任 务微调中发挥了很好微调作用,即使在训练的时候有语义标签的缺失。我们发现两类任务有不同的配件:图像级别的目标 VS token级别的目标, cross-entropy loss VS. regression loss ,完整图像输入和局部图像输入。为了减轻这种差异,我们引入经典的feature map蒸馏框架,能够在构建任务包含的MIM(masked image modeling)的关键部分时,继承CLIP模型的语义能力。实验证明这一方法在几个典型的下游视觉任务上有效改进微调性能。同时这个方法能后产生新的CLIP representation。并且这个feature map distillation方法能够泛化到其它预训练模型.
intro
预训练微调范式是有效的,通常在Imagenet1K数据集上训练的预训练模型权重作为初始化,但是有两个问题:扩充高质量图像分类数据以及类别标签上有限的语义信息。
CLIP解决了以上问题,有强大的语义建模信息。同时一个新的自监督预训练方式称为MIM(masked image modeling)具有优秀的微调性能。在不失去广泛性的情况下,主要讨论MAE。
对比这两种预训练方式:CLIP由于其卓越的线性探测性能,能够在Imagenet1K上学习更丰富的语义信息,然而在其他任务上都差于MAE。解码上面两种训练方式为输入比例、训练目标粒度和训练损失,实验结果排除了训练损失的影响,而输入比例(完整图和局部图)和训练目标粒度(图像级别和token级别)可能是关键因素。但是CLIP训练的图像级别换成token级别是极具难度的,因为现有视觉语言训练数据更适合图像级别监督而缺乏细粒度信息。
知识蒸馏是将知识从一个模型迁移到另一个最常使用的技巧,尤其是模型压缩,本文利用知识蒸馏将图像级别转换为token级别。使用预训练CLIP模型作为老师模型,使用输出的feature map作为蒸馏目标,将信息蒸馏到随机初始化的学生模型,该学生模型具有和老师模型一样的大小和架构。尽管学生模仿老师的输出,他们不同的优化路径导致了中间层不同的属性,该层被认为对于微调很重要。
蒸馏框架的灵活性允许我们引入正确的偏置和正则化来塑造学生模型的优化路劲以提高学生模型在下游任务上的性能。有以下几个关键的调整:教师feature map的标准化,稳固输出并扩大教师模型包含的精妙信息;不对称drop path rates,提升学生模型的表征鲁棒性并和教师模型一致且准确;引入的偏置进一步增强学生模型的转换不变性。
所以最后创造了一个既有强语义信息又能对下游任务友好的模型。当扩大模型到最大的CLIP-L/14模型后,这种改进也一直保持。并且,当模型泛化到其它模型是,比如DINO、DeiT以及先进的SwinV2-G,仍然能在下游任务上获得良好的收益。
除了展示先进的实验结果,还提出了几个诊断工具来分析从不同模型上习得的视觉表征。这些分析提供关于特征蒸馏如何改进CLIP模型更深层次的理解:在CLIP模型更深的层多样化不同的注意力头;改进习得的特征的转移不变性;扁平化损失并体现优化友好性。
贡献
- 研究CLIP和MIM方法的差异并证明目标力度是MIM在微调时有利的关键因素
- 使用经典的feature map 蒸馏将CLIP的训练目标粒度变为token级别,这提高了微调性能并保护了语义信息
- 提出在特征蒸馏时的几个关键方法,以加深改进,包括蒸馏标准化的feature map,不对称drop path rates以及共享相对位置偏置
- 使用几个诊断工具,我们发现和CLIP相比,MIM和FD-CLIP具有天然的优势。
- 将我们的方法泛化到多种预训练方式,并获得了一致的改进,在COCO目标检测的记录上创造了新高。
conclusion
本文想要用经典的feature 蒸馏框架在CLIP模型上改进其微调性能,同时继承最初的语义能力。通过分析CLIP和MIM在分类和定位任务的差异,token级别的目标粒度是MIM成功的关键,特别是优秀的微调性能。所以引入蒸馏变成token级别的任务,和原始CLIP相比,在多种下游任务上达到一致和明显的改进,同时最大化保留语义信息。
使用几个注意力和优化器相关的工具研究了FD-CLIP,可视化结果证明在蒸馏之后,FD-CLIP的模式更接近MIM,进一步将框架泛化至其它模型,包括DeiT,DINO等等。
limitation
模型训练流水线复杂,有额外的训练开销,相比CLIP 多了3%。诊断工具无法直接揭示微调性能。
二、SoftCLIP: Softer Cross-modal Alignment Makes CLIP Stronger 2024 AAAI
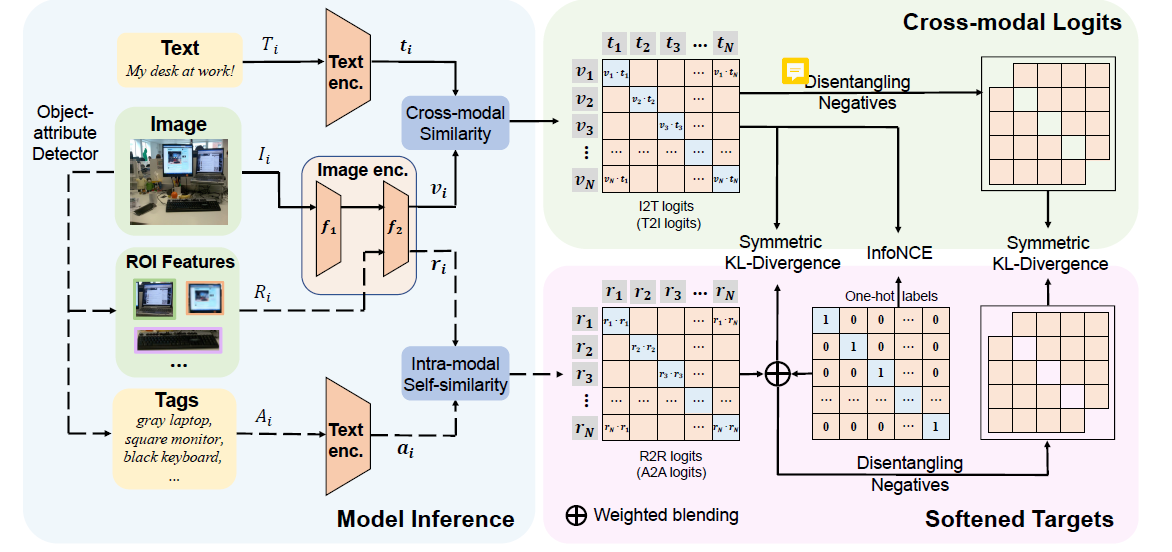
更软的跨模态对齐使CLIP更强大
通常是ResNet50或者ViT-B/16作为图像编码器,YFCC15M-V2作为预训练数据集
abstract
在上一个两年期,视觉语言预训练已经在多个下游任务中实现了令人瞩目的成功。然而,获得完全排他的图文对仍是一个挑战性的任务,并且噪音存在在所有通常使用的数据集中。为了解决这个问题,提出SoftCLIP,释放了一对一的关系,并通过引入软目标实现软跨模态对齐,这个软目标是通过细粒度模态内自相似度产生的。模态内旨在使两对有一些局部相似性并在两个模态间构造多对多关系。并且,因为正面也在软目标分布中占据支配地位,将负面从分布中清除以进一步用负对提高关系对齐效果。0-shot 分类性能提升6.8%
intro
CLIP其实就是将正样本拉近,将负样本拉得更远。其实就是排他的完全1v1太严苛而不可取,利用label smoothing来减轻这种问题,忽视负样本的潜在差异导致一部分有效数据的无效利用,以及对潜在数据结构的不完全理解。
本文利用模态内差异信息引导视觉和语言模态的交互,使用细粒度模态内自相似度作为软标签进行软模态对齐。
conclusion
本文提出了SoftCLIP,一种新奇的方法解放了严格的一对一限制,并且通过引入模态内自相似作为软标签并且将负值从分布中剔除,实现了软跨模态对齐。SoftCLIP能够在网络爬取的含噪声图文数据集上构建多对多关系,大量实验证明了有效性。
related work
视觉语言预训练
VLP旨在获得两个模态的统一表征,通过使用大规模图文对。通常CLP模型分为双流对齐、单流融合或者他们的组合使用。CLIP就是双流
| 双流模型 | 效果 | 发布信息 | 论文名称 | 有无代码 |
|---|---|---|---|---|
| SLIP | 加入自监督提高数据使用效率 | 2022 ECCV | Slip: Self-supervision meets language-image pretraining | https://github.com/facebookresearch/SLIP |
| DeCLIP | 加入自监督提高数据使用效率 | 2022 ICLR | Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm. | https://paperswithcode.com/paper/supervision-exists-everywhere-a-data-1#code |
| Pyramid-CLIP(也是腾讯优图的) | 更细粒度,两个模态更多交互,更准确模态匹配,提出lable smoothing(从0和1硬性值变成01之间的柔性值) | 2022 NeurIPS | Pyramidclip: Hierarchical feature alignment for vision-language model pretraining | 无 |
| FILIP | 更细粒度,两个模态更多交互,更准确模态匹配 | 2022 ICLR | Filip: Fine-grained interactive language-image pre-training | https://paperswithcode.com/paper/filip-fine-grained-interactive-language-image-1#code |
| CyCLIP | 两个模态的表征空间几何一致性很重要,提出几何一致性限制 | 2022 NeurIPS | Cyclip: Cyclic contrastive language-image pretraining. | https://paperswithcode.com/paper/cyclip-cyclic-contrastive-language-image#code |
| 单流模型 | 效果 |
|---|---|
| Visual-BERT | 单流更深的交互 |
| OSCAR | 单流更深的交互 |
| ALBEF | 两种架构,找到了一个灵活学习视觉和语言表征的方式 |
| CoCa | 两种架构,找到了一个灵活学习视觉和语言表征的方式 |
本文是双流架构,不使用独热编码标签,而使用细粒度模态内自相似度作为软标签以提供更多信息指引,促使模态间交互。
软标签
软标签旨在减轻独热标签的严格限制,并且避免模型向错误的预测过度置信。
- label smoothing 通常在分类任务中使用的策略,给负样本的真实标签一点正值
- 在知识蒸馏领域,教师模型的logits用作指导标签,软标签包括教师建模的所有样本,比独热标签更有指导性
- CLIP-PSD 自蒸馏,学生模型作为他自己的老师,朝教师模型动态进化
本文也是自蒸馏,软标签是预先提取的ROI
methodology
3.1先介绍了CLIP相关内容以及label smoothing,这里不再赘述。
3.2 模态内指引的软对齐
使用模态内自相似性作为软标签,准确的模态内自相似性能够提供卓越的监督信号。
初始,可能选择原始的图像和文本来计算模态内自相似性,比如图像和图像之间的相似性,文本和文本之间的。然而这种方式并不好(这种方式就不像多模态了,没有模态交互)之前的方法预抽取显著物体的ROI特征以及每个物体的标签,引入croess-level 关系对齐,这样带来了显著效果。ROI特征和对应的标签,由预训练的目标-属性检测器抽取,本文在此基础上有选择地使用ROI 特征和标签来计算模态内自相似性。
接下来这段我用草稿笔记来说了。
3.2 利用负样本提高关系对齐
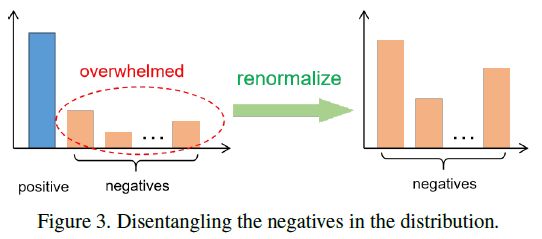
引入模态内自相似度确实解决了严苛的一对一限制并指引模型学习多对多的对应,然而正样本的置信度仍然居高,这会使得在多模态关系对齐上大量负样本淹没在支配性正样本的阴影下,尤其是当网络爬取的图文对实际并不像管事问题会是致命的。为了解决这个问题,将负样本在分布中剔除,以用负样本提高关系对齐。
特别的,将正样本logit在概率分布中丢弃,只在负样本Logit中重新标准化。如下图。
3.4 训练目标
KL散度是不对成的,而JS散度是KL散度的对称替代品。然而作者发现JS散度使得训练周期不稳定,因此作者通过加入相反的分布,使KL散度对称。
4.实验
4.1 预训练和评估细节
架构和预训练数据集: 适配了三个典型模型架构,视觉编码器包括ResNet50、ViT-B/32、ViT-B/16,语言编码器跟随CLIP使用transformer架构。输入视觉编码的分辨率是224*224,输入语言编码器的最大上下文长度是77。本文再三个数据集上预训练:CC3M,CC12M,YFCC15M-V2
目标-属性检测器:用来提取包含标签的ROI的检测器由VinVL预训练,使用Faster R-CNN的框架。通过检测器,我们从每个图像中取最高置信度的10个目标来获得对应的ROI特征和类别描述。每个ROI特征2052个维度,由2048维的外表特征向量和4维位置向量组成。(左上和右下的坐标)
实施细节:AdamW优化器,权重衰减率为0.2;consine 学习率 with 线性warm up,且学习率在10%总epoch里就从0线性增长到峰值,并且以余弦退火策略衰减。为了节省GPU内存,使用自动混合精度训练。模型从0开始训练8或者32个epoch,8用来消融实验,32用来对比。使用8卡V100进行训练,当使用ResNet50和ViT-B/32时batch size时2048,当使用ViT-B/16时,batch-size是1024.
用于评估的下游任务:三个下游任务——0-shot图像分类、0-shot图文检索和图像检索。对于0-shot图像分类,实验在7个数据集上进行,比如ImageNet、Pets、Describable Textures、Food-101、Flowers-102、SUN397、Caltech-101。对于0-shot图文检索,在Flickr30K、MS-COCO。对于图像检索,包含两个子任务,实例检索在Oxford和Paris Buildings,在INRIA Copydays。
三、S-CLIP: Semi-supervised Vision-Language Pre-training using Few Specialist Captions 2023NeurIPS
使用极少专家字幕的半监督视觉语言学
abstract
CLIP在应用到特定领域有困难,因为如遥感领域没有这么多的图文对,S-CLIP使用两个专门为对比学习和语言模态设计的伪标签策略。字幕级别的伪标签由配对图像的字幕组合给出,该组合通过解决未配对图像和配对图像之间的最优传输问题而获得。关键词级别的伪标签由最接近的配对图像的字幕中的关键词给出,经过部分标签学习训练得出,部分标签学习认为候选标签集合进行监督而不是特定的一个标签。通过组合这些目标,S-CLIP显著提升CLIP训练,仅使用一些图文对,在包括遥感、时尚、科学图像和漫画此类专家领域。比如提升CLIP 0-shot分类性能10%以及图文检索4%(遥感benchmark),和有监督CLIP性能相一致,使用了3倍图文对。
四、Filip: Fine-grained interactive language-image pre-training 2022 ICLR
细粒度语言图像交互预训练
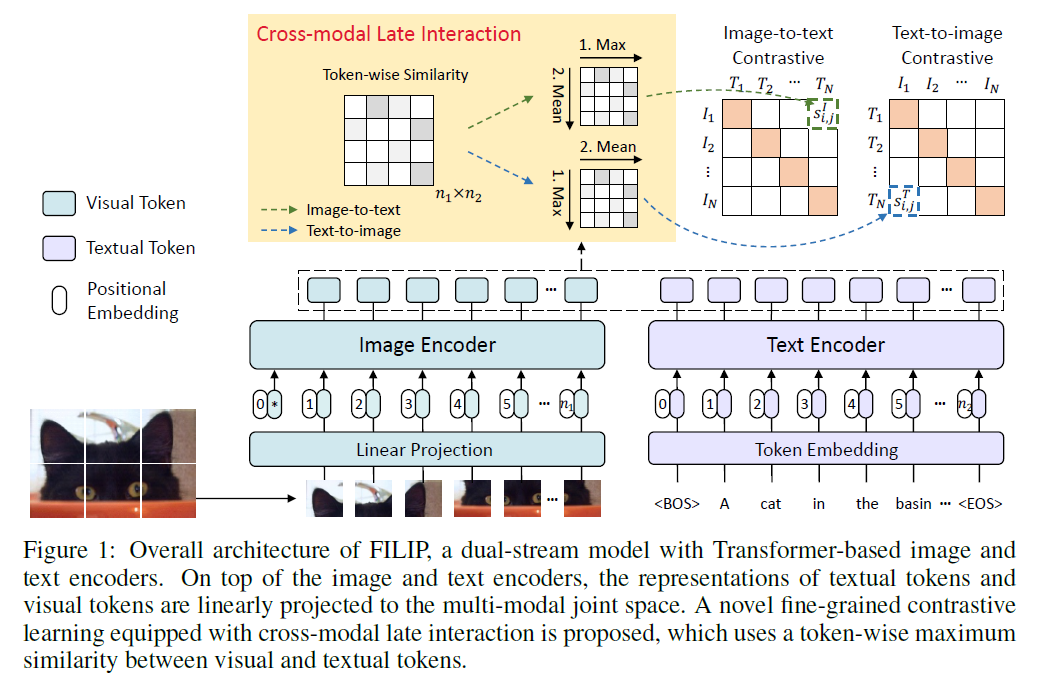
abstract
无监督大规模视觉语言预训练在大量下游任务中展示了强大的先进性,现存方法经常通过每个模态的全局特征相似性构建跨模态交互,或者对视觉和文本token利用跨/自注意力进行更细粒度的交互。然而,跨/自注意力在训练和推理时性能都不好。本文介绍了大规模细粒度交互语言图像预训练以实现更细粒度的对齐,这种方式是通过跨模态延迟交互机制完成,在视觉和文本token中使用token对的最大化相似来引导对比目标。FILIP在图像patch和文本单词之间成功使用更细粒度的表达,通过修改仅使用对比损失,同时在推理时离线预计算图像和文本的表征,使得训练和推理都很高效。另外,我们构建了新的大规模图文对FILIP300M用于预训练。在大量视觉语言下游任务中是实现SOTA,包括0-shot图像分类和图文检索。word-patch对齐的可视化进一步展示FILIP能够通过定位能力学习有意义的细粒度特征。
introduction
诸如CLIP和ALIGN的大规模视觉语言预训练模型在大量下游任务上获得了成功。借助从互联网上爬取的百万图文对习得视觉和文本表征,并展示出强大的0-shot能力和鲁棒性。这些模型的核心在于通过双流模型的全局对比对齐。这种架构具有推理高效的特点,因为两个模态的编码器能被解耦,图像和文本表征能离线预计算。然而两种模型缺乏捕获更细粒度的信息,比如视觉对象和文本单词的关系。本文提出简单而有效的跨模态细粒度交互用于大规模VLP。
为了实现更细粒度跨模态交互,先前的方法可大致分为两类:1.一种工作是使用预训练目标检测器提取ROI,将其和文本通过VLP模型融合,这些方法由于预计算和存储大量ROI特征使得预训练复杂。另外,0-shot能力收到预先定义的而类别限制,性能也收到检测器的限制。
| 论文 | 发表信息 | 代码 |
|---|---|---|
| Uniter: Universal image-text representation learning | 2019 ECCV CCF-B | https://paperswithcode.com/paper/uniter-learning-universal-image-text-1#code |
| Oscar: Object-semantics aligned pre-training for vision-language tasks | 2020 ECCV | https://paperswithcode.com/paper/oscar-object-semantics-aligned-pre-training#code |
| M5product: A multi-modal pretraining benchmark for e-commercial product downstream tasks | 2021 | |
| Unimo: Towards unified-modal understanding and generation via cross-modal contrastive learning | 2021 ACL | https://paperswithcode.com/paper/unimo-towards-unified-modal-understanding-and#code |
| Vinvl: Revisiting visual representations in vision-language models | 2021 CVPR | https://paperswithcode.com/paper/vinvl-making-visual-representations-matter-in#code |
| Product1m: Towards weakly supervised instance-level product retrieval via crossmodal pretraining | 2021 |
- 另一类是将token对或者patch对表征变为相同的空间,利用cross-attention或者self-attention将这些更细粒度的交互建模。然而这些方法在训练和推理时并不那么高效。特别是在训练的时候,cross-attention需要经过编码器-解码器的结构,而self-attention的复杂度随着两个模态序列合并的长度延长而暴涨。在推理的时候,两个模态的数据交织在一起计算cross-attention或者self-attention,并且不能像双流模型异样离线预计算。因此会降低下游任务上的高效性。
| 论文 | 类别 | 发表信息 | 代码 |
|---|---|---|---|
| Align before fuse: Vision and language representation learning with momentum distillation | cross-attention | 2021 NeurIPS CCF-A | https://paperswithcode.com/paper/align-before-fuse-vision-and-language#code |
| Vilt: Vision-and-language transformer without convolution or region supervision | self-attention | 2021 ICML CCF-A | https://paperswithcode.com/paper/vilt-vision-and-language-transformer-without#code |
本文提出FILIP来解决问题,受到Efficient and effective passage search via contextualized late interaction over bert(关键论文,也可能是最相似论文)启发,在对比损失中使用跨模态延迟交互机制,而不是使用cross或者self attention。本文在视觉和文本token中使用token对最大化相似来引导对比目标。通过这种方式,FILIP成功在图像patch和文本单词中使用了更细粒度的表达方式,同时还获得了离线预先计算图像文本的表征。和关键论文不同,本文抛弃了填充token,并且在计算图文对的时候使用token对的最大化相似值的平均而不是之和,这提高了跨模态表征能力并稳定了训练。另外,本文从互联网上构建了大规模预训练数据集FILIP300M(不开源,因为我没搜到)。数据清洗和图文数据增强都在本文中揭示并证实有效。
大量实验证明有效学习细粒度表征,FILIP在大量下游视觉语言任务中达到SOTA,包括0-shot图像分类和图文检索。0-shot ImageNet图像分类达到77.1% top 1 accuracy,以更少的训练数据超过了CLIP。在单词-patch对齐上的可视化进一步证明FILIP学习到了有意义的更细粒度特征,具备先进的定位能力。
conclusion
本文引入FILIP,一种简单通用进行细粒度视觉-语言预训练的框架。通过使用token对最大相似度,我们的方法学习了图像patch和句子单词的细粒度表征。与一些大规模多模态预训练模型在多种下游任务上相比,我们的模型实现了有竞争力的效果,同时架构和训练模式都能再进一步改进。未来更好的图像编码器和更好的交互层可以进一步提升性能。另外,可以加入掩语言或者掩图像损失来支持更多的生成任务。
related work
。。。
method
本文使图像编码器和文本编码器进行更细粒度的交互,从而挖掘更多语义对齐。FILIP是基于transformer架构的图像文本编码器双塔结构。图像编码器是ViT,结合额外的CLS和线性映射的图像patch作为输入。对于文本模态,和CLIP异样,使用小写BPE,词表长度为49408对文本分词。每个文本序列以BOS开始,EOS结尾。再embedding层之后,token embedding输入修改后的CLIP单encoder transformer。在图文编码器顶端,视觉和文本token被线性映射到多模态共有空间,并通过L2正则化分开。和其它仅通过完整图像文本全局特征的跨模态交互的双塔模型(CLIP&ALIGN)不同,本文引入新的细粒度对比学习目标以及跨模态延迟叫,这将图像patch和文本token的细粒度交互纳入学习。
3.1 细粒度对比学习
对比表征学习能比预测类对手在视觉和视觉语言跨模态预训练中学习到更好的表征。在跨模态对比学习的通用攻势下。

总结与思考
在思考多模态这里CLIP还有没有发展前景了
后续还会看其它多模态文章的
本人主偏NLP的多模态















 40
40











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









