







 文章探讨了现有基于重构方法在异常检测中的局限性,提出记忆导向变压器(MEMTO),通过门控存储器模块和增量训练策略来减少过度泛化。该方法通过限制编码器处理异常的能力,提高对异常样本的重建难度,有效区分正常和异常数据。
文章探讨了现有基于重构方法在异常检测中的局限性,提出记忆导向变压器(MEMTO),通过门控存储器模块和增量训练策略来减少过度泛化。该方法通过限制编码器处理异常的能力,提高对异常样本的重建难度,有效区分正常和异常数据。
目录
一、问题与思路
1.1 现存问题
现有的基于重构的方法可能存在过度泛化的问题,即异常输入被重构得太好。如果编码器提取异常的独特特征,或者解码器对异常编码向量具有过度的解码能力,则可能发生这种情况。
Q1:为什么“只用正常样本训练,由于编码器和解码器表达能力的限制,模型仍然可能对异常样本具有比较好的重构能力”,明明没有对异常模式进行学习,为什么对其还有比较好的重构能力?
A1:主要是由于编码器和解码器本身的建模能力存在局限性。
- 编码器在提取特征时,主要学习到了正常数据中的一些网络结构/分布信息等。这些特征很可能对异常数据也有一定的表示能力。
- 解码器在解码时,主要学习到了如何从编码向量重构输出。这种重构的模式很可能也适用于异常数据,即使输入的是异常的编码向量,也能重构出较为正常的输出。
也就是说,这些网络组件本身对输入输出的建模并不是百分之百完美和严格的。它们根据正常数据学到的模式,很可能也适用于未见过的异常数据。这是由于它们自身的局限性导致的过度泛化。
1.2 解决思路
本文提出了一种新的基于重构的多变量时间序列异常检测方法——记忆导向变压器(MEMTO)。门控存储器模块是MEMTO的关键组件之一,它包括表示数据中正常模式的原型特征的项。我们采用增量方法来训练门控存储模块中的单个项目。
它根据输入数据确定每个现有项目的更新程度。这种方法使MEMTO能够以更加数据驱动的方式适应各种正常模式。利用存储在存储器中正常模式的特征重构异常样本可以得到与正常样本相似的重构输出。在这种情况下,MEMTO很难重建异常,从而释放了过度泛化的问题。
二、模型与方法
2.1 模型概览
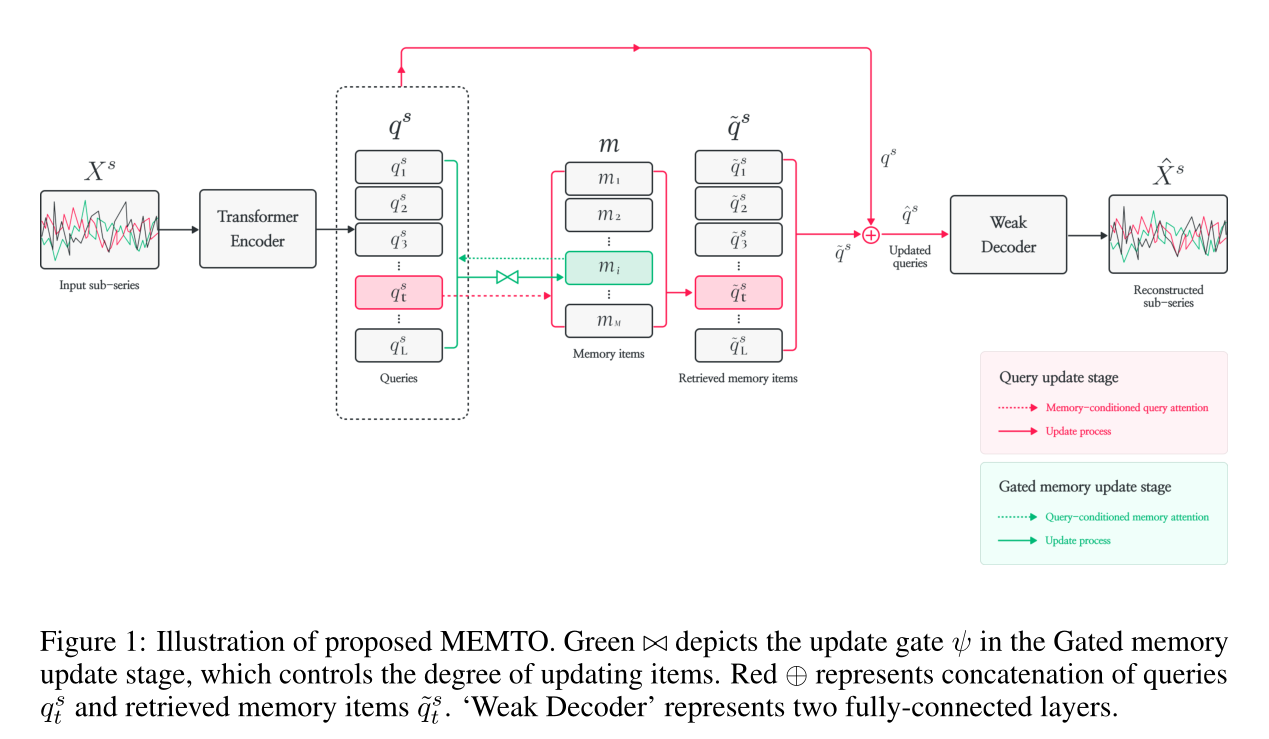
首先将输入子系列
X
s
X^s
Xs馈送到编码器,然后将编码器输出特征用作查询
q
s
q^s
qs,以检索相关项或更新门控内存模块中的项。解码器的输入是更新后的查询,它们是查询
q
t
s
q^{s}_t
qts和检索到的记忆项的组合特征。解码器将更新后的查询序列映射回输入空间,完成重构。

2.2 Encoder and decoder
MEMTO使用transformer的编码器将输入子序列投射到潜在空间。用由两个完全连接的层组成的弱解码器。解码器不应该过于强大,因为这可能导致其性能独立于编码器编码输入时间序列的能力的情况。
2.3 门控存储器模块
该机制旨在限制编码器捕获异常独特属性的能力,从而使重建异常数据更具挑战性。
2.3.1 门控存储器更新阶段
我们期望内存项包含与正常时间戳相对应的所有查询
q
q
q的原型。因此,我们采用一种增量的方法,通过定义查询条件的记忆注意
v
i
,
t
s
v_{i,t}^{s}
vi,ts(i=1,2,…M)来更新记忆项。它由softmax计算每个内存项和查询之间的点积,如下所示:
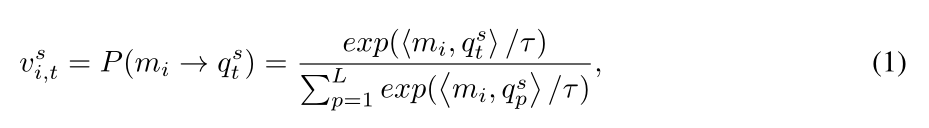
算出来的 v i , t s v_{i,t}^{s} vi,ts就代表着第s个窗口,在第t个时间点,查询q和第i个内存项的注意力值,所以最终结果应该是一个L×M的矩阵,代表这个时间窗口中每个时间点与每个内存项的一个注意力矩阵
我们在我们的记忆模块机制中提出了一个更新门ψ,以根据各种正常模式灵活地训练每个记忆项。这个门控制从查询中获得的新正常模式注入到存储在内存项中的现有原型正常模式的程度,它允许我们的模型以数据驱动的方式学习每个现有内存项应该更新到什么程度。我们的内存更新机制的方程是:
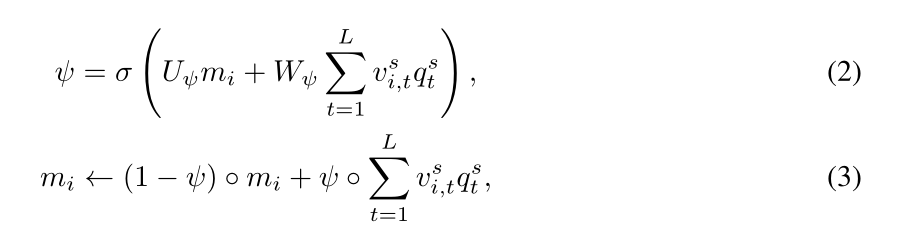
U
ψ
,
W
ψ
U_ψ,W_ψ
Uψ,Wψ表示线性投影,σ 表示sigmoid函数,◦ 表示逐项积
2.3.2 查询更新阶段
在查询更新阶段,我们生成更新后的查询,然后将其作为输入馈送给解码器。与门控内存更新阶段类似,我们定义了内存条件查询注意力
w
i
,
t
s
w_{i,t}^{s}
wi,ts,由softmax计算每个查询与内存项之间的点积如下:
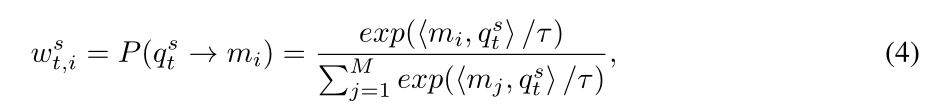
然后,将检索到的记忆项
m
i
m_i
mi加权和,取
w
i
,
t
s
w_{i,t}^{s}
wi,ts作为其对应的权重,得到检索到的记忆项:

原始查询的q和检索到的记忆项q沿着特征维度连接,构成更新的查询。更具有鲁棒性,因为原始查询的q中异常的独特属性可以被内存项中的相关正常模式抵消。异常的重建输出通常与正常样本相似,这使得异常的重建更具挑战性。这种强化的难度有助于更有效地区分正常和异常数据,防止过度泛化。
2.3.3 损失函数
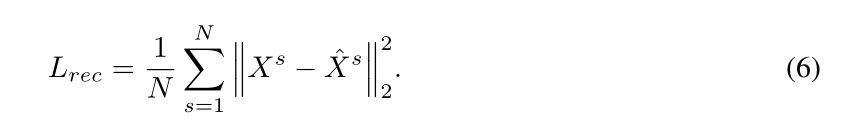
密集的
W
S
W_S
WS使一些异常有可能被很好地重建,因此,为了保证在内存中只检索有限数量的密切相关的正常原型,我们引入了熵损失
L
e
n
t
r
L_{entr}
Lentr作为我们对
W
s
W_s
Ws进行稀疏正则化的辅助损失:
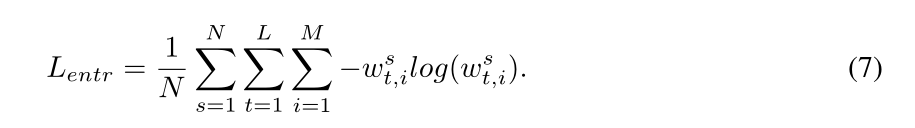

2.3.4 初始化内存项
由于我们是逐步更新记忆项的,如果这些项是随机初始化的,那么在训练过程中就有不稳定的风险。我们提出了一种新的两阶段训练范式,该范式使用聚类方法将记忆项的初始值设置为数据的近似正常原型模式。
在第一阶段,MEMTO通过重建输入的自监督任务进行训练,经过训练的MEMTO编码器对随机抽样的10%的训练数据生成查询
q
q
q。然后,我们应用K-means聚类算法对查询进行聚类,并将每个质心指定为记忆项的初始值。

2.3.5 异常评分
我们引入了一个综合考虑输入和潜在空间的基于二维偏差的检测准则。
我们将时间点t处的潜空间偏差(LSD) 定义为每个查询q与其最近的记忆项m之间的距离,异常时间点的LSD会比正常时间点的LSD大,因为每个记忆项都包含一个正常模式的原型。
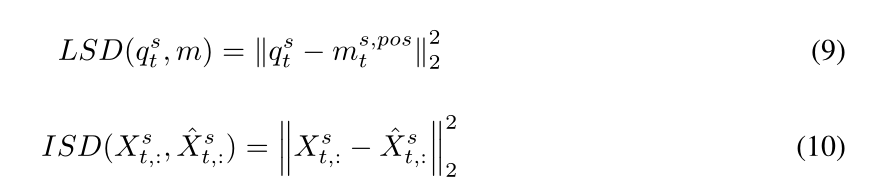
我们将归一化LSD与ISD相乘,用LSD作为权重放大ISD的正异常差:
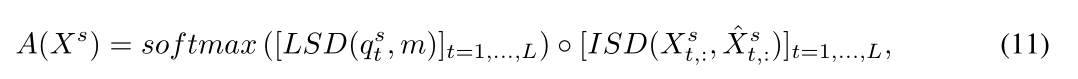
2.3.6 阈值设定
将阈值设置为来自训练和验证数据的异常得分组合结果的top-p%,并为每个数据集指定p值。假如规定的p值是5%。 那么其中的步骤就是:
- 分别计算训练数据和验证数据的每一个样本点的anomaly score。
- 将两部分的anomaly score合并到一起,形成一个大的anomaly score集合。
- 取这些anomaly score排序最高的前5%分数点,设置为阈值。
- 在测试数据上,分数高于这个阈值的点,判定为异常。
三、实验与分析
3.1 模型结果
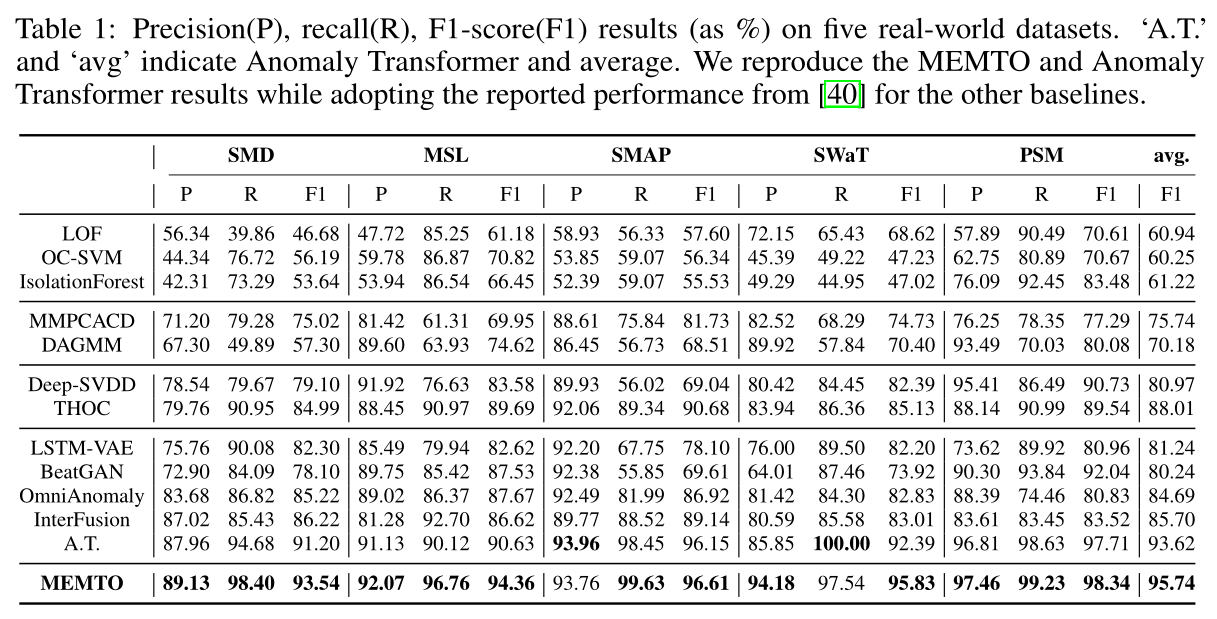
3.2 消融实验
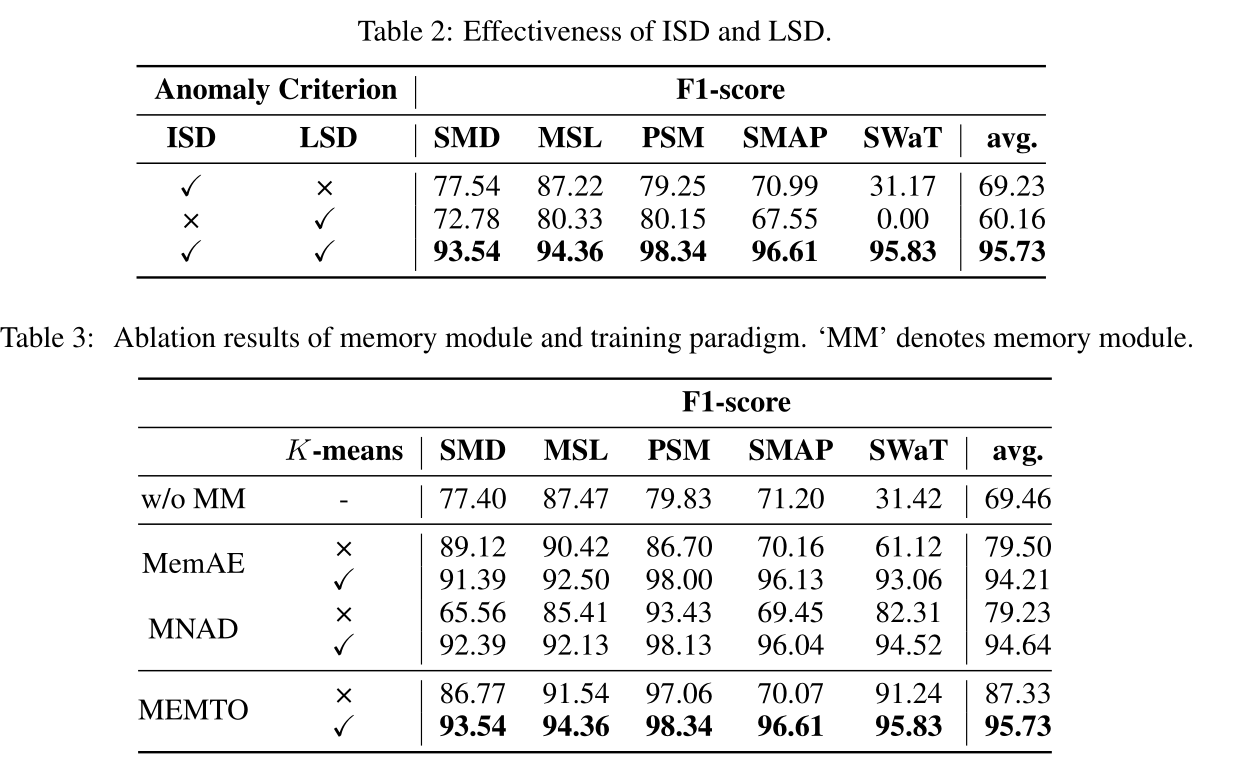
3.3 LSD的统计分析
我们进一步探索门控存储模块在数据中捕获原型正常模式的优越能力。每种类型内存模块的平均LSD值如下:
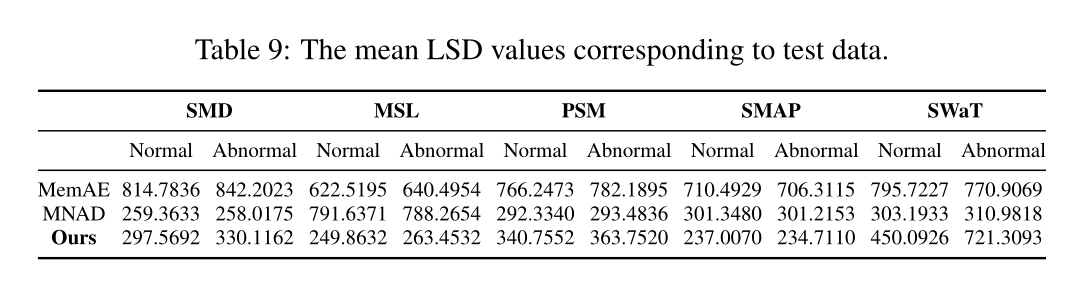
在大多数数据集中,我们提出的门控内存模块始终显示出正常样本比异常样本更低的平均LSD值。此外,这些值之间的相对差异比其他存储模块机制更显著。这些结果证明了我们的记忆模块机制在捕获数据中正常模式的原型特征方面的有效性。
下图展示了与一个段内的每个时间戳相关联的异常评分和真实值标签:
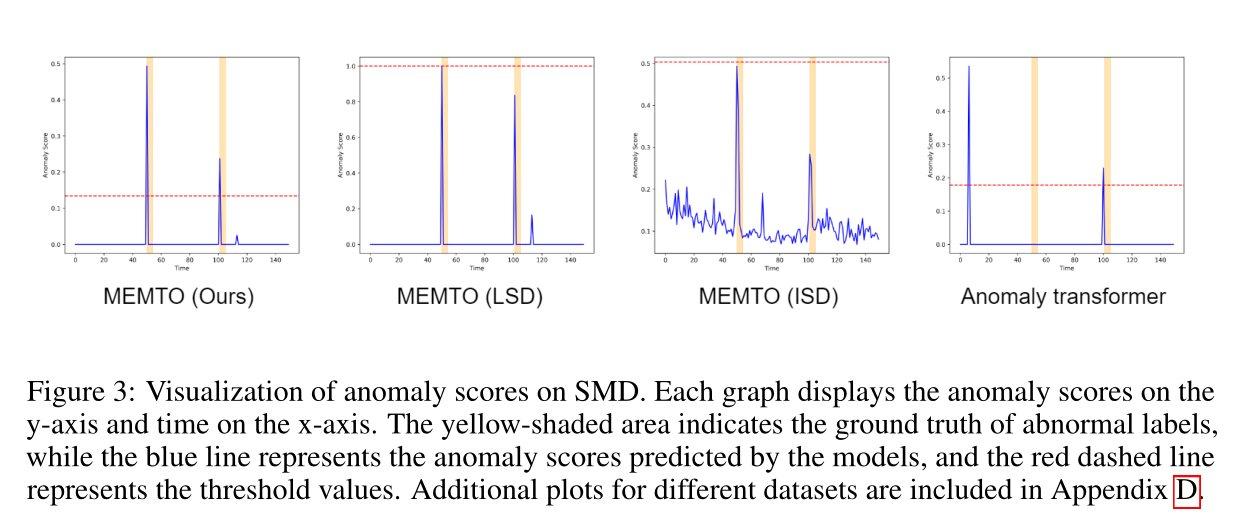
结果表明,与基线相比,基于二维偏差的准则能较好地检测出异常。















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









