








不断修订中。。。
文章目录
1、背景
显卡(Video card,Graphics card)全称显示接口卡,又称显示适配器,是计算机最基本配置、最重要的配件之一。
显卡接在电脑主板上,它将电脑的数字信号转换成模拟信号让显示器显示出来。
GPU(Graphic Processing Unit)是显卡上的一块芯片,就像 CPU 是主板上的一块芯片
CUDA (Compute Unified Device Architecture),通用并行计算架构,是一种运算平台
你只要使用一种类似于 C 语言的 CUDA C 语言,就可以开发 CUDA 程序,从而可以更加方便的利用 GPU 强大的计算能力,而不是像以前那样先将计算任务包装成图形渲染任务,再交由 GPU 处理
CPU负责逻辑性强的事物处理和串行计算,GPU 则专注于执行高度线程化的并行处理任务(大规模计算任务)
附1:独立显卡和集成显卡的区别。
所谓集成,是指显卡集成在主板上,不能随意更换。而独立显卡是作为一个独立的器件插在主板的AGP接口上的,可以随时更换升级。
另外,集成显卡使用物理内存,而独立显卡有自己的显存。一般而言,同期推出的独立显卡的性能和速度要比集成显卡好、快。
值得一提的是,集成显卡和独立显卡都是有 GPU的。
2、前言
日常炼丹时,nvidia-smi 可以看到如下界面

watch nvidia-smi 可以看到动态的,页面中显存占用和 GPU 利用率有直接的联系吗?本博客就此展开讨论
扩展版 浅谈深度学习:如何计算模型以及中间变量的显存占用大小
结论:显存占用和 GPU 利用率的关系可以类似看成内存和 CPU 的关系
3、显存占用
显存可以看成是空间,类似于内存。
显存用于存放模型,数据
显存越大,所能运行的网络也就越大
3.1、参数的显存占用
参数占用显存 = 参数数目 ×n

eg: Float 32 时,n = 4
在 PyTorch 中,当你执行完 model=MyGreatModel().cuda() 之后就会占用相应的显存,占用的显存大小基本与上述分析的显存差不多(会稍大一些,因为其它开销)。

3.2、梯度与动量的显存占用

SGD + momentum(把上一次的梯度更新当成惯性) 的讲解可以参考 随机梯度下降与动量详解
3.3、输入输出的显存占用
计算出每一层输出的 Tensor 的形状,然后就能计算出相应的显存占用。
模型输出的显存占用,总结如下:
- 需要计算每一层的 feature map 的形状(多维数组的形状),模型输出的显存占用与 batch size 成正比
- 需要保存输出对应的梯度用以反向传播(链式法则的中间结果),模型输出不需要存储相应的动量信息(因为不需要执行优化)
举个例子,下面是一个计算图,输入 x,经过中间结果 z,然后得到最终变量 L
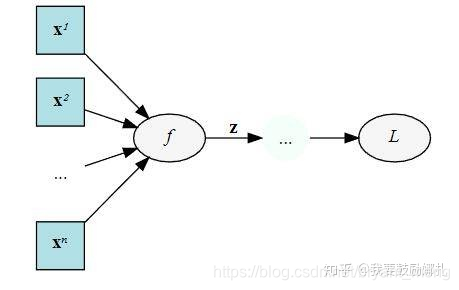
我们在 backward 的时候要求 L 对 x 的梯度,这个时候就需要在计算链 L 和 x 中间的 z:
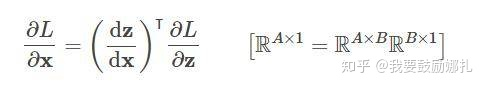
dz / dx 这个中间值当然要保留下来以用于计算
另外需要注意
- 输入(数据,图片)一般不需要计算梯度
- 神经网络的每一层输入输出都需要保存下来,用来反向传播,但是在某些特殊的情况下,我们可以不要保存输入。比如 ReLU,在 PyTorch 中,使用 nn.ReLU(inplace = True) 能将激活函数 ReLU 的输出直接覆盖保存于模型的输入之中,节省不少显存。感兴趣的读者可以思考一下,这时候是如何反向传播的(提示:y=relu(x) -> dx = dy.copy(); dx[y<=0]=0)
3.4、总结
总结一下,我们在总体的训练中,占用显存大概分以下几类:
- 模型中的参数(卷积层或其他有参数的层,参数指的是 trainable 的参数)
- 模型在计算时产生的中间参数(也就是输入图像在计算时每一层产生的输入和输出)
- backward 的时候产生的额外的中间参数(链式传播)
- 优化器在优化时产生的额外的模型参数
但其实,我们占用的显存空间为什么比我们理论计算的还要大,原因大概是因为深度学习框架一些额外的开销吧,不过如果通过上面公式,理论计算出来的显存和实际不会差太多的。
3.5、优化
优化除了算法层的优化,最基本的优化无非也就一下几点:
- 减少输入图像的尺寸
- 减少 batch,减少每次的输入图像数量
- 多使用下采样,池化层
- 一些神经网络层可以进行小优化,利用 relu 层中设置 inplace
- 购买显存更大的显卡
- 从深度学习框架上面进行优化
- 对于不需要 bp 的 forward,如 validation 请使用 torch.no_grad , 注意model.eval() 不等于 torch.no_grad() 请看如下讨论(Pytorch有什么节省显存的小技巧? - 郑哲东的回答 - 知乎)。
来自 ‘model.eval()’ vs ‘with torch.no_grad()’


测试时
with torch.no_grad():
测试代码
...
...
3.6、显存监控


3.7、显卡设置(指定用哪张卡)
单卡
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
多卡
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
命令行指定
CUDA_VISIBLE_DEVICES=0,1 python train.py
4、GPU 利用率
GPU 计算单元类似于 CPU 中的核,用来进行数值计算。
衡量计算量的单位是 flop: the number of floating-point multiplication-adds,浮点数先乘后加算一个 flop。计算能力越强大,速度越快。衡量计算能力的单位是 flops: 每秒能执行的 flop 数量

GPU 利用率低常见原因分析及优化(2022年08月16日)

- 数据加载
- 数据预处理
- 模型保存
- loss 计算
- 评估指标计算
- 日志打印
- 指标上报
- 进度上报
5、显存释放
参考 深度学习训练已经停止了,可GPU内存还在占用着,怎么办?
watch nvidia-smi 能看到 PID 号那就比较好说了,直接 kill -9 PID 就行
watch nvidia-smi看不到,重启,哈哈哈,当然可以
不过下面这条指令可以查看到
fuser -v /dev/nvidia*
然后 kill 掉对应的 PID,可能不止一个
pytorch 清除显存 torch.cuda.empty_cache()
或者
命令行 nvidia-smi --gpu-reset -i [gpu_id]
6、影响训练速度的因素
学习摘抄来自 不止GPU!这些硬件也影响着深度学习训练速度
CPU、内存、硬盘、GPU
(1) 数据流动路径
假设我们现在有一批图片集放在硬盘当中,待读取进内存送入GPU运算,那么一般会经历以下流程:
-
CPU发出读取指令,从硬盘中找到图片数据,并存到内存中;
-
CPU从内存中取出一批数据,转化为numpy array,并作数据预处理/增强操作,如翻转、平移、颜色变换等。处理完毕后送回内存。
-
CPU内存(后面简称内存)和GPU内存(后面简称显存)各开辟一块缓冲区,内存中的一个batch的数据通过PCIe通道传输到显存当中。
-
GPU核心从显存中获取数据进行并行计算,计算结果返回至显存中。
-
计算好的结果将从显存经过PCIe通道返回到内存。
这5个步骤涉及到几个影响数据传输速度的环节:
-
硬盘读取速度;(影响因素最大)
-
PCIe传输速度;
-
内存读写速度;
-
cpu频率。
(2)硬盘

(3)PCIe
内存中的数据通过PCIe总线传输到GPU显存当中,如果是单显卡的机器,大部分都能工作在PCIe 3.0 x16带宽下,此时的带宽为15.754GB/s。

当一个batch的数据(假设tensor shape: (32, 224, 224, 3))通过PCIe (3.0 x16)传输至GPU时,理论上所需时间为:2.44ms。(float 32的tensor的size 32×224×224×3×8≈0.0385GB,
0.0385
/
15.754
∗
1000
0.0385/15.754*1000
0.0385/15.754∗1000 ≈ 2.44)。
但目前市售的桌面级cpu(以英特尔酷睿系列的i7 cpu为例),CPU直连的PCIe通道一般只有16条,如果插了双GPU,那么只能工作在PCIe 3.0 x8带宽上(如果你的主板支持的话),那么理论延迟时间加倍。因此一般多卡机器如4卡、8卡、10卡,均最低使用双路工作站或服务器级别的CPU,如英特尔至强系列,此系列单U最低都能提供40条PCIe总线。
但这些延迟时间相比起GPU计算、IO等这些时间来说,其实影响甚微,加上还有软件层面的速度优化,这个延迟可以忽略不计,因此装机时不必太多纠结于PCIe通道数上。
(4)CPU频率

实际上,由于所有数据预处理的操作都在CPU上执行,因此CPU频率越高,生成图片的速度就越快,这样的差距也在情理之中。当机器拥有多显卡时,CPU喂数据的速度可能会成为整个系统的瓶颈。
(5)内存频率


(6)GPU
-
CUDA核心数
核心数越多意味着执行并行计算的量就更多,基本确定了一张显卡的算力 -
内存颗粒

-
TensorCore
TensorCore最早出现在Nvidia的Volta架构,用于加速深度学习经常需要的矩阵运算。当使用TensorCore时,我们需要从以往的单精度运算(float32)转换成为混合精度(float16+float32)计算,而TensorCore正是能加速这些混合精度运算。 -
浮点算力
浮点算力是最能反映显卡性能的指标,对于深度学习来说,单精度(float32)的运算最常见,因此最受关注的是float32的算力。而近来混合精度计算越来越受欢迎,float16的算力也越来越重要。至于int8一般用在要求极端速度的推理任务上。而float64一般在HPC应用中常用,所以基本可以忽略这一项。我们来看看几款Volta、Turing架构的显卡详细参数表:

7、动态图 vs 静态图
在边的层面,二者区别更明显。对于动态图,只有在调用 layer 的 forward 时,才知道当前 layer 的输入来自哪个 layer。当forward 调用结束,这个拓扑关系就没了。然后下一次运行调用 forward 的时候再建立一次。而静态图,在模型定义的时候,就已经把图的全局拓扑确定了。
TensorFlow and PyTorch, our two chosen frameworks, handle this computational graph differently. In TensorFlow, the graph is static. That means that we create and connect all the variables at the beginning, and initialize them into a static (unchanging) session. This session and graph persists and is reused: it is not rebuilt after each iteration of training, making it efficient. However, with a static graph, variable sizes have to be defined at the beginning, which can be non-convenient for some applications, such as NLP with variable length inputs.
On the contrary, PyTorch uses a dynamic graph. That means that the computational graph is built up dynamically, immediately after we declare variables. This graph is thus rebuilt after each iteration of training. Dynamic graphs are flexible and allow us modify and inspect the internals of the graph at any time. The main drawback is that it can take time to rebuild the graph. Either PyTorch or TensorFlow can be more efficient depending on the specific application and implementation.
附录A 、Use GPU to speed up training
测试下矩阵运算GPU与CPU的差别
A.1、导入tensorflow模块
import tensorflow as tf
import time
A.2、建立和执行计算图
默认用GPU跑
tf.reduce_sum 计算矩阵的和
#建立计算图
size=500
W = tf.random_normal([size, size],name='W') # 500,500
X = tf.random_normal([size, size],name='X') # 500,500
mul = tf.matmul(W, X,name='mul')
sum_result = tf.reduce_sum(mul,name='sum')# 矩阵内的值加总
# 执行计算图
with tf.Session() as sess:
result = sess.run(sum_result)
print('result=',result)
output
result= -10656.27
A.3、测试GPU与CPU性能的差别
def performanceTest(device_name,size):
with tf.device(device_name):
W = tf.random_normal([size, size],name='W')
X = tf.random_normal([size, size],name='X')
mul = tf.matmul(W, X,name='mul')
sum_result = tf.reduce_sum(mul,name='sum')
startTime = time.time()
# 使用 tf.ConfigProto 建立 session 的配置设置 tfconfig,传入参数 log_device_placement设置为True
tfconfig=tf.ConfigProto(log_device_placement=True)
with tf.Session(config=tfconfig) as sess:
result = sess.run(sum_result)
takeTimes=time.time() - startTime
print(device_name," size=",size,"Time:",takeTimes )
return takeTimes
调用
gpu_set=[];cpu_set=[];i_set=[]
for i in range(0,5001,500):
g=performanceTest("/gpu:0",i) # 0号GPU
c=performanceTest("/cpu:0",i)
gpu_set.append(g);cpu_set.append(c);i_set.append(i)
print("--")
output
/gpu:0 size= 0 Time: 0.14670062065124512
/cpu:0 size= 0 Time: 0.16228890419006348
--
/gpu:0 size= 500 Time: 0.16929364204406738
/cpu:0 size= 500 Time: 0.18462872505187988
--
/gpu:0 size= 1000 Time: 0.13805508613586426
/cpu:0 size= 1000 Time: 0.13151001930236816
--
/gpu:0 size= 1500 Time: 0.1536424160003662
/cpu:0 size= 1500 Time: 0.2314302921295166
--
/gpu:0 size= 2000 Time: 0.21573805809020996
/cpu:0 size= 2000 Time: 0.4350099563598633
--
/gpu:0 size= 2500 Time: 0.37288379669189453
/cpu:0 size= 2500 Time: 0.6350183486938477
--
/gpu:0 size= 3000 Time: 0.5283641815185547
/cpu:0 size= 3000 Time: 0.9774112701416016
--
/gpu:0 size= 3500 Time: 0.7861192226409912
/cpu:0 size= 3500 Time: 1.4520719051361084
--
/gpu:0 size= 4000 Time: 1.1301662921905518
/cpu:0 size= 4000 Time: 2.030012845993042
--
/gpu:0 size= 4500 Time: 1.5385856628417969
/cpu:0 size= 4500 Time: 2.7173430919647217
--
/gpu:0 size= 5000 Time: 2.0486159324645996
/cpu:0 size= 5000 Time: 3.6564781665802
--
GPU的RAM不够就把size设置小一些,可视化一下结果
%matplotlib inline
import matplotlib.pyplot as plt
fig = plt.gcf()
fig.set_size_inches(6,4)
plt.plot(i_set, gpu_set, label = 'gpu')
plt.plot(i_set, cpu_set, label = 'cpu')
plt.legend()
output

附录B
A.1、AI 计算框架 MindSpore

MindSpore(昇思 shēng) 是由华为于2019年8月推出的新一代全场景AI计算框架,2020年3月28日,华为宣布 MindSpore 正式开源


著名开源运动先驱人物 Eric Steven Raymond 曾经说过:Given enough eyeballs, all bugs are shallow
A.2、国产AI芯片
来自 一文了解十家主流国产AI芯片情况(4次删减精华版!)(2024年09月14日)
- 摩尔线程-服务器级全功能GPU及方案
- 海光DCU产品介绍
- 沐曦-打造全栈GPU芯片产品
- 寒武纪-AI芯片产品情况
- 天数智芯—通用GPU高端芯片
- 昆仑芯-产品成熟的国产AI芯片公司
- 壁仞科技-自主原创GPU芯片
- 燧原科技-云燧T20、T21和S60
- 太初元碁—异构众核的AI加速产品
- YYLX

A.3、电脑端 CPU 芯片制造厂商
一、英特尔(Intel)
- 简介:全球最大的半导体芯片制造商之一,其CPU品牌享誉全球,成为计算机行业的标杆。
- 产品系列:酷睿(Core)系列(如Core i9、Core i7等)、奔腾(Pentium)系列、至强(Xeon,主要用于数据中心和工作站)等。
- 应用领域:产品广泛应用于各个领域,从台式电脑到笔记本电脑,再到智能手机和平板电脑。
二、AMD(超威半导体)
- 简介:AMD是英特尔的主要竞争对手,也是全球第二大x86处理器制造商。
- 产品系列:锐龙(Ryzen,用于高性能台式机)、Epyc(用于数据中心)、Athlon和A系列(适用于商用和消费级桌面应用)等。
- 特点:AMD的CPU产品凭借卓越的性能、不断创新的技术以及高性价比,在高性能计算领域有着举足轻重的地位。
三、ARM
- 简介:一家专注于低功耗、高效能的处理器设计公司。
- 产品系列:Cortex-A(适用于移动设备和嵌入式系统)、Cortex-M(适用于低功耗、实时应用)、Cortex-R(适用于高性能、实时应用)等。
- 应用领域:CPU常被应用于移动设备、智能家居、汽车电子等领域。
四、IBM
- 简介:一家历史悠久、技术领先的科技公司。
- 产品系列:Power(用于高性能服务器和大型计算机)、zSeries(主要用于金融、保险等行业)等。
- 应用领域:CPU产品常被应用于高性能服务器、大型计算机等领域。
五、其他厂商
除了上述几家主要厂商外,还有一些其他知名的CPU芯片制造厂商,如三星、高通、英伟达、海力士、美光、博通、联发科技和海思等。这些厂商在CPU芯片制造领域也有着不俗的表现和市场份额。
- 三星:其Exynos系列处理器在智能手机和平板电脑等移动设备中应用广泛。
- 高通:骁龙(Snapdragon)系列处理器在移动领域具有极高的市场份额。
- 英伟达:虽然在CPU领域的热销型号不如其在GPU领域那么丰富,但Grace系列已经凭借其卓越的性能和创新设计,在市场上引起了热烈反响。
- 海力士和美光:这两家公司主要专注于DRAM和NAND闪存等存储解决方案的生产,虽然不直接涉足CPU生产,但其产品在提升CPU性能方面发挥着不可或缺的作用。
- 博通:其有线通信芯片被广泛应用于智能手机、电视、有线调制解调器和机顶盒等设备中。
- 联发科技:其“天玑”系列处理器在智能手机和平板电脑等移动设备中表现出色。
- 海思:作为华为旗下专注于芯片研发的高科技企业,其CPU产品在消费电子、通信和光器件等领域具有广泛的应用。
A.4、算力巨头
算力五大巨头
-
华为(供应商:拓维信息、常山北明)
-
腾讯(供应商:科华数据)
-
阿里(供应商:数据港、锐捷网络、润建股份、杭钢股份)
-
字节(供应商:光环新网、润泽科技、浪潮信息)
-
百度(供应商:奥飞数据、亚康股份)
附录C、显卡参数
英伟达(NVIDIA)发布的显卡型号众多,以下列举部分较为知名和经典的型号,但请注意由于篇幅限制无法涵盖所有:
一、GeForce系列(针对游戏和娱乐)
- RTX 40系列
- RTX 4090
- RTX 4080
- RTX 4070 Ti
- RTX 4070
- RTX 4070 SUPER
- RTX 4060 Ti
- RTX 4060(及后续可能的型号)
- RTX 30系列
- RTX 3090
- RTX 3080 Ti
- RTX 3080
- RTX 3070 Ti
- RTX 3070
- RTX 3060 Ti
- RTX 3060
- RTX 3050(及后续可能的型号)
- RTX 20系列
- RTX 2080 Ti
- RTX 2080 Super
- RTX 2080
- RTX 2070 Super
- RTX 2070
- RTX 2060 Super
- RTX 2060
- GTX 16系列(无光线追踪技术)
- GTX 1660 Super
- GTX 1660 Ti
- GTX 1660
- GTX 1650 Super
- GTX 1650
- GTX 10系列
- GTX 1080 Ti
- GTX 1080
- GTX 1070 Ti
- GTX 1070
- GTX 1060(包括3GB和6GB版本)
- GTX 1050 Ti
- GTX 1050
二、TITAN系列(发烧级显卡)
- GTX TITAN
- GTX TITAN Black
- GTX TITAN X
- TITAN V
- TITAN RTX
- 其他可能的TITAN系列显卡(如TITAN Z等)
三、Quadro系列(专业显卡,针对3D设计、视频制作等)
- Quadro RTX系列(如Quadro RTX 8000、Quadro RTX 6000等)
- Quadro P系列(如Quadro P6000、Quadro P5000等)
- 其他Quadro系列显卡(如Quadro M系列、K系列等)
四、Tesla系列(计算卡,针对数据中心和人工智能)
- Tesla V100
- Tesla P100
- Tesla K80
- Tesla K40
- 其他Tesla系列显卡
五、其他系列
- GeForce MX系列(针对轻薄笔记本电脑)
- GeForce GTX系列(早期型号,如GTX 980、GTX 970等)
- 其他可能已停产或不再更新的系列(如GTS系列、GT系列等)
- 参数查看:https://www.xincanshu.com/gpu/
- 显卡型号查看:linux服务器上查看显卡(nvidia)型号
https://admin.pci-ids.ucw.cz/mods/PC/10de?action=help?help=pci


对话框中输入 1f50
10系列20系列30系列显卡的发布时间多少? - 尤娜Yuna的回答 - 知乎
https://www.zhihu.com/question/434191939/answer/1620590375



2024.03
英伟达 GTC 开发者大会 GB200

因特尔 Gaudi3 碾压 H100
【NVIDIA GeForce GTX 1080 Ti】
GTX1080Ti是 NVIDIA 公司于2017年3月1日在旧金山发布的显卡产品 。



【NVIDIA GeForce RTX 2080 Ti】
RTX 2080、RTX 2080Ti将会在2018年9月20日正式发售,售价分别为699美元(约合人民币4793元)和999美元(约合人民币6850元)。



【NVIDIA GeForce RTX 3090】
NVIDIA GeForce RTX 3090是一款NVIDIA系列的显卡。 于2020年9月2日正式发布,并于2020年9月24日开始发货



【NVIDIA GeForce RTX 3080 Ti】
NVIDIA GeForce RTX 3080 Ti是NVIDIA发布的显卡,2021年6月3日上市。



【NVIDIA TITAN Xp】
2016年10月



附录D、接口


















 167
167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









