









主要给大家展示下强大的图片风格迁移,也就是图生图,十分有趣
本文介绍的pytorch 版本,且精简过的,因此十分简单易懂,大家可以自行复现
大佬的github:cyclegan
论文:arxiv
介绍
CycleGAN,即循环生成对抗网络,出自发表于 ICCV17 的论文《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》,和它的兄长Pix2Pix(均为朱大神作品)一样,用于图像风格迁移任务。以前的GAN都是单向生成,CycleGAN为了突破Pix2Pix对数据集图片一一对应的限制,采用了双向循环生成的结构,因此得名CycleGAN。
简单来说就是两个生成器,两个辨别器,简单易懂,详细的推荐大家取看看论文
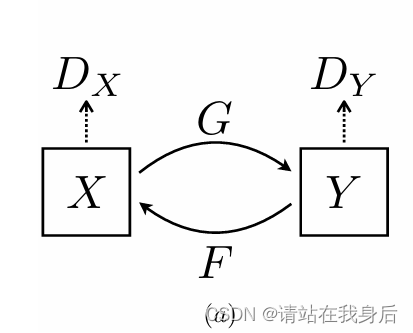

不多说了,直接进入代码部分
代码
首先还是数据提取部分,分开讲解,整体代码放在最后面。
因为我相信大家下载下来肯定也不是去看什么马转化为斑马,这里简单介绍,大家替换成自己的数据集即可
另外一点,这类图生图的算法最大的优点就在于不需要成对的图片,举例,A领域:真人照片,B领域:动漫图片 ——》转化风格就是真人转动漫头像。是不是很厉害
transforms_ = [ transforms.Resize(int(opt.size*1.12), Image.BICUBIC),
transforms.RandomCrop(opt.size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)) ]
dataloader = DataLoader(ImageDataset(opt.dataroot, transforms_=transforms_, unaligned=True),
batch_size=opt.batchSize, shuffle=True, num_workers=opt.n_cpu)运用到torch里面的转换,大家可以自行修改参数
import glob
import random
import os
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, unaligned=False, mode='train'):
self.transform = transforms.Compose(transforms_)
self.unaligned = unaligned
self.files_A = sorted(glob.glob(os.path.join(root, '%s/A' % mode) + '/*.*'))
self.files_B = sorted(glob.glob(os.path.join(root, '%s/B' % mode) + '/*.*'))
def __getitem__(self, index):
item_A = self.transform(Image.open(self.files_A[index % len(self.files_A)]))
if self.unaligned:
item_B = self.transform(Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]))
else:
item_B = self.transform(Image.open(self.files_B[index % len(self.files_B)]))
return {'A': item_A, 'B': item_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))可以看到,数据集的提取没有什么花里胡哨,就是一个A领域,一个B领域,大家主要改下地址就行
# Loss plot
logger = Logger(opt.n_epochs, len(dataloader))网络构建部分
1、构建两个生成器两个辨别器,扔到gpu里面
netG_A2B = Generator(opt.input_nc, opt.output_nc)
netG_B2A = Generator(opt.output_nc, opt.input_nc)
netD_A = Discriminator(opt.input_nc)
netD_B = Discriminator(opt.output_nc)
if opt.cuda:
netG_A2B.cuda()
netG_B2A.cuda()
netD_A.cuda()
netD_B.cuda()2、应用初始化权重
netG_A2B.apply(weights_init_normal)
netG_B2A.apply(weights_init_normal)
netD_A.apply(weights_init_normal)
netD_B.apply(weights_init_normal)3、加载损失函数,这里就是三个损失,两个l1 一个mse
# Lossess
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
4、加载优化器和学习规划
# Optimizers & LR schedulers
optimizer_G = torch.optim.Adam(itertools.chain(netG_A2B.parameters(), netG_B2A.parameters()),
lr=opt.lr, betas=(0.5, 0.999))
optimizer_D_A = torch.optim.Adam(netD_A.parameters(), lr=opt.lr, betas=(0.5, 0.999))
optimizer_D_B = torch.optim.Adam(netD_B.parameters(), lr=opt.lr, betas=(0.5, 0.999))
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(optimizer_D_A, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(optimizer_D_B, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)5、提前订好物理存储,我反正平时懒得这么干
# Inputs & targets memory allocation
Tensor = torch.cuda.FloatTensor if opt.cuda else torch.Tensor
input_A = Tensor(opt.batchSize, opt.input_nc, opt.size, opt.size)
input_B = Tensor(opt.batchSize, opt.output_nc, opt.size, opt.size)
target_real = Variable(Tensor(opt.batchSize).fill_(1.0), requires_grad=False)
target_fake = Variable(Tensor(opt.batchSize).fill_(0.0), requires_grad=False)
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()训练部分
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):1、初始优化器和参数
# Set model input
real_A = Variable(input_A.copy_(batch['A']))
real_B = Variable(input_B.copy_(batch['B']))
###### Generators A2B and B2A ######
optimizer_G.zero_grad()
2、生成器
###### Generators A2B and B2A ######
optimizer_G.zero_grad()
# Identity loss
# G_A2B(B) should equal B if real B is fed
same_B = netG_A2B(real_B)
loss_identity_B = criterion_identity(same_B, real_B)*5.0
# G_B2A(A) should equal A if real A is fed
same_A = netG_B2A(real_A)
loss_identity_A = criterion_identity(same_A, real_A)*5.0
# GAN loss
fake_B = netG_A2B(real_A)
pred_fake = netD_B(fake_B)
loss_GAN_A2B = criterion_GAN(pred_fake, target_real)
fake_A = netG_B2A(real_B)
pred_fake = netD_A(fake_A)
loss_GAN_B2A = criterion_GAN(pred_fake, target_real)
# Cycle loss
recovered_A = netG_B2A(fake_B)
loss_cycle_ABA = criterion_cycle(recovered_A, real_A)*10.0
recovered_B = netG_A2B(fake_A)
loss_cycle_BAB = criterion_cycle(recovered_B, real_B)*10.0
# Total loss
loss_G = loss_identity_A + loss_identity_B + loss_GAN_A2B + loss_GAN_B2A + loss_cycle_ABA + loss_cycle_BAB
loss_G.backward()
optimizer_G.step()3、辨别器
###### Discriminator A ######
optimizer_D_A.zero_grad()
# Real loss
pred_real = netD_A(real_A)
loss_D_real = criterion_GAN(pred_real, target_real)
# Fake loss
fake_A = fake_A_buffer.push_and_pop(fake_A)
pred_fake = netD_A(fake_A.detach())
loss_D_fake = criterion_GAN(pred_fake, target_fake)
# Total loss
loss_D_A = (loss_D_real + loss_D_fake)*0.5
loss_D_A.backward()
optimizer_D_A.step()
###################################
###### Discriminator B ######
optimizer_D_B.zero_grad()
# Real loss
pred_real = netD_B(real_B)
loss_D_real = criterion_GAN(pred_real, target_real)
# Fake loss
fake_B = fake_B_buffer.push_and_pop(fake_B)
pred_fake = netD_B(fake_B.detach())
loss_D_fake = criterion_GAN(pred_fake, target_fake)
# Total loss
loss_D_B = (loss_D_real + loss_D_fake)*0.5
loss_D_B.backward()
optimizer_D_B.step() # Progress report (http://localhost:8097)
logger.log({'loss_G': loss_G, 'loss_G_identity': (loss_identity_A + loss_identity_B), 'loss_G_GAN': (loss_GAN_A2B + loss_GAN_B2A),
'loss_G_cycle': (loss_cycle_ABA + loss_cycle_BAB), 'loss_D': (loss_D_A + loss_D_B)},
images={'real_A': real_A, 'real_B': real_B, 'fake_A': fake_A, 'fake_B': fake_B})优化
# Update learning rates
lr_scheduler_G.step()
lr_scheduler_D_A.step()
lr_scheduler_D_B.step()
# Save models checkpoints
torch.save(netG_A2B.state_dict(), 'output/netG_A2B.pth')
torch.save(netG_B2A.state_dict(), 'output/netG_B2A.pth')
torch.save(netD_A.state_dict(), 'output/netD_A.pth')
torch.save(netD_B.state_dict(), 'output/netD_B.pth')结束
说实话,就是很简单的循环的思路,相信大家一看就懂,多试试哈,有问题问我
整体代码
train.py
#!/usr/bin/python3
import argparse
import itertools
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.autograd import Variable
from PIL import Image
import torch
from models import Generator
from models import Discriminator
from utils import ReplayBuffer
from utils import LambdaLR
from utils import Logger
from utils import weights_init_normal
from datasets import ImageDataset
parser = argparse.ArgumentParser()
parser.add_argument('--epoch', type=int, default=0, help='starting epoch')
parser.add_argument('--n_epochs', type=int, default=200, help='number of epochs of training')
parser.add_argument('--batchSize', type=int, default=1, help='size of the batches')
parser.add_argument('--dataroot', type=str, default='datasets/horse2zebra/', help='root directory of the dataset')
parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate')
parser.add_argument('--decay_epoch', type=int, default=100, help='epoch to start linearly decaying the learning rate to 0')
parser.add_argument('--size', type=int, default=256, help='size of the data crop (squared assumed)')
parser.add_argument('--input_nc', type=int, default=3, help='number of channels of input data')
parser.add_argument('--output_nc', type=int, default=3, help='number of channels of output data')
parser.add_argument('--cuda', action='store_true', help='use GPU computation')
parser.add_argument('--n_cpu', type=int, default=8, help='number of cpu threads to use during batch generation')
opt = parser.parse_args()
print(opt)
if torch.cuda.is_available() and not opt.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda")
###### Definition of variables ######
# Networks
netG_A2B = Generator(opt.input_nc, opt.output_nc)
netG_B2A = Generator(opt.output_nc, opt.input_nc)
netD_A = Discriminator(opt.input_nc)
netD_B = Discriminator(opt.output_nc)
if opt.cuda:
netG_A2B.cuda()
netG_B2A.cuda()
netD_A.cuda()
netD_B.cuda()
netG_A2B.apply(weights_init_normal)
netG_B2A.apply(weights_init_normal)
netD_A.apply(weights_init_normal)
netD_B.apply(weights_init_normal)
# Lossess
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
# Optimizers & LR schedulers
optimizer_G = torch.optim.Adam(itertools.chain(netG_A2B.parameters(), netG_B2A.parameters()),
lr=opt.lr, betas=(0.5, 0.999))
optimizer_D_A = torch.optim.Adam(netD_A.parameters(), lr=opt.lr, betas=(0.5, 0.999))
optimizer_D_B = torch.optim.Adam(netD_B.parameters(), lr=opt.lr, betas=(0.5, 0.999))
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(optimizer_D_A, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(optimizer_D_B, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
# Inputs & targets memory allocation
Tensor = torch.cuda.FloatTensor if opt.cuda else torch.Tensor
input_A = Tensor(opt.batchSize, opt.input_nc, opt.size, opt.size)
input_B = Tensor(opt.batchSize, opt.output_nc, opt.size, opt.size)
target_real = Variable(Tensor(opt.batchSize).fill_(1.0), requires_grad=False)
target_fake = Variable(Tensor(opt.batchSize).fill_(0.0), requires_grad=False)
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()
# Dataset loader
transforms_ = [ transforms.Resize(int(opt.size*1.12), Image.BICUBIC),
transforms.RandomCrop(opt.size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)) ]
dataloader = DataLoader(ImageDataset(opt.dataroot, transforms_=transforms_, unaligned=True),
batch_size=opt.batchSize, shuffle=True, num_workers=opt.n_cpu)
# Loss plot
logger = Logger(opt.n_epochs, len(dataloader))
###################################
###### Training ######
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Set model input
real_A = Variable(input_A.copy_(batch['A']))
real_B = Variable(input_B.copy_(batch['B']))
###### Generators A2B and B2A ######
optimizer_G.zero_grad()
# Identity loss
# G_A2B(B) should equal B if real B is fed
same_B = netG_A2B(real_B)
loss_identity_B = criterion_identity(same_B, real_B)*5.0
# G_B2A(A) should equal A if real A is fed
same_A = netG_B2A(real_A)
loss_identity_A = criterion_identity(same_A, real_A)*5.0
# GAN loss
fake_B = netG_A2B(real_A)
pred_fake = netD_B(fake_B)
loss_GAN_A2B = criterion_GAN(pred_fake, target_real)
fake_A = netG_B2A(real_B)
pred_fake = netD_A(fake_A)
loss_GAN_B2A = criterion_GAN(pred_fake, target_real)
# Cycle loss
recovered_A = netG_B2A(fake_B)
loss_cycle_ABA = criterion_cycle(recovered_A, real_A)*10.0
recovered_B = netG_A2B(fake_A)
loss_cycle_BAB = criterion_cycle(recovered_B, real_B)*10.0
# Total loss
loss_G = loss_identity_A + loss_identity_B + loss_GAN_A2B + loss_GAN_B2A + loss_cycle_ABA + loss_cycle_BAB
loss_G.backward()
optimizer_G.step()
###################################
###### Discriminator A ######
optimizer_D_A.zero_grad()
# Real loss
pred_real = netD_A(real_A)
loss_D_real = criterion_GAN(pred_real, target_real)
# Fake loss
fake_A = fake_A_buffer.push_and_pop(fake_A)
pred_fake = netD_A(fake_A.detach())
loss_D_fake = criterion_GAN(pred_fake, target_fake)
# Total loss
loss_D_A = (loss_D_real + loss_D_fake)*0.5
loss_D_A.backward()
optimizer_D_A.step()
###################################
###### Discriminator B ######
optimizer_D_B.zero_grad()
# Real loss
pred_real = netD_B(real_B)
loss_D_real = criterion_GAN(pred_real, target_real)
# Fake loss
fake_B = fake_B_buffer.push_and_pop(fake_B)
pred_fake = netD_B(fake_B.detach())
loss_D_fake = criterion_GAN(pred_fake, target_fake)
# Total loss
loss_D_B = (loss_D_real + loss_D_fake)*0.5
loss_D_B.backward()
optimizer_D_B.step()
###################################
# Progress report (http://localhost:8097)
logger.log({'loss_G': loss_G, 'loss_G_identity': (loss_identity_A + loss_identity_B), 'loss_G_GAN': (loss_GAN_A2B + loss_GAN_B2A),
'loss_G_cycle': (loss_cycle_ABA + loss_cycle_BAB), 'loss_D': (loss_D_A + loss_D_B)},
images={'real_A': real_A, 'real_B': real_B, 'fake_A': fake_A, 'fake_B': fake_B})
# Update learning rates
lr_scheduler_G.step()
lr_scheduler_D_A.step()
lr_scheduler_D_B.step()
# Save models checkpoints
torch.save(netG_A2B.state_dict(), 'output/netG_A2B.pth')
torch.save(netG_B2A.state_dict(), 'output/netG_B2A.pth')
torch.save(netD_A.state_dict(), 'output/netD_A.pth')
torch.save(netD_B.state_dict(), 'output/netD_B.pth')
###################################
datasets.py
import glob
import random
import os
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, unaligned=False, mode='train'):
self.transform = transforms.Compose(transforms_)
self.unaligned = unaligned
self.files_A = sorted(glob.glob(os.path.join(root, '%s/A' % mode) + '/*.*'))
self.files_B = sorted(glob.glob(os.path.join(root, '%s/B' % mode) + '/*.*'))
def __getitem__(self, index):
item_A = self.transform(Image.open(self.files_A[index % len(self.files_A)]))
if self.unaligned:
item_B = self.transform(Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]))
else:
item_B = self.transform(Image.open(self.files_B[index % len(self.files_B)]))
return {'A': item_A, 'B': item_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))model.py
import torch.nn as nn
import torch.nn.functional as F
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
conv_block = [ nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features) ]
self.conv_block = nn.Sequential(*conv_block)
def forward(self, x):
return x + self.conv_block(x)
class Generator(nn.Module):
def __init__(self, input_nc, output_nc, n_residual_blocks=9):
super(Generator, self).__init__()
# Initial convolution block
model = [ nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, 64, 7),
nn.InstanceNorm2d(64),
nn.ReLU(inplace=True) ]
# Downsampling
in_features = 64
out_features = in_features*2
for _ in range(2):
model += [ nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True) ]
in_features = out_features
out_features = in_features*2
# Residual blocks
for _ in range(n_residual_blocks):
model += [ResidualBlock(in_features)]
# Upsampling
out_features = in_features//2
for _ in range(2):
model += [ nn.ConvTranspose2d(in_features, out_features, 3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True) ]
in_features = out_features
out_features = in_features//2
# Output layer
model += [ nn.ReflectionPad2d(3),
nn.Conv2d(64, output_nc, 7),
nn.Tanh() ]
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
class Discriminator(nn.Module):
def __init__(self, input_nc):
super(Discriminator, self).__init__()
# A bunch of convolutions one after another
model = [ nn.Conv2d(input_nc, 64, 4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(64, 128, 4, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(128, 256, 4, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(256, 512, 4, padding=1),
nn.InstanceNorm2d(512),
nn.LeakyReLU(0.2, inplace=True) ]
# FCN classification layer
model += [nn.Conv2d(512, 1, 4, padding=1)]
self.model = nn.Sequential(*model)
def forward(self, x):
x = self.model(x)
# Average pooling and flatten
return F.avg_pool2d(x, x.size()[2:]).view(x.size()[0], -1)
utils.py
import random
import time
import datetime
import sys
from torch.autograd import Variable
import torch
from visdom import Visdom
import numpy as np
def tensor2image(tensor):
image = 127.5*(tensor[0].cpu().float().numpy() + 1.0)
if image.shape[0] == 1:
image = np.tile(image, (3,1,1))
return image.astype(np.uint8)
class Logger():
def __init__(self, n_epochs, batches_epoch):
self.viz = Visdom()
self.n_epochs = n_epochs
self.batches_epoch = batches_epoch
self.epoch = 1
self.batch = 1
self.prev_time = time.time()
self.mean_period = 0
self.losses = {}
self.loss_windows = {}
self.image_windows = {}
def log(self, losses=None, images=None):
self.mean_period += (time.time() - self.prev_time)
self.prev_time = time.time()
sys.stdout.write('\rEpoch %03d/%03d [%04d/%04d] -- ' % (self.epoch, self.n_epochs, self.batch, self.batches_epoch))
for i, loss_name in enumerate(losses.keys()):
if loss_name not in self.losses:
self.losses[loss_name] = losses[loss_name].data[0]
else:
self.losses[loss_name] += losses[loss_name].data[0]
if (i+1) == len(losses.keys()):
sys.stdout.write('%s: %.4f -- ' % (loss_name, self.losses[loss_name]/self.batch))
else:
sys.stdout.write('%s: %.4f | ' % (loss_name, self.losses[loss_name]/self.batch))
batches_done = self.batches_epoch*(self.epoch - 1) + self.batch
batches_left = self.batches_epoch*(self.n_epochs - self.epoch) + self.batches_epoch - self.batch
sys.stdout.write('ETA: %s' % (datetime.timedelta(seconds=batches_left*self.mean_period/batches_done)))
# Draw images
for image_name, tensor in images.items():
if image_name not in self.image_windows:
self.image_windows[image_name] = self.viz.image(tensor2image(tensor.data), opts={'title':image_name})
else:
self.viz.image(tensor2image(tensor.data), win=self.image_windows[image_name], opts={'title':image_name})
# End of epoch
if (self.batch % self.batches_epoch) == 0:
# Plot losses
for loss_name, loss in self.losses.items():
if loss_name not in self.loss_windows:
self.loss_windows[loss_name] = self.viz.line(X=np.array([self.epoch]), Y=np.array([loss/self.batch]),
opts={'xlabel': 'epochs', 'ylabel': loss_name, 'title': loss_name})
else:
self.viz.line(X=np.array([self.epoch]), Y=np.array([loss/self.batch]), win=self.loss_windows[loss_name], update='append')
# Reset losses for next epoch
self.losses[loss_name] = 0.0
self.epoch += 1
self.batch = 1
sys.stdout.write('\n')
else:
self.batch += 1
class ReplayBuffer():
def __init__(self, max_size=50):
assert (max_size > 0), 'Empty buffer or trying to create a black hole. Be careful.'
self.max_size = max_size
self.data = []
def push_and_pop(self, data):
to_return = []
for element in data.data:
element = torch.unsqueeze(element, 0)
if len(self.data) < self.max_size:
self.data.append(element)
to_return.append(element)
else:
if random.uniform(0,1) > 0.5:
i = random.randint(0, self.max_size-1)
to_return.append(self.data[i].clone())
self.data[i] = element
else:
to_return.append(element)
return Variable(torch.cat(to_return))
class LambdaLR():
def __init__(self, n_epochs, offset, decay_start_epoch):
assert ((n_epochs - decay_start_epoch) > 0), "Decay must start before the training session ends!"
self.n_epochs = n_epochs
self.offset = offset
self.decay_start_epoch = decay_start_epoch
def step(self, epoch):
return 1.0 - max(0, epoch + self.offset - self.decay_start_epoch)/(self.n_epochs - self.decay_start_epoch)
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
torch.nn.init.normal(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm2d') != -1:
torch.nn.init.normal(m.weight.data, 1.0, 0.02)
torch.nn.init.constant(m.bias.data, 0.0)
附上test,我自己没用过他的
#!/usr/bin/python3
import argparse
import sys
import os
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torch.autograd import Variable
import torch
from models import Generator
from datasets import ImageDataset
parser = argparse.ArgumentParser()
parser.add_argument('--batchSize', type=int, default=1, help='size of the batches')
parser.add_argument('--dataroot', type=str, default='datasets/horse2zebra/', help='root directory of the dataset')
parser.add_argument('--input_nc', type=int, default=3, help='number of channels of input data')
parser.add_argument('--output_nc', type=int, default=3, help='number of channels of output data')
parser.add_argument('--size', type=int, default=256, help='size of the data (squared assumed)')
parser.add_argument('--cuda', action='store_true', help='use GPU computation')
parser.add_argument('--n_cpu', type=int, default=8, help='number of cpu threads to use during batch generation')
parser.add_argument('--generator_A2B', type=str, default='output/netG_A2B.pth', help='A2B generator checkpoint file')
parser.add_argument('--generator_B2A', type=str, default='output/netG_B2A.pth', help='B2A generator checkpoint file')
opt = parser.parse_args()
print(opt)
if torch.cuda.is_available() and not opt.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda")
###### Definition of variables ######
# Networks
netG_A2B = Generator(opt.input_nc, opt.output_nc)
netG_B2A = Generator(opt.output_nc, opt.input_nc)
if opt.cuda:
netG_A2B.cuda()
netG_B2A.cuda()
# Load state dicts
netG_A2B.load_state_dict(torch.load(opt.generator_A2B))
netG_B2A.load_state_dict(torch.load(opt.generator_B2A))
# Set model's test mode
netG_A2B.eval()
netG_B2A.eval()
# Inputs & targets memory allocation
Tensor = torch.cuda.FloatTensor if opt.cuda else torch.Tensor
input_A = Tensor(opt.batchSize, opt.input_nc, opt.size, opt.size)
input_B = Tensor(opt.batchSize, opt.output_nc, opt.size, opt.size)
# Dataset loader
transforms_ = [ transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)) ]
dataloader = DataLoader(ImageDataset(opt.dataroot, transforms_=transforms_, mode='test'),
batch_size=opt.batchSize, shuffle=False, num_workers=opt.n_cpu)
###################################
###### Testing######
# Create output dirs if they don't exist
if not os.path.exists('output/A'):
os.makedirs('output/A')
if not os.path.exists('output/B'):
os.makedirs('output/B')
for i, batch in enumerate(dataloader):
# Set model input
real_A = Variable(input_A.copy_(batch['A']))
real_B = Variable(input_B.copy_(batch['B']))
# Generate output
fake_B = 0.5*(netG_A2B(real_A).data + 1.0)
fake_A = 0.5*(netG_B2A(real_B).data + 1.0)
# Save image files
save_image(fake_A, 'output/A/%04d.png' % (i+1))
save_image(fake_B, 'output/B/%04d.png' % (i+1))
sys.stdout.write('\rGenerated images %04d of %04d' % (i+1, len(dataloader)))
sys.stdout.write('\n')
###################################















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









