







YB菜菜的机器学习自学之路(八)——基于keras的初级深度学习框架
前提说明
(1)网址https://playground.tensorflow.org是著名的rensorflow游乐场,其提供了一些典型数据,并通过“+”,“-”号搭建神经网络搭建模型,用可视化图输出结果,观察最后的学习结果。
(2)通常隐藏层超过三层的学习网络被称为深度神经网络。
(3)MNIST数据集是从NIST的两个手写数字数据集,我们以mnist为对象,搭建基于keras的深度学习网络来进行测试
(4)不知道为什么,我能运行成像 但是有三个红色"警告"?, 假如有哪位大神,不小心看到我整理的比较粗糙的笔记,并且愿意指导萌新,麻烦指导一下,谢谢。
1. 训练集和测试集
训练集: 我们在训练时使用的数据集称为训练集,我们希望在训练集上的准确率很高,这意味模型拟合效果很好。
测试集: 在训练集之外的新的数据,这些数据称为测试集。当模型训练好后我们会拿一些新的数据来测试模型,观察他的好坏,我们希望在测试集上的准确率也很高。测试集高就证明该模型的泛化能力强,这也是我们希望的。
欠拟合: 训练集准确度低,比如用一个很简单的神经元模型去拟合复杂数据。
过拟合: 测试集准确度高,测试集准确低。 用过分复杂的模型去拟合简单的数据。
2. mnist数据集简单介绍
由于MNIST数据集非常著名,所以已经有许多深度学习框架已经内置了mnist数据集并且有相关的函数直接读取并划分数据集。
在keras框架中,我们可以通过代码调用和观察:
from keras.datasets import mnist
# 导入mnist中的训练集和测试集
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
# mnist的数据格式,类比matlab中的size
print("X_train.shape:"+str(X_train.shape))
print("Y_train.shape:"+str(Y_train.shape))
print("X_test.shape:"+str(X_test.shape))
print("Y_test.shape:"+str(Y_test.shape))
运行结果:
X_train.shape:(60000, 28, 28)
Y_train.shape:(60000,)
X_test.shape:(10000, 28, 28)
Y_test.shape:(10000,)
X_train和X_test 说明,在keras中,内置了6万个训练集和1万个测试集。每一个图像的大小是:28*28。
Y_train和Y_test 是6万和1万的元素组,每个元素的值代表train中对应位置的图片类别,在0-9之间。
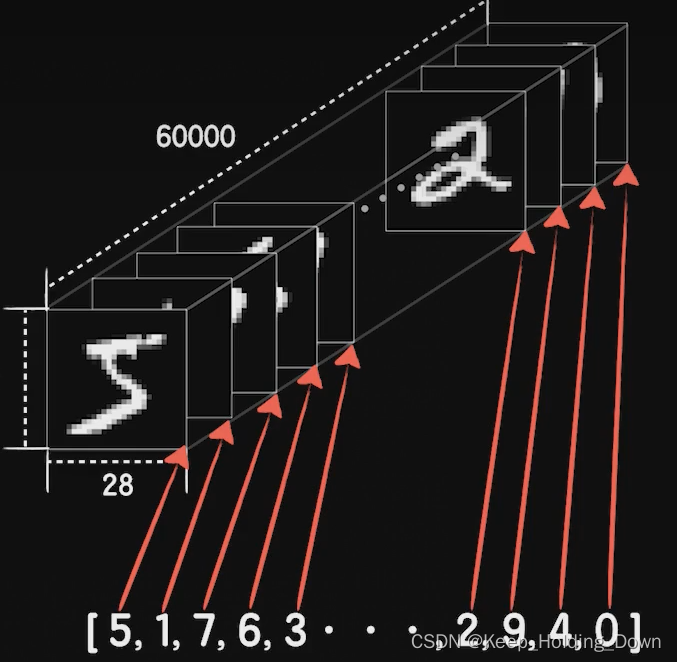
图1 MNIST训练集格式示意图
3.基于keras框架,利用全链接层搭建深度学习网络对MNIST训练
3.1 数据导入与one-hot编码
因为MNIST的数据是一个2828的图像像素点,因此我们要把他从矩形装的图像转成一个数组,如图2所示。
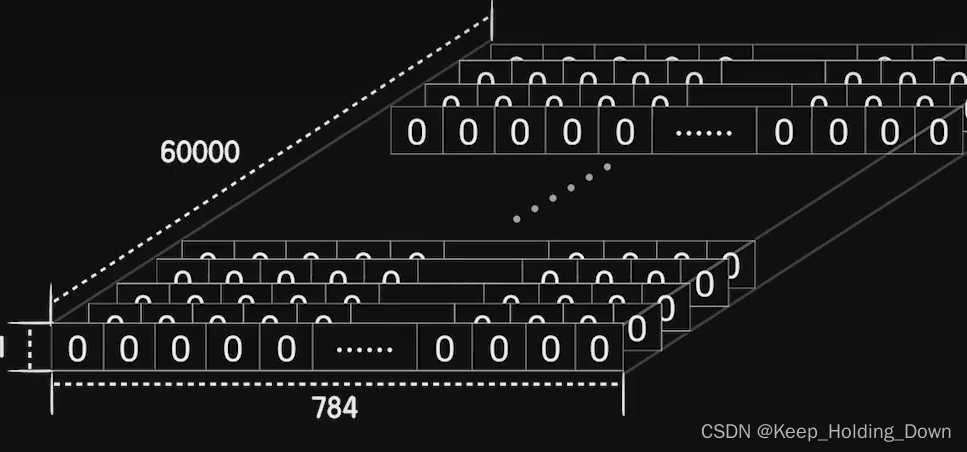
图2 将2828的矩形像素数据转成一组向量
# 60000个数据集,28*28
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
one-hot编码
在前文我们的二分类问题不同,在MNIST中输出不再是要么是1要么是0,而是变成0-9,即有10种分类。为例更好的表示0-9以及增强他们直接的区分程度,选择one-hot编码。比如用【1 0 0 0 0 0 0 0 0 0】表示“1”,用【0 1 0 0 0 0 0 0 0 0】表示“2”. 在这种情况下既可以很好的表示输出0-9的结果,并且每个结果之前存在巨大的差异,有利于识别。
因此:
Y_train = to_categorical(Y_train, 10)
Y_test = to_categorical(Y_test, 10)
3.2 创建模型
model = Sequential()
3.3创建神经元
3.3.1 输入层构建
model.add(Dense(units=256, activation='relu', input_dim=784))
因为MNIST数据相对复杂,为了提高准确度,我们提高每一层的神经元数,即units =256
选择激活函数activation=‘relu’。 relu是一种比sigmoid更常用于深度网络种的激活函数,其最大的优点是防止梯度消失。
因为输出数据每次输入一个图像的数据量,即28*28=784,所以input_dim=784。
3.3.2 增加中间的隐藏层
model.add(Dense(units=256, activation='relu'))
model.add(Dense(units=256, activation='relu'))
增加2个隐藏层 使得整个深度为3,即为深度学习
3.3.4 构建输出层
model.add(Dense(units=10, activation='softmax'))
因为one-hot编码,输出不再是单独的0或者1,因此一个神经元是无法表示十种类型,因此输出层需要设置为10,正好匹配one-hot编码位数。
同时,sigmoid激活函数也不适用于多输出情况,这里采用softmax激活函数,其特点是,softmax输出的结果是评估这个可能性的概率,概率最大的输出就意味着预测结果是该输出的类别。并且所有输出的结果概率之和为1,而不会超过1。
3.4 构建反向传播
model.compile(loss='categorical_crossentropy', optimizer=SGD(learning_rate=0.05), metrics=['accuracy'])
在之前代价函数一直采用mean_squared_error,即均方差代价函数,但是这个对分类问题不太合适
这里改成categorical_crossentropy 交叉熵代价函数
3.5开始训练
model.fit(X_train, Y_train, epochs=5000, batch_size=1000)
3.6 评估结果
loss, accuracy = model.evaluate(X_test, Y_test)
最后训练集准确率基本100%
测试集在97%以上















 5750
5750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









