









转载请注明:http://blog.csdn.net/c602273091/article/details/54288285
大纲

设计参数更新、学习率设置、dropout、梯度检测、模型集成等等方面。
参数更新
在计算梯度下降的时候,我们采用的是如下图所示的算子进行更新。
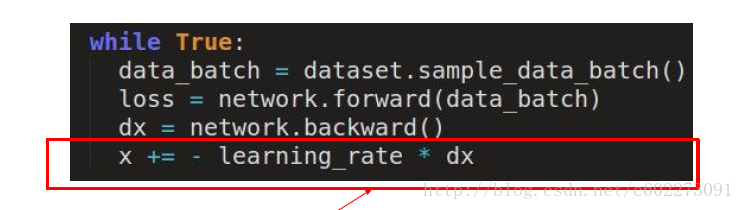
这种方法是普通的SGD梯度下降方法,在优化的过程中,它会发生震荡。
Momentum Update
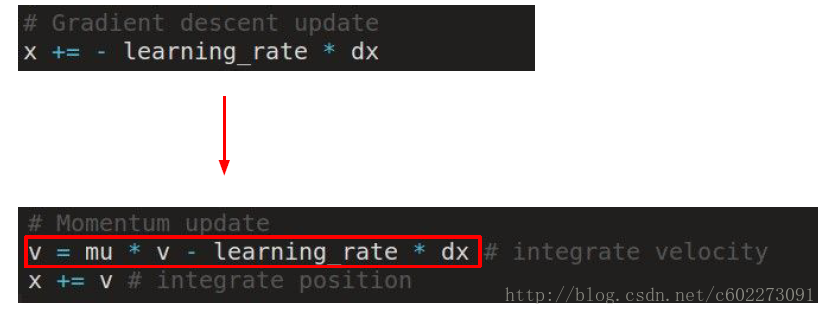
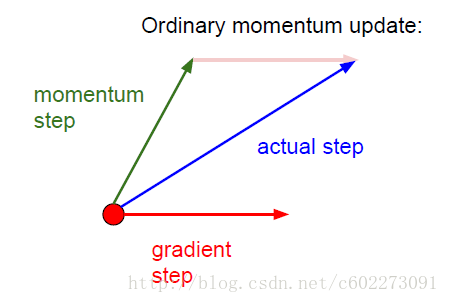
这里的v初始化为0,mu取0.5,0.9,0.99等等。
Nesterov Momentum update(NAG)
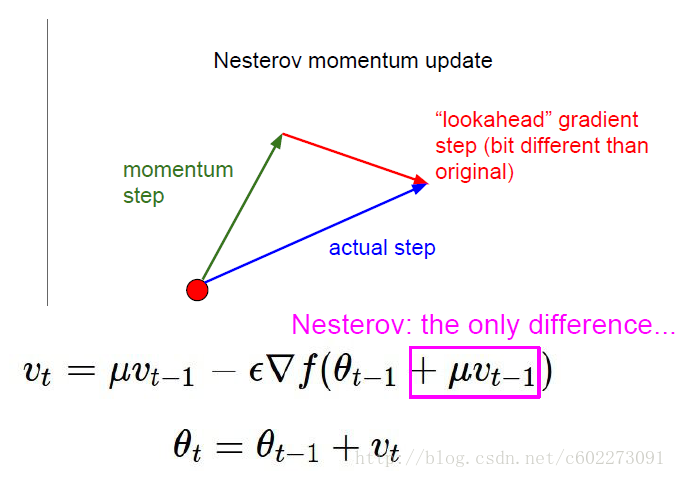
把 vt−1 考虑到了梯度计算里面。
为了让公式更加好看,然后就转化成下面的形式:

AdaGrad update

RMSProp update
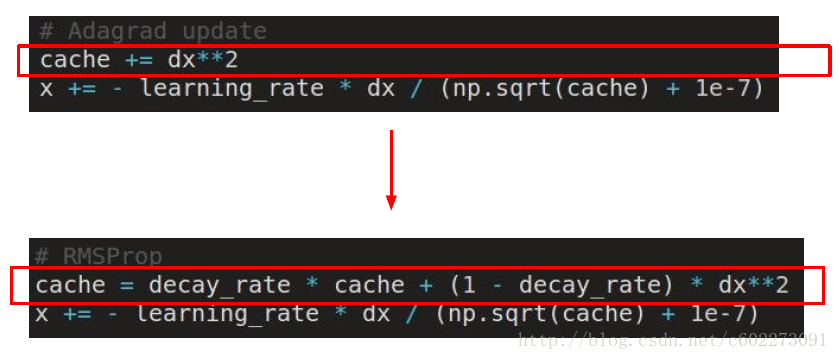
Adam update
把上面两种结合起来。


L-BFGS
full-batch的训练。使用二阶泰勒展开近似得到更新的式子。

regularization(dropout)
在forward pass的过程中,随机设置神经元的权重为0.
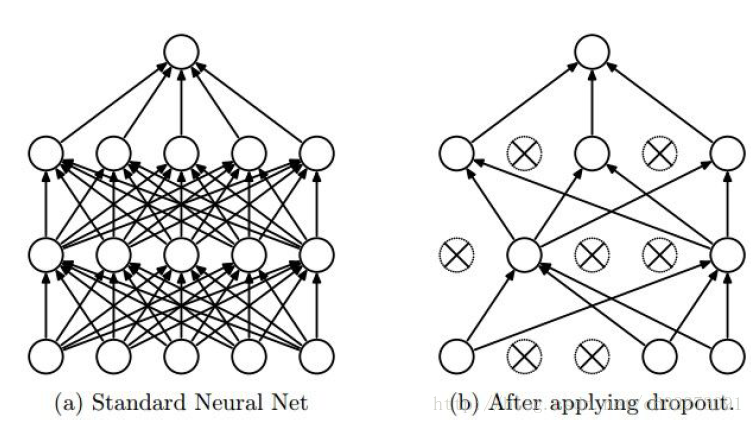
dropout以后,计算得到的score需要做一个调整。
两种调整的方法:


Convolution
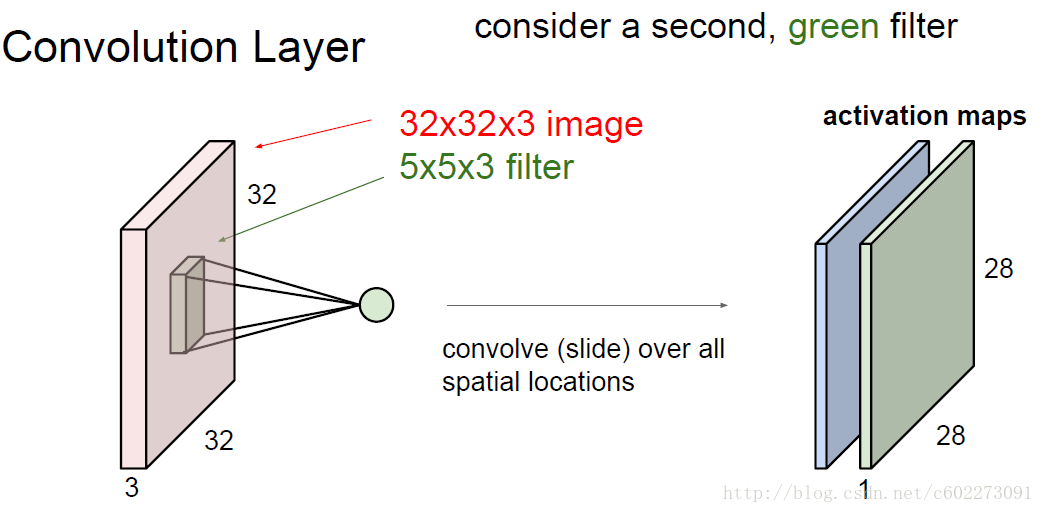
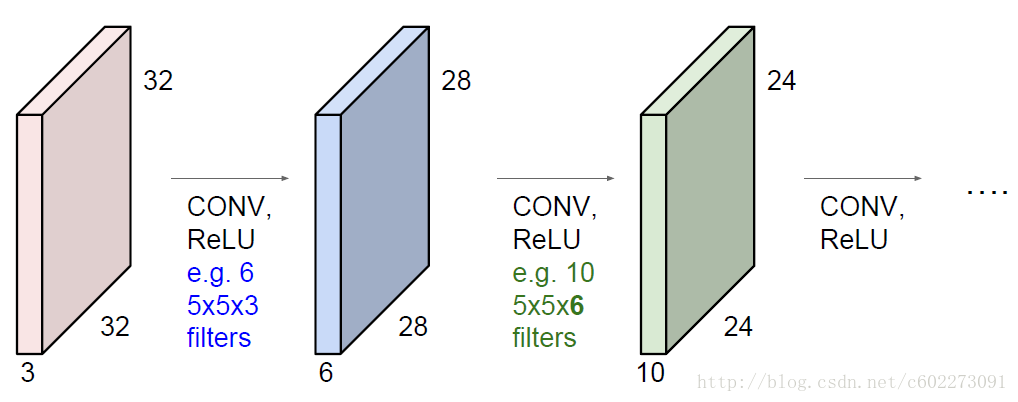
每个kenel的size是5x5,那么32x32,stride为1之后的map就是(32-5)/1+1。有的时候为了使size保持不变,会使用padding的技巧。
为什么把这个叫做卷积呢?是因为这里计算wx的时候就是用来图像上的卷积。


计算参数的个数的时候,这里可以看到一个区域采用的是一样的权值,这就是所谓的权值共享。所以有10个kernel的时候,就有(5x5x3+1)x10个参数。
对卷基层各个参数进行总结:

这里有一个叫做NiN的东西,就是kernel的size是1x1。
Pooling
池化就是做map的数据压缩。有max pooling、mean pooling等等。
可以看这个demo:
http://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html
各个神经网络介绍
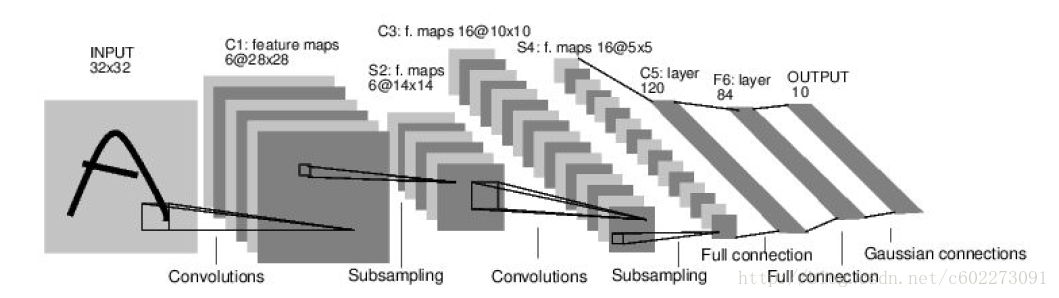
这个经典的神经网络应用于识别数字。
AlexNet:在12年ImageNet比赛上出尽风头的。
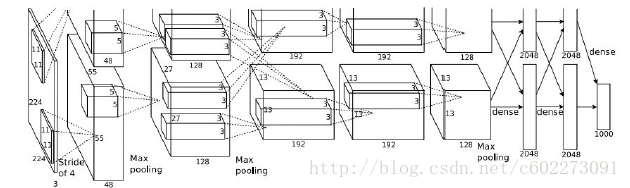

ZF net和alxe基本一样,除了map的数目不同。

VGGNet:vgg-16是目前最好的模型之一,当然没有resNet好。

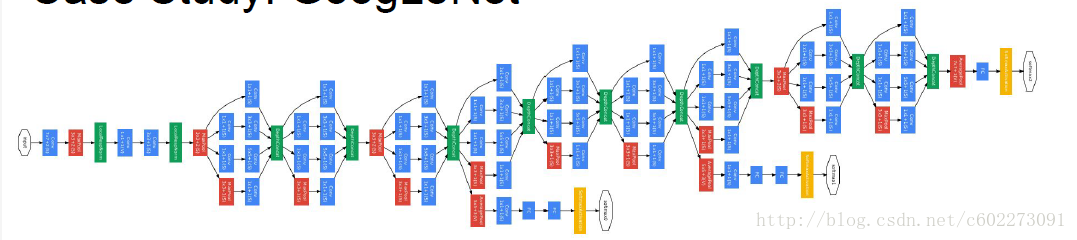
GoogleNet:增加了一个perception modul。
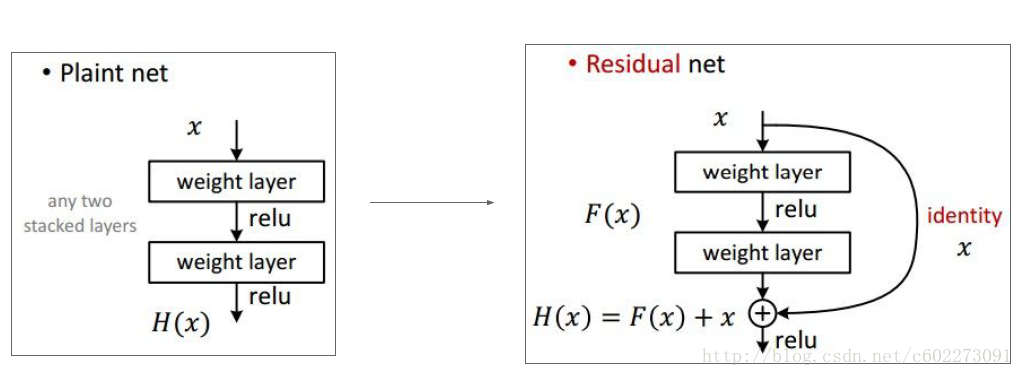
ResNet: 在前向网络的时候,增加了残差。
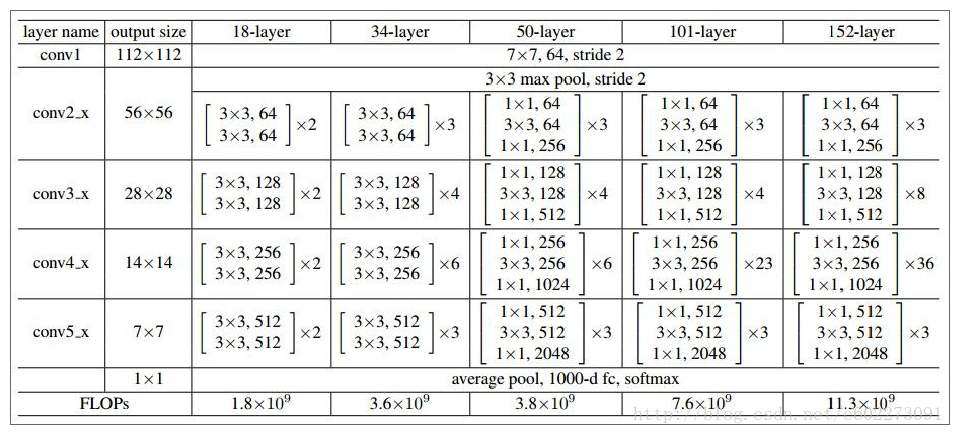
PS:截图来自于Standford cs231n的ppt。
网址是:http://cs231n.stanford.edu/syllabus.html
不得不说,这门课讲得太好了~ 完美~















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









