







 本文深入探讨了Word2Vec,包括其诞生背景、NLP的重要性、自监督学习的概念,以及CBOW和Skip-gram模型的区别。文章通过分析论文和源代码,解释了词向量表示的改进,如Negative Sampling,以及词组嵌入的重要性。同时,文章讨论了词类比任务和词嵌入的评价方法,揭示了词嵌入空间中蕴含的句法和语义规律。
本文深入探讨了Word2Vec,包括其诞生背景、NLP的重要性、自监督学习的概念,以及CBOW和Skip-gram模型的区别。文章通过分析论文和源代码,解释了词向量表示的改进,如Negative Sampling,以及词组嵌入的重要性。同时,文章讨论了词类比任务和词嵌入的评价方法,揭示了词嵌入空间中蕴含的句法和语义规律。

关于作者:张正,坐标巴黎,上班NLP,下班词嵌入。
都已经 2020 年了,还在介绍 word2vec?
对。词嵌入(word embeddings)向前可以追溯到上世纪 50 年代(虽然那时还不叫这个名字,但语义如何被表征的假说已经提出了),向后更是随着一个个芝麻街成员的强势加入,恨不得天天都是该领域的新 SOTA。所以不如找个中间的里程碑 word2vec 先挖一坑,毕竟想那么多,都没做来得实际。
当然,网上关于 word2vec 的优秀讲解已经非常多了,这里只希望努力讲出些之前没被注意到但实际又可能值得关注的点;也尽力不局限于当年,试着以 2020 年的角度去回看。
介绍分为三个部分,分别对应 Tomas Mikolov(托老师)2013 年经典的托三篇:
1. word2vec(一):NLP 蛋糕的一大块儿:围绕 Efficient Estimation of Word Representations in Vector Space。会谈到:word2vec 与自监督学习;CBOW 与 Skip-gram 的真正区别是什么。
2. word2vec(二):面试!考点!都在这里:围绕 Distributed Representations of Words and Phrases and their Compositionality。会谈到:真正让 word2vec 被广泛应用的延伸与改进。
3. word2vec(三):当我谈词嵌入时我谈些什么:围绕 Linguistic Regularities in Continuous Space Word Representations。会谈到:词嵌入的评价(evaluation),尤其是词类比(word analogy)任务。
那么,我们正式开始。

NLP蛋糕的一大块儿
1.1 杨老师蛋糕
为了进一步合理化从 word2vec 谈起这个选择,我搬出了杨老师(没错,就是 Yann Le Cun 的“杨”)蛋糕 2.0 版。“众所周知”,杨老师在 NIPS 2016 端出了他的人工智能大蛋糕,并在 2019 年升级配方,有了我们现在的 2.0 版。
简单介绍一下这款蛋糕。杨老师说:“如果智能是一个蛋糕,那么蛋糕的大部分是无监督学习,蛋糕的糖衣是有监督学习,而蛋糕上的樱桃是强化学习。”

▲ 杨老师蛋糕 1.0
这一说法强调了无监督学习的重要性,但“无监督”本身是一个很玄乎的词,真的是字面意义上的一点监督都没有吗?为了明确这一点,蛋糕 2.0 版对“无监督”作了替换:
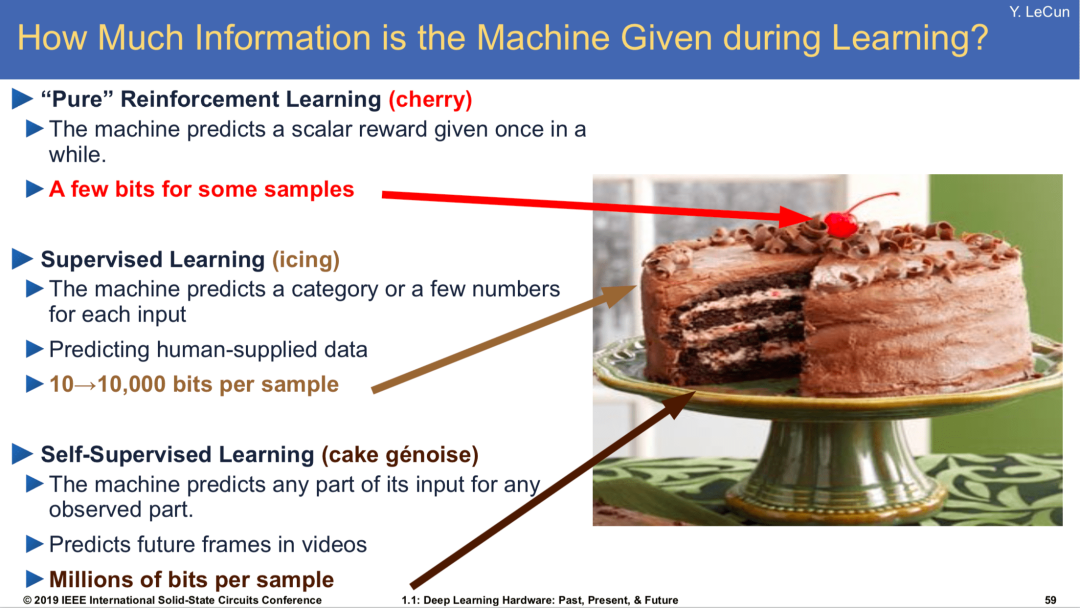
▲ 杨老师蛋糕2.0
可以看到,“无监督”被替换成了“自监督”。杨老师也亲自在一个神秘的网站上作了一番解释:

“自监督”显然比“无监督”更准确:不是没有监督,而是“系统基于输入的一部分去学着预测另一部分”。相比于有监督学习通常需要人工标注,自监督学习显得更加“自给自足”。
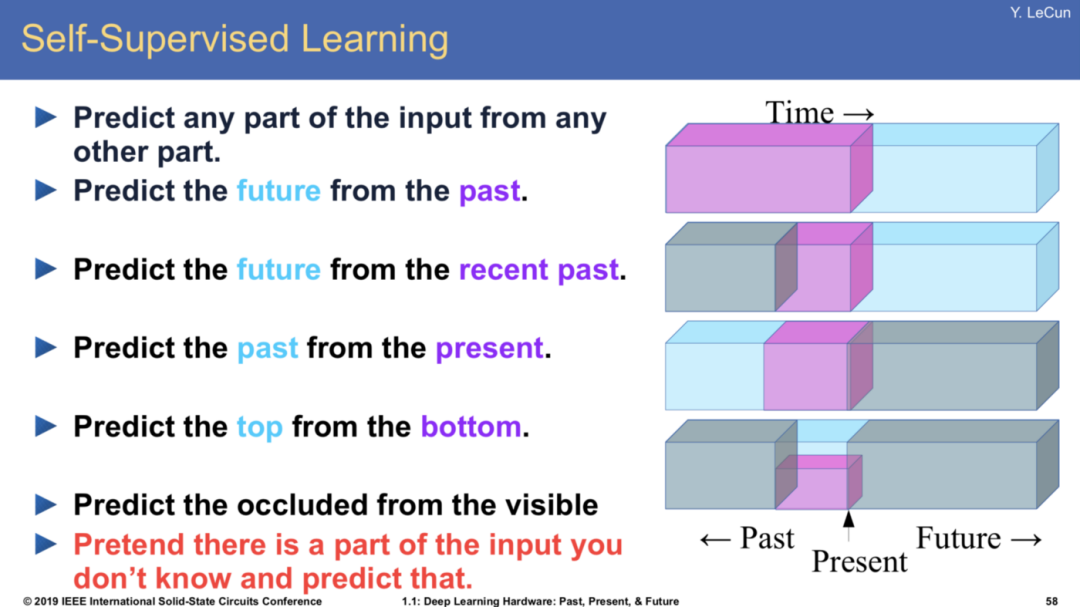
▲ 自监督如何“自给自足”
这可能也是自然语言处理(NLP)相较于其他领域(如机器视觉 CV)在本次人工智能浪潮里的独特之处:这一次,NLP 一开始就把技能点到了自监督学习的科技树上。而 word2vec 无疑是此科技树上一早期重要技能。(终于又绕回到 word2vec 了。)
1.2 假装读过论文 之 word2vec的诞生
如果你去面试 NLP 相关职位,被问到 word2vec 一定不应该感到意外。解释 word2vec 的好博客、好视频真的很多。但是最传统(最硬核?)的方法还是读论文。以下我们通过 Abstract 梳理相关论文,顺带提一些或“众所周知”、或奇怪的知识点。
论文标题:Efficient Estimation of Word Representations in Vector Space
论文链接:https://arxiv.org/abs/1301.3781
“我们提出两种新的用于基于非常大的数据集来计算词的连续向量表征的模型架构。(我们)通过词相似度任务来衡量这些(向量)表征的质量,并将其结果和基于不同神经网络类型并获得之前最好结果的模型做比较。
我们发现(我们的模型)在准确度上(相较于其他)有了大的提升并且是以更小的计算量为代价。即它从一个 16 亿词的数据集上训练出高质量的词向量只花了不到一天的时间。此外,我们还证明了这些(词)向量在我们(自己的)用来衡量词在句法和语义相似度的测试集上获得了史上最佳结果。”
作者托老师(没错,就是 Tomas Mikolov 的“托”)在 2013 年非常高产,该文章是关于 word2vec 的第一篇,但不是其关于词嵌入研究的第一篇。
在此之前还有 Linguistic Regularities in Continuous Space Word Representations, 著名的“国王-男人+女人约等于女王”就出自这里(后来根据此类比任务延伸出的关于 bias 研究非常多,出发点是好的,但不少文章其实是无病呻吟,后来统一被另一文章彻底打脸,我们在 word2vec(三)中会具体聊到)。
回到这篇文章,托老师之所以研究新的词嵌入训练模型是因为他发现此前没有方法可以成功地在大文本数据集上训练出维度在 50 到 100 之间的词向量。因此,他出手了:他要提出一种新的模型,不仅在传统词相似度任务上效果好,还在他自己提出的词类比任务上效果好。
新模型 word2vec 受到之前 NNLM 的启发和影响(Neural Network Language Model,神经网络语言模型)但是更简单,省掉了 NNLM 中非线性的隐含层。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2418
2418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









