







推荐系统冷启动通常分为三类,即用户冷启动、物品冷启动还有系统冷启动。无论那种冷启动都因为只有较少的数据和特征来训练模型,所有需要不同的技术方案来提升推荐效果。另外冷启动结合产品方案可以加速冷启动的过程。
其中用户冷启动的问题对于移动互联网基于内容推荐产品中非常重要,不管是新产品还是体量很大的产品,都存在大量新用户和低活用户,即冷启动用户。这部分用户是 DAU 增长的关键点,但这些用户交互数据很少甚至没有,如何快速找到这部分用户的兴趣,是用推荐系统需要解决的关键问题。
快手和中科大发表在 TOIS (ACM Transactions on Information Systems) 上的最新工作提出融合物品(视频)和属性的统一框架,用汤普森采样结合对话式的方法为冷启动用户做推荐。对话式推荐能够通过向用户提问来快速获得用户兴趣,而汤普森采样能够保持探索-利用的平衡,这两点均有助于系统尽快地探索到冷启动用户的兴趣并利用已有知识进行推荐。

论文标题:
Seamlessly Unifying Attributes and Items: Conversational Recommendation for Cold-Start Users
论文链接:
https://arxiv.org/abs/2005.12979
本文着重研究两个关键点:
1. 如何做到探索-利用的平衡。在推荐系统中,探索(Exploration)是指去主动寻找未知的用户潜在的兴趣;利用(Exploitation)是指根据已有的经验去估计用户当前的兴趣并做出推荐。由于缺乏用户行为历史数据,在为冷启动用户做推荐时保持探索和利用的平衡尤为重要——我们既要尽快探索用户对不同商品的兴趣,又要尽可能利用当前已经获得的知识来做出合适的推荐。这样才能尽可能吸引新用户和低活用户,并提高留存率。
2. 对话式推荐方法。对话式推荐在推荐系统领域近来得到广泛的关注。对话式推荐系统中的“对话”模块能够直接向用户提问,并期望通过用户的回答显式地获得用户的兴趣。提问的形式可以多种多样,本文考虑对物品的属性进行提问。例如,在快手短视频推荐的场景中,新用户的应用主界面会收到一个弹窗。
弹窗中列举了一系列短视频类型(属性标签),并引导用户去选择自己喜欢的视频类型。相比于间接地从历史交互数据中进行推断,这些主动选择的属性标签可以为推荐系统提供更准确,更直接的用户兴趣信息,并帮助提供更好的推荐。在对话式推荐中,主要有三个核心的策略问题:(1)问什么问题;(2)推荐什么物品;(3)当前是问问题还是做推荐。

方法介绍
文章提出了一个统一的框架 ConTS,把物品和属性建模到一个空间中,利用改进的汤普森采样算法 [1] 保持探索和利用的平衡,并使用一个统一的打分函数来统一解决对话式推荐中的三个核心问题。
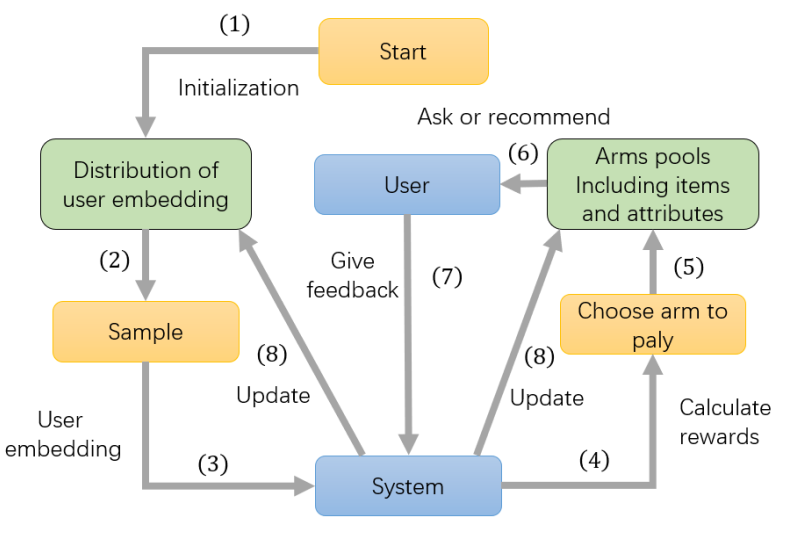
具体来说,文章研究用户和推荐系统间的多轮对话推荐场景。首先用非冷启动用户的历史交互数据去分布训练一个 FM 模型,得到所有历史用户,物品和属性的 embedding 并为冷启动用户做参数初始化。
在每轮对话开始之前,首先从一个多维高斯分布中进行采样得到用户当前的 embedding,利用得到的 embedding 和用户当前已知喜欢的属性对所有物品和属性进行打分。
如果得分最高的是物品,就向用户推荐分数最高的前 k 个物品;如果得分最高的是属性,就向用户询问对于这个属性的喜好。如果用户拒绝了推荐的物品或者提问的属性,在把拒绝的物品(属性)从候选池中剔除后继续对话过程。
如果用户接受了推荐的物品,代表推荐成功并结束对话。如果用户喜欢提问的属性,那么记录下该属性,并把当前候选池中所有不含有该属性标签的物品剔除。此外,如果在超过一个最大对话轮数(如 15 轮)用户还未获得满意的推荐,认为用户会失去耐心并直接退出当前对话。
本文把对话式推荐中所有的物品和属性进行统一建模,用一个相同的打分函数来决定所有的策略问题。实验证明,这种统一建模的方式相比之前一些手动设置对话策略的工作(如 ConUCB [2])更加智能和鲁棒。此外,我们在打分函数中引入了对用户喜欢的属性信息的建模,使得模型能够更好地利用用在对话过程中直接获得的用户兴趣。
下面的式子就是我们的打分函数,其中 是采样得到的用户 embedding, 是物品/属性的 embedding, 是在对话中获得的用户喜欢的属性集合, 是这些属性的 embedding。

每轮推荐或者提问之后,会根据用户的反馈更新用户 embedding 服从的高斯分布的参数,具体更新方式如下:
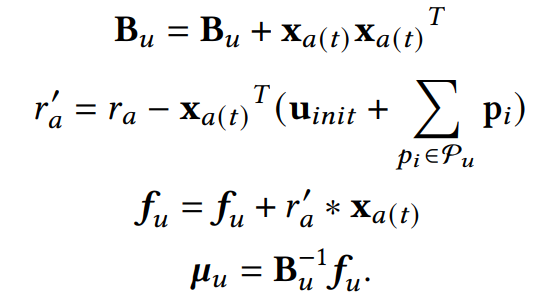
文章把汤普森采样运用在对话式推荐中,并更具加入的初始化过程和用户喜欢属性信息建模调整了参数的更新方式。汤普森采样是一种经典的 Bandit 算法,目的是在推荐过程中保持探索-利用的平衡,使得在一定时间内的收益损失有一个理论的上界。
在这里假设用户的 embedding 服从一个多维高斯分布 ,并不断利用用户反馈更新其均值 和协方差 。

实验效果
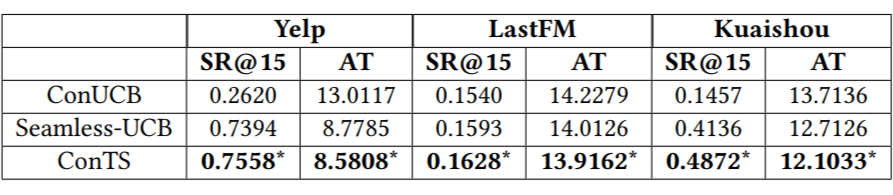
文章在两个经典数据集 Yelp,LastFM 和一个从快手平台上收集的数据集 Kuaishou 上进行了详尽的实验。首先把 ConTS 和几个现有方法做比较,并进行了消融实验。结果如下:
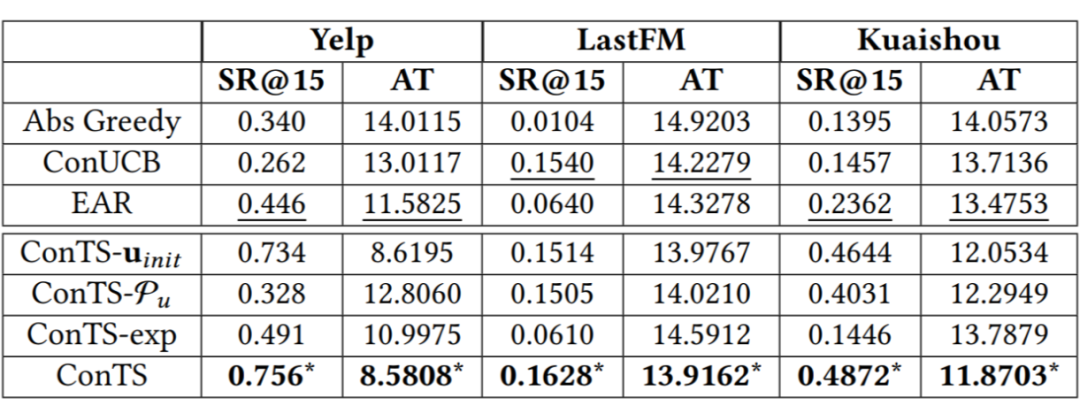
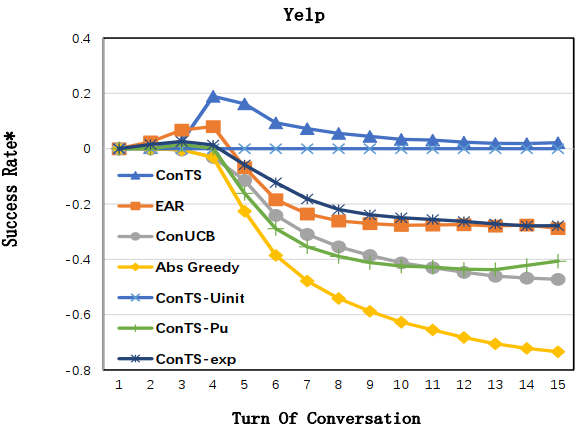
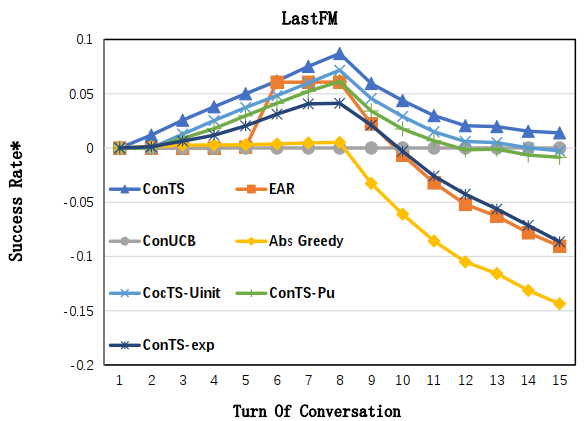
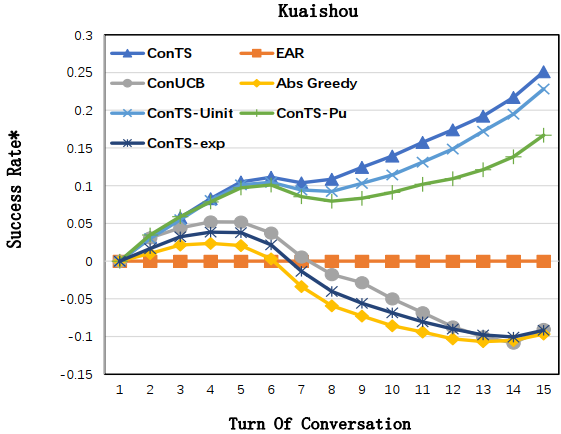
表格中比较的是 15 轮的推荐成功率和平均推荐成功轮数,图中展示的 1-15 轮的推荐成功率的相对差值。可以看到在每个指标上 ConTS 都显著优于已有的方法。三个消融实验分别去掉了模型中初始化,用户喜欢属性建模和探索模块,结果验证了这些设计对模型表现的重要性。
此外,我们还探究了不同的 Bandit 方法——汤普森采样和上置信界算法对我们模型的影响。我们用同样的方式把上置信界算法进行改进以适应对话式推荐场景,并于 ConTS 进行比较,结果如下:
可以看到汤普森采样在我们的场景下表现更好。文章还研究了在最大对话轮数更小(7 和 10)下的情况,ConTS 仍然显著优于其他方法;探究了在不同程度冷启动条件下模型之间的差异,结果表明 ConTS 适合冷启动场景而其他一些方法如 EAR [3] 适合热启动场景。最后用三个案例分析探究了不同方法在实际对话过程中的策略差异。

结论
如何为冷启动用户做推荐是学术界和工业界研究的热点问题之一。这篇论文利用对话式推荐结合汤普森采样的方式,提出了一个融合物品和属性的统一模型来解决该问题。在保持探索-利用平衡的同时,用对话的方式直接快速地获得用户的兴趣,以此帮助系统更好地为冷启动用户进行推荐。实验结果表明,该模型相对现有方法具有较大优势。
参考文献
[1] Shipra Agrawal and Navin Goyal. 2013. Thompson sampling for contextual bandits with linear payoffs. In ICML.127–135.
[2] Xiaoying Zhang, Hong Xie, Hang Li, and John Lui. 2020. Conversational Contextual Bandit: Algorithm and Application.In WWW.
[3] Wenqiang Lei, Xiangnan He, Yisong Miao, Qingyun Wu, Richang Hong, Min-Yen Kan, and Tat-Seng Chua. 2020.Estimation–Action–Reflection: Towards Deep Interaction Between Conversational and Recommender Systems. InWSDM.
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









