








©PaperWeekly 原创 · 作者|苏剑林
单位|追一科技
研究方向|NLP、神经网络
大家最近应该多多少少都被各种 MLP 相关的工作“席卷眼球”了。以 Google 为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer 模型,其中势头最猛的就是号称是纯 MLP 的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起来盘点一些最近的相关工作。

五月人倍忙
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非 Transformer 的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在 Arxiv 上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了 NLP 和 CV 等多个任务,真的让人应接不暇:
[1] MLP-Mixer: An all-MLP Architecture for Vision - Google Research
[2] Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks - 清华大学
[3] Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet - 牛津大学
[4] Are Pre-trained Convolutions Better than Pre-trained Transformers? - Google Research
[5] ResMLP: Feedforward networks for image classification with data-efficient training - Facebook AI
[6] FNet: Mixing Tokens with Fourier Transforms - Google Research
[7] Pay Attention to MLPs - Google Research
以上论文是按照出现在 arixv 上的时间排序的。可以看到主力军依旧是 Google 大佬。想当年一手促成了“Attention is all you need”趋势的也是 Google,现在“重拳出击”Transformer 的还是 Google,Google 大佬真可谓一直挖坑不断啊。

把酒话桑麻
那么这系列工作究竟能带来什么启发呢?我们要不要赶紧跟上这系列工作呢?在这部分内容中,我们就来简要地梳理一下上述几篇论文,看看它们是何方神圣,是否有可能造成新一股模型潮流?
2.1 Synthesizer
要解读上述 MLP 相关的工作,就不得不提到去年五月 Google 发表在《Synthesizer: Rethinking Self-Attention in Transformer Models》[1] 的 Synthesizer。而事实上,如果你已经了解了 Synthesizer,那么上面列表中的好几篇论文都可以一笔带过了。
在之前的文章 Google 新作 Synthesizer:我们还不够了解自注意力中,我们已经对 Synthesizer 做了简单的解读。撇开缩放因子不说,那么 Attention 的运算可以分解为:

其中 是输入序列的变换,这个了解 Self Attention 的读者应该都清楚,不再详写。Synthesizer 则是对几种 的新算法做了实验,其中最让人深刻的一种名为 Random,就是将整个 当作一个参数矩阵(随机初始化后更新或者不更新)。

在 Random 的情况下,Attention 矩阵不再是随样本变化的了,也就是所有样本公用同一个 Attention 矩阵,但是它依然能取得不错的效果,这在当时确实对大家对 Attention 的固有理解造成了强烈冲击。Synthesizer 的实验相当丰富,包括“机器翻译”、“自动摘要”、“对话生成”、“预训练+微调”等,可以说,上面列罗的多数论文,实验都没有 Synthesizer 丰富。
2.2 MLP-Mixer

论文标题:
MLP-Mixer: An all-MLP Architecture for Vision
论文链接:
https://arxiv.org/abs/2105.01601
Synthesizer 也许没想到,一年之后,它换了个名字,然后火起来了。
论文《MLP-Mixer: An all-MLP Architecture for Vision》所提出来的 MLP-Mxier,其实就是 Synthesizer 的 Random 模式并去掉了 softmax 激活,也就是说,它将 设为可训练的参数矩阵,然后直接让 。模型就这样已经介绍完了,除此之外的区别就是 MLP-Mxier 做 CV 任务而 Synthesizer 做 NLP 任务而已。
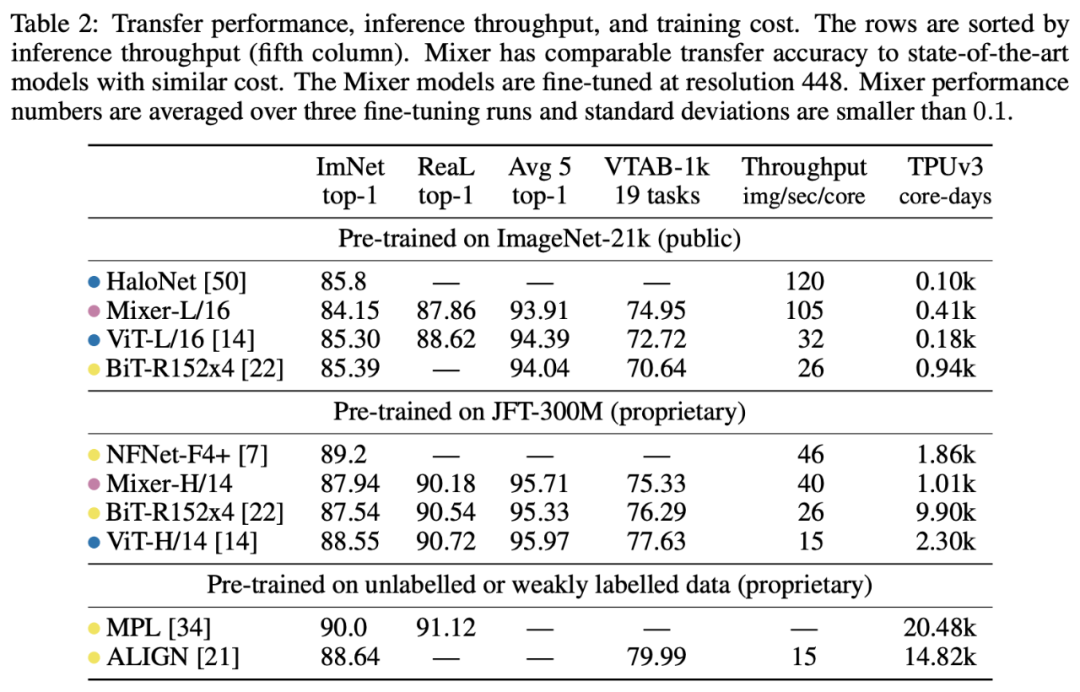 ▲ MLP-Mixer的部分实验结果
▲ MLP-Mixer的部分实验结果
对了,为啥这模型叫 MLP-Mxier 呢,因为作者把这种直接可训练的 Attention 模式起了个名字叫做“token-mixing MLP”ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2286
2286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









