








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
在文章《生成扩散模型漫谈:DDPM = 拆楼 + 建楼》中,我们为生成扩散模型 DDPM 构建了“拆楼-建楼”的通俗类比,并且借助该类比完整地推导了生成扩散模型 DDPM 的理论形式。在该文章中,我们还指出 DDPM 本质上已经不是传统的扩散模型了,它更多的是一个变分自编码器 VAE,实际上 DDPM 的原论文中也是将它按照 VAE 的思路进行推导的。
所以,本文就从 VAE 的角度来重新介绍一版 DDPM,同时分享一下自己的 Keras 实现代码和实践经验。

多步突破
在传统的 VAE 中,编码过程和生成过程都是一步到位的:

这样做就只涉及到三个分布:编码分布 、生成分布 以及先验分布 ,它的好处是形式比较简单, 与 之间的映射关系也比较确定,因此可以同时得到编码模型和生成模型,实现隐变量编辑等需求;但是它的缺点也很明显,因为我们建模概率分布的能力有限,这三个分布都只能建模为正态分布,这限制了模型的表达能力,最终通常得到偏模糊的生成结果。
为了突破这个限制,DDPM 将编码过程和生成过程分解为 步:
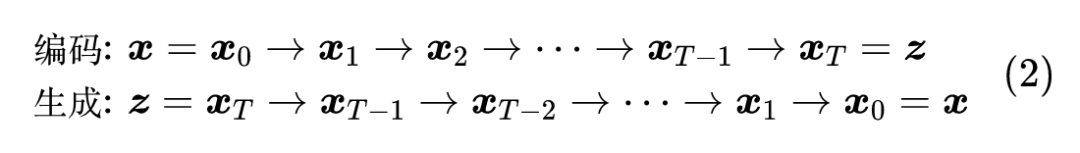
这样一来,每一个 和 仅仅负责建模一个微小变化,它们依然建模为正态分布。可能读着就想问了:那既然同样是正态分布,为什么分解为多步会比单步要好?这是因为对于微小变化来说,可以用正态分布足够近似地建模,类似于曲线在小范围内可以用直线近似,多步分解就有点像用分段线性函数拟合复杂曲线,因此理论上可以突破传统单步 VAE 的拟合能力限制。

联合散度
所以,现在的计划就是通过递归式分解(2)来增强传统 VAE 的能力,每一步编码过程被建模成 ,每一步生成过程则被建模成 ,相应的联合分布就是:
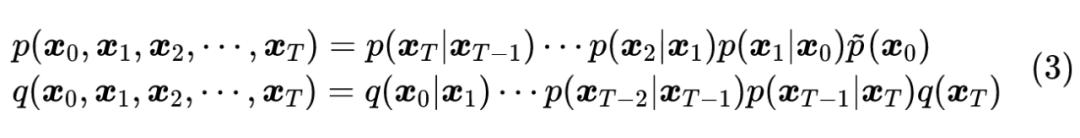
别忘了 代表真实样本,所以 就是数据分布;而 代表着最终的编码,所以 就是先验分布;剩下的 、 就代表着编码、生成的一小步。(提示:经过考虑,这里还是沿用本网站介绍 VAE 一直用的记号习惯,即“编码分布用 、生成分布用 ”,所以这里的 、 含义跟 DDPM 论文是刚好相反的,望读者知悉。)
在《变分自编码器(二):从贝叶斯观点出发》中笔者就提出,理解 VAE 的最简洁的理论途径,就是将其理解为在最小化联合分布的 KL 散度,对于 DDPM 也是如此,上面我们已经写出了两个联合分布,所以 DDPM 的目的就是最小化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2494
2494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









