







 本文概述了ICML 2022中关于域泛化的最新研究进展,重点介绍了DNA、MAPLE、SparseIRM和SDAT四个方法。DNA提出了一种多样化神经平均方法,通过PJS损失来提高模型泛化能力。MAPLE通过样本重加权策略改善OOD泛化性能,而SparseIRM则引入稀疏性约束以解决IRM在大模型中的失效问题。SDAT则从平滑性角度优化域对抗训练,提高目标域上的泛化效果。这些研究为域泛化和迁移学习提供了新的理论与实践见解。
本文概述了ICML 2022中关于域泛化的最新研究进展,重点介绍了DNA、MAPLE、SparseIRM和SDAT四个方法。DNA提出了一种多样化神经平均方法,通过PJS损失来提高模型泛化能力。MAPLE通过样本重加权策略改善OOD泛化性能,而SparseIRM则引入稀疏性约束以解决IRM在大模型中的失效问题。SDAT则从平滑性角度优化域对抗训练,提高目标域上的泛化效果。这些研究为域泛化和迁移学习提供了新的理论与实践见解。

©PaperWeekly 原创 · 作者 | 张一帆
单位 | 中科院自动化所博士生
研究方向 | 计算机视觉
Domain Generalization(DG:域泛化)一直以来都是各大顶会的热门研究方向。DA 假设我们有多个个带标签的训练集(源域),这时候我们想让模型在另一个数据集上同样表现很好(目标域),但是在训练过程中根本不知道目标域是什么,这个时候如何提升模型泛化性呢?核心在于如何利用多个源域带来的丰富信息。ICML 2022 域泛化相关的文章来研究最新的进展。

DNA

论文标题:
DNA: Domain Generalization with Diversified Neural Averaging
论文链接:
https://proceedings.mlr.press/v162/chu22a.html
目前绝大多数 DG 方法都基于一个不切实际的假设,即训练时的 hypothesis space 包含一个最优分类器,因此源域与目标域的的联合损失可以降到最小。这个假设对神经网络来说是非常难以满足的。当对源数据进行训练时,分类器倾向于只记住所见训练数据的鉴别特征,而忘记任何其他信息,包括那些可能是 target domain 分类所需要的的信息。训练过程中目标数据的不可达性意味着深度分类器的假设空间倾向于支持低源域风险的子空间,而不一定支持低目标域风险的子空间。总之,理想分类器可能脱离训练阶段假设空间。
解决这个问题的一个方法是 classifier ensemble,即对分类器进行集成。本文从理论和实验角度讨论了 ensemble 与 DG 任务的 connection。
理论上,本文首先引入一个剪枝的 jensen - shannon(PJS)损失,证明了 ρ 集合(由 quasi-posteriorρ 加权的平均分类器)在目标域上的 PJS 损失受 Gibbs 分类器的在源域的平均平方根风险的限制,即前者被后者 bound。通过对分类器集合的多样性进行约束,得到了一个更紧密的 DG bound。根据这个 bound,本文提出了 diversified neural averaging(DNA)method。
接下来简单介绍该方法,首先本文引入的 PJS 损失如下:

这个损失是基于 PJS divergence 提出的。
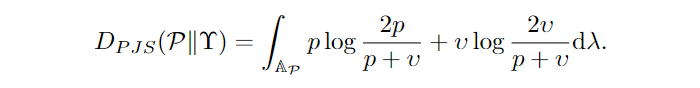
PJS 继承了 JS divergence 的优秀性质,比如三角不等式,除此之外,其次,PJS 的平方根对分类器而言具有凸性,这是原 JS 散度不具备的特性。本文提出的 bound 形式如下:
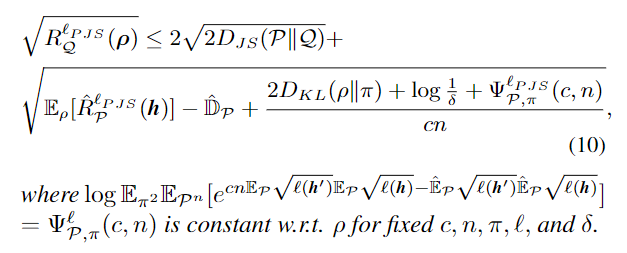
其中第一项源域与目标域 的 JS 散度是无法测量的,视作常数,最后一项也视作常数,最后模型的算法如下所示。与 ERM 的不同之处在于,这里会随机 sample 个分类器然后分别计算 PJS 损失,最后减去各个分类器 PJS 损失方差的平均作为正则约束。最后用作 inference 的模型会在每个训练阶段进行更新。

最终的实验结果如下所示,classifier ensemble 能带来相当不错的提升。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









