







神经网络使用梯度下降进行训练,通过梯度引导损失的优化,在多任务学习(multi-task learning,MTL)中,每个task有不同的损失函数,会导致梯度冲突,不同的task可能会使梯度指向相反的方向,通常处理冲突梯度的方法是对他们进行平均,但是研究表明[2],简单平均会降低模型性能。与MTL处理不同的任务不同,DG处理的是不同的域,所以,论文假设在多领域的训练中会出现类似的梯度冲突。
模型的总体损失函数式(1)是每个域的损失函数的和平均加上一个正则项。

每个域的相关联的梯度的各个分量的符号。
论文提出的方法是通过修改梯度的更新方式来使梯度指向同一个方向。给定一组梯度向量(每个域一个梯度),论文通过保留指向同一方向的梯度分量(即具有相同符号的分量)并修改冲突分量来构造一致性向量。文中定义了两种不同策略处理冲突梯度分量。
Agr-Sum策略:在模型训练时,mini-batch是以相同概率在所有源域中随机采样得到,为了防止不同类之间可能产生干扰,每个iteration中的样本来自同一类别(这个设置对训练的影响论文未说明)。经过网络前向计算,得到loss,通过反向传播得到相应的gradient。
gk(i)是第i个源域的相关梯度,Φ函数式(2)是检查梯度的符号是否一致。
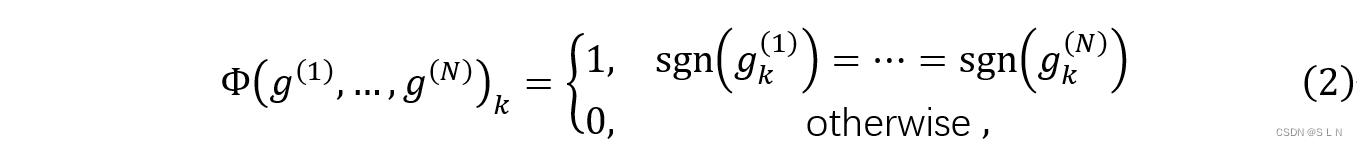
式(3)是来更新θ,在梯度分量有冲突时,设置梯度更新为0,避免域之间有害的梯度干扰。
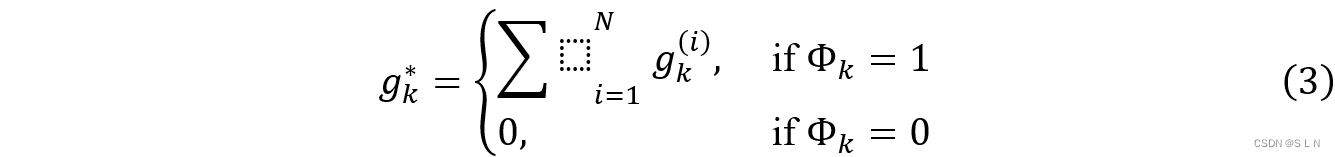
Agr-Rand策略:与Agr-Sum同样是通过函数Φ来检测梯度冲突。Agr-Sum设置为0可能会导致一些不会再改变的权重,与Agr-Sum中将冲突梯度设为0不同,Agr-Rand是从正态分布中采样一个随机值作为梯度。

σ2是由Φp = 1的g∗来决定,计算如式(5)。
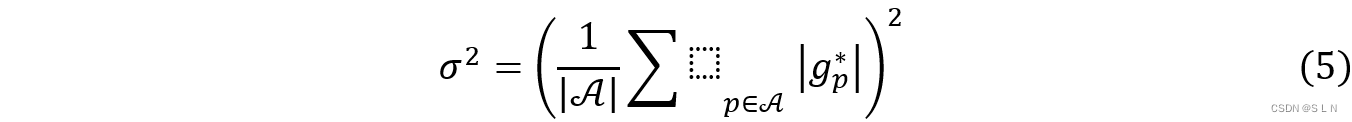















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









